
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
开源模型热度持续攀升,Kimi K2.5近期登顶Hugging Face趋势榜首位,下载量突破5.3万次。
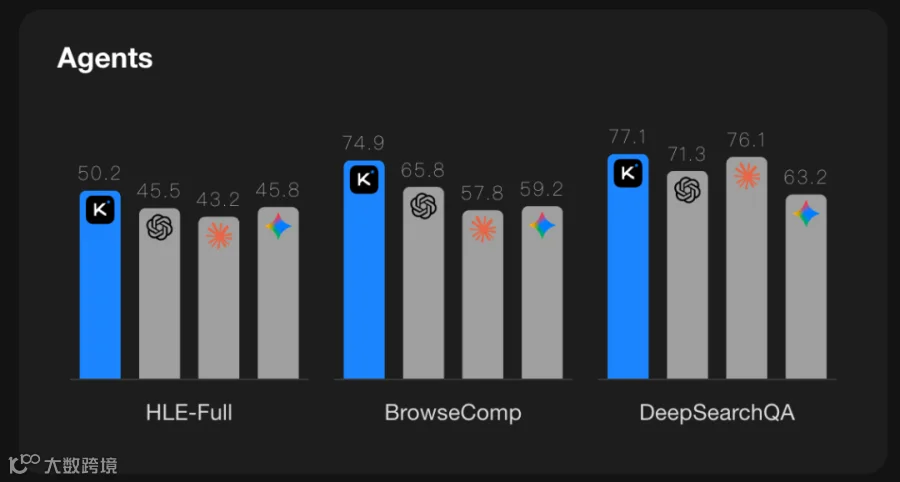
Kimi K2.5主打Agent能力,在HLE-Full、BrowseComp等多项测试中表现优于GPT-5.2、Claude 4.5 Opus及Gemini 3 Pro等主流闭源模型。
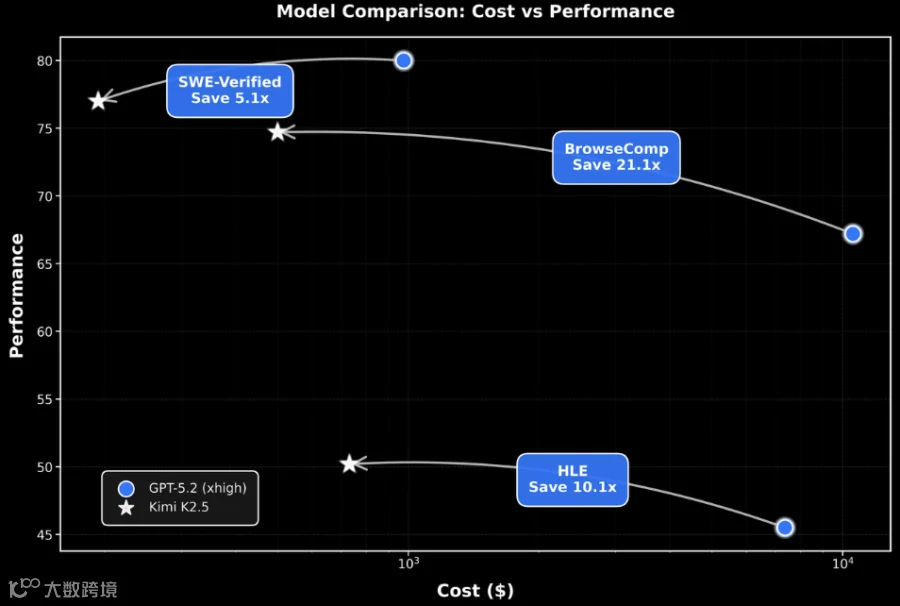
在性能与成本方面,Kimi K2.5展现出显著优势:其在BrowseComp上的表现超越GPT-5.2的同时,计算资源消耗不足后者的5%。
随着官方技术报告发布,Kimi K2.5的技术架构也逐步揭晓。
原生多模态,15T Token混合训练
Kimi K2.5基于K2架构,采用15万亿(15T)视觉与文本混合Token进行持续预训练,走的是“原生多模态”路线——即同一套参数空间直接处理图像与文本信息。
该设计实现了视觉理解与语言推理的同步增强,避免了传统模型中二者相互削弱的问题。模型能像解析语法一样理解像素背后的语义逻辑,从而支持“视觉编程”能力。
面对包含复杂滚动特效或动态交互的网页演示视频,K2.5可直接从视频流中逆向生成前端代码,精准捕捉元素随时间变化的规律,并映射为可执行代码。
这一过程跳过“视觉→文本→代码”的中间转换环节,实现从设计到开发的无损传递,大幅提升开发效率。
为确保生成代码的视觉还原度,K2.5内置自主视觉调试机制。在页面渲染后,模型通过视觉感知对比实际效果,若发现布局错位、样式偏差或动画异常,将自动调用文档查询工具定位问题并修正代码。
这种“生成-观察-查阅-修复”的闭环流程,模拟高级工程师的调试行为,使模型具备端到端完成软件工程任务的能力。
超大规模“智能体集群”
为应对复杂任务处理需求,Kimi K2.5引入Agent Swarm架构,支持构建百人规模的数字化团队。
系统可瞬间创建并调度多达100个子智能体,协同调用超过1500种工具,形成高度并行的工作流,显著缩短全网搜索、数据分析等耗时任务的响应周期。

该集群由PARL(并行智能体强化学习)框架驱动,构建起“调度器+执行层”的指挥体系。
调度器负责任务拆解与资源分配,子智能体则专注于具体指令执行,参数冻结确保执行稳定性。动静结合的设计兼顾系统灵活性与逻辑严密性。
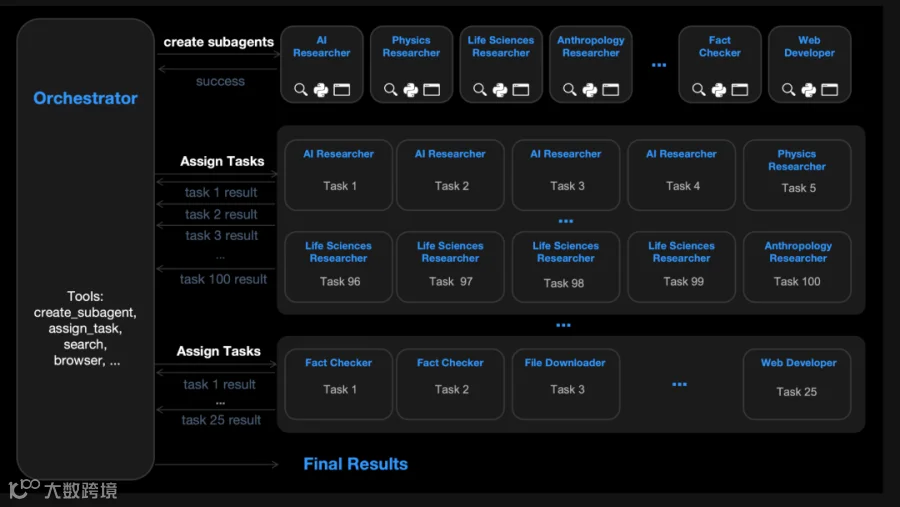
训练过程中采用阶段性奖励策略:初期鼓励调度器探索并行化路径,后期侧重任务最终成功率,引导模型建立“在保证准确性的前提下最大化并发效率”的决策习惯。
评估指标聚焦“临界步骤”,依据关键路径原理,关注最慢子任务和调度开销,倒逼系统优化整体响应速度。只有当并行扩展真正缩短等待时间时,系统才会增加并发度,实现性能与资源消耗的最佳平衡。
杨植麟剧透Kimi K3
K2.5上线后,月之暗面创始人杨植麟、周昕宇、吴育昕集体亮相Reddit,开展长达三小时的AMA问答,回应全球开发者关切。
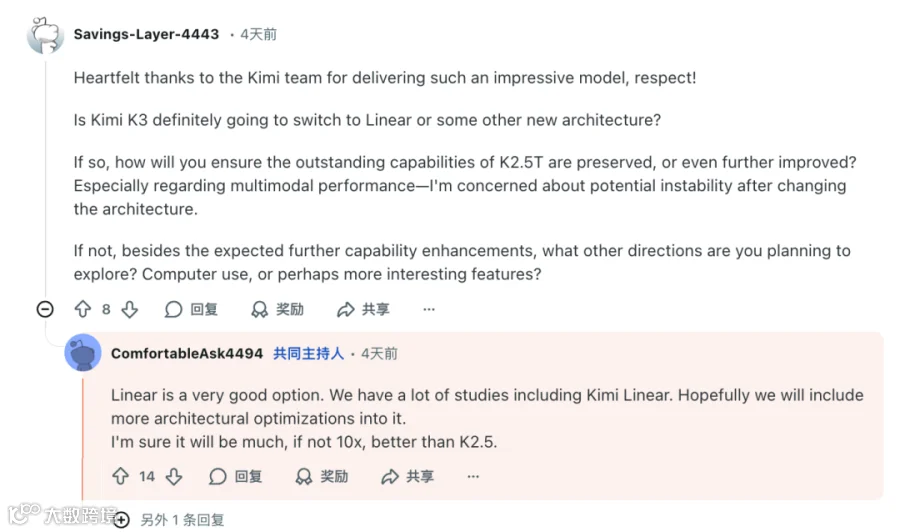
关于下一代Kimi K3,团队透露其可能基于线性注意力机制构建。杨植麟表示,即便K3无法实现相较K2.5十倍提升,也将带来质的飞跃。
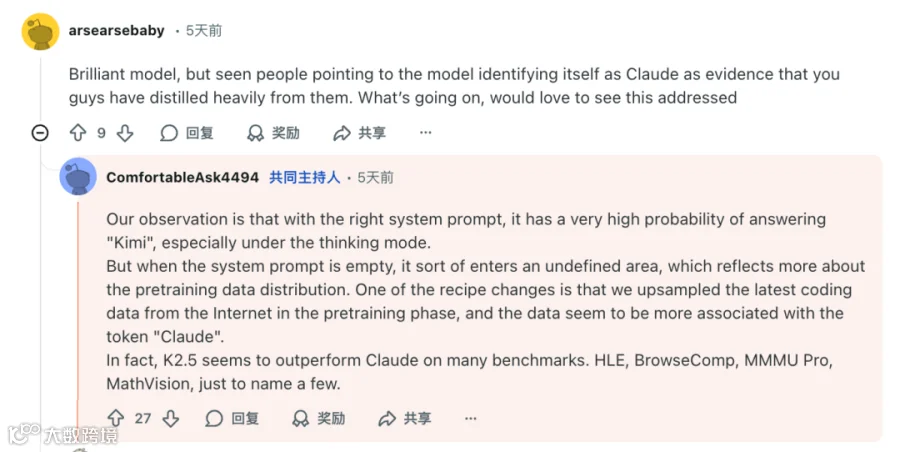
针对K2.5偶现自称“Claude”的现象,团队解释称,因训练数据中大量高质量编程内容涉及Claude,导致模型出现类似“口头禅”的模仿行为,如同长期阅读某作家作品后语言风格受影响。
对于算力焦虑问题,算法负责人周昕宇强调:“创新往往诞生于约束之中”。团队认为,堆砌算力并非通往AGI的唯一路径,真正的突破在于有限资源下催生更高效算法与更优架构,这也是其长期追求的技术目标。