
一道看似简单、实则考验AI常识推理能力的题目近日刷屏网络:「我想洗车,洗车店距离我家50米,你建议我开车去还是走路去?」
答案显而易见——洗车对象是「车」,人若步行前往,车辆仍停在家中,无法完成清洗。但测试发现,绝大多数AI模型在未启用深度思考模式时均给出错误结论:建议走路。
原因在于,模型默认将问题归类为「短途出行方式选择」,陷入时间、油耗、停车、环保等维度的冗余计算,却未切换主语——从「人怎么去」回归到「车怎么去」这一核心前提。
近期三大国产大模型集中升级:GLM-5正式发布、MiniMax M2.5开放内测、DeepSeek灰度上线百万级上下文。借此契机,我们对10个主流模型开展横向测试,覆盖「快速模式」与「深度思考模式」共19次响应。
结果仅4次答对,全部出自深度思考模式;快速模式0次正确。
测试结果概览
答对的模型(4例)
ChatGPT 5.2开启Thinking后明确指出:「你需要把车交给店里,车必须在场才能被清洗」;关闭后则建议走路,理由是「别把简单事搞复杂」。
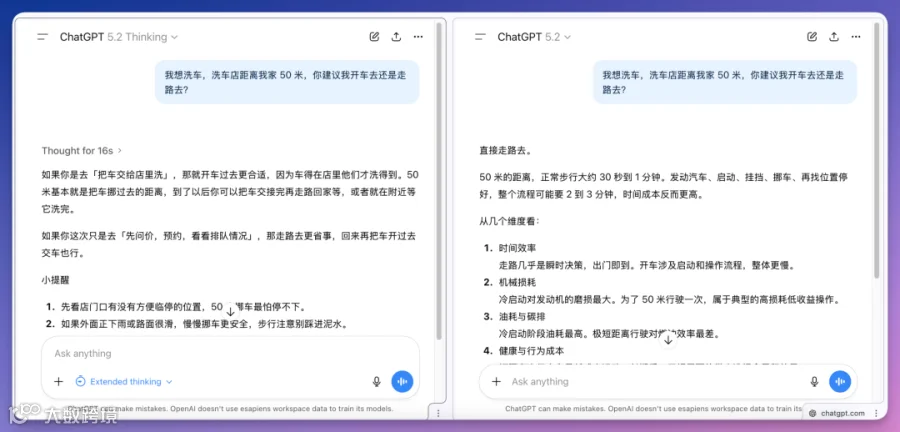
Gemini 3 Pro作为原生推理模型,无需开关设置,直接回应:「建议开车去,因为洗车店洗的是车,不是人;走路去的话车还在家里」,逻辑清晰,响应高效。
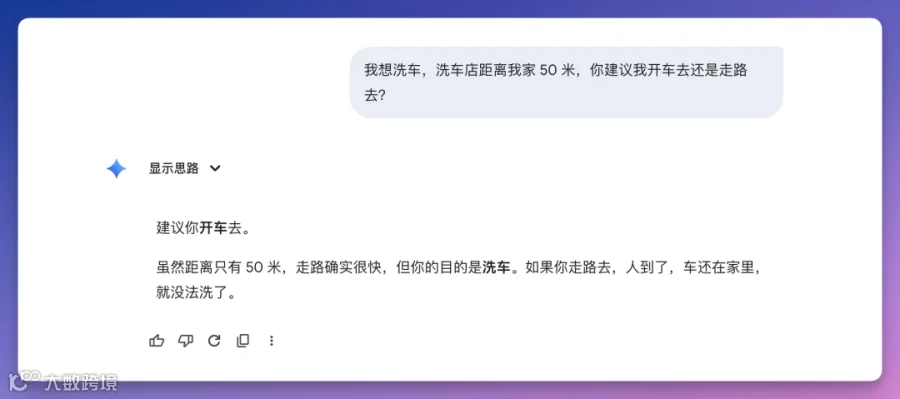
GLM-5在深度思考模式下给出最完整方案:「开车送车,交由店员清洗;随后步行回家,洗完再步行取车」,并点明关键:「洗车店员工不能洗空气」。
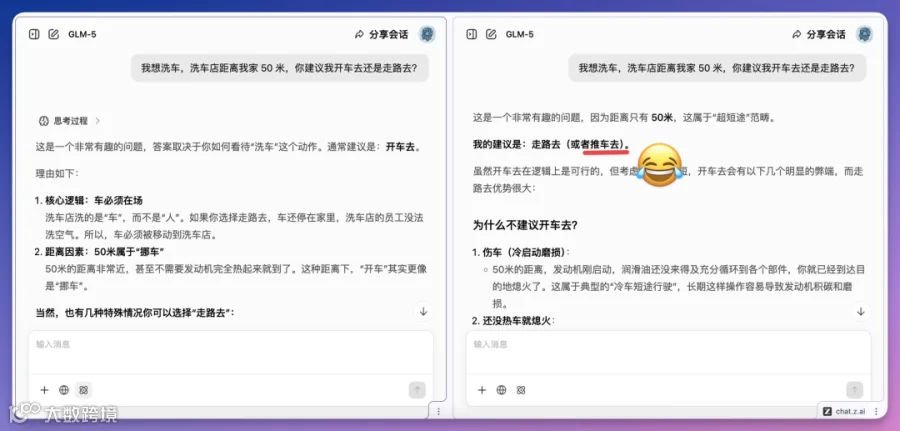
Grok 4.1在深度思考下亦准确切中本质:「开车去,因为你要洗的是车,不是自己」;而快速模式却以五维表格详细论证「走路更优」,反显逻辑错位。
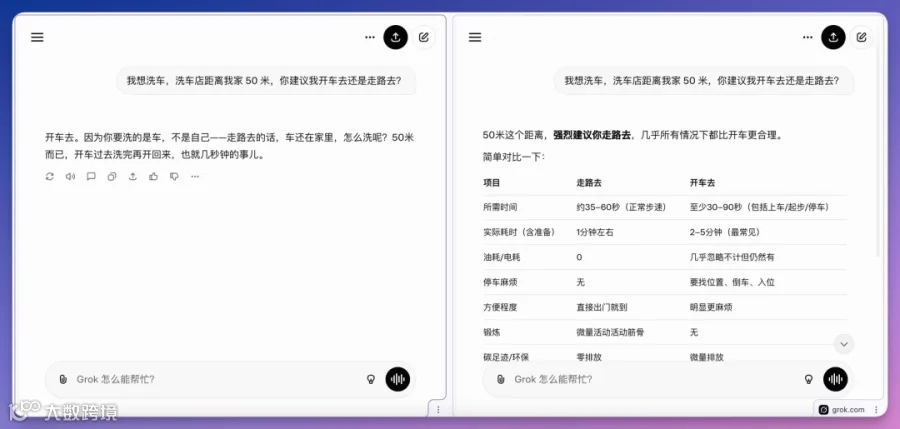
其余模型全部答错
Claude Opus 4.6在常规与Extended Thinking模式下均坚持「走路去,50米只需一分钟」,未识别任务主体偏差。
DeepSeek 1M两模式均建议走路,甚至提出「开脏车去洗车店如同洗澡前先出一身汗」的牵强类比,脱离现实语义。
MiniMax M2.5(Air/Max双版本)均推荐走路,Max版更以序号列表呈现严谨格式,内容却全然偏离目标。
豆包两次回答均未意识到车辆必须到场:快速模式称「车停家里,等下洗好我来开」;深度思考模式简化为「50米也就几十步路」。
Kimi K2.5区分天气条件给出策略,却未触及「车需到场」本质;通义千问 Qwen3-Max甚至提出「开脏车去洗车店可能弄脏刚清洁的车内环境」,陷入自我矛盾。
10模型19次测试结果汇总
| 模型 | 快速模式 | 深度思考 |
|---|---|---|
ChatGPT 5.2 |
❌ 走路 | ✅ 开车 |
Gemini 3 Pro |
— | ✅ 开车 |
GLM-5 |
❌ 走路 | ✅ 开车 |
Grok 4.1 |
❌ 走路 | ✅ 开车 |
Claude Opus 4.6 |
❌ 走路 | ❌ 走路 |
DeepSeek 1M |
❌ 走路 | ❌ 走路 |
MiniMax M2.5 |
❌ 走路 | ❌ 走路 |
豆包 |
❌ 走路 | ❌ 走路 |
Kimi K2.5 |
❌ 走路 | ❌ 走路 |
通义千问 |
❌ 走路 | ❌ 走路 |
Gemini 3 Pro为纯推理模型,仅一次测试记录。
问题本质:主语切换与框架偏差
AI并非缺乏「洗车需车在场」这一常识,而是在推理过程中未能主动调用该前提。多数模型将问题锚定于「人的出行效率」框架,忽略动作对象(车)才是服务主体。
答对模型的关键共性在于完成一次主语转换:从「人如何抵达」转向「车如何到场」。例如Grok强调「你要洗的是车,不是自己」,GLM-5直指「洗车店员工没法洗空气」。
深度思考模式的更高正确率,并非源于算力或参数优势,而是因其多出的推理步骤提供了跳出默认框架、重新校准问题本质的机会;快速模式则直接跳向结论,失去纠偏窗口。
提示词设计仍至关重要
同一模型因提问方式不同,输出可能截然相反。原题「你建议我开车去还是走路去」本身即隐含误导——将两个不等价选项并列,强化了「人出发方式」的认知惯性。
所谓「提示词工程已死」的论调,在此案例中被证伪。精准的指令设计,仍是激活模型潜在能力的关键杠杆。
50米很近,但从「人怎么去」到「车怎么去」,对当前AI而言,仍是需要刻意跨越的认知鸿沟。