
论文概要
-
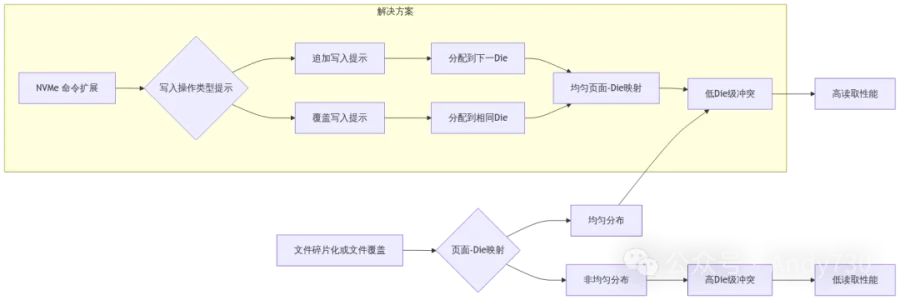
分析文件碎片化对SSD读取性能的影响,提出解决方案。
-
实验分析:使用不同类型SSD和工作负载进行性能测试 -
原因分析:确定性能下降的根本原因 -
解决方案设计:提出新的NVMe命令扩展和页面映射策略 -
方案验证:通过模拟和实际应用测试验证有效性
-
文件碎片化导致SSD读取性能下降,根本原因是Die级冲突(Die-Level Collision) -
文件覆盖操作增加Die级冲突,降低读取性能 -
写入大小小于闪存页大小可能导致页面级碎片化 -
提出的方案有效避免Die级冲突,显著提高读取性能
-
澄清SSD碎片化影响的误解 -
提出新的解决方案:NVMe命令扩展和页面映射策略 -
提供深入的实验分析
-
需要研究页面级碎片化的新分配策略 -
探索更精细的页面映射策略,考虑Die磨损情况 -
将方案应用于其他存储设备,如非易失性存储器(NVM)
摘要
近期研究表明,碎片化(fragmentation)仍然对闪存固态硬盘(SSD)的性能造成不利影响,特别是通过请求分割(request splitting)机制。本研究从三个层面深入探讨了碎片化导致的性能退化:内核I/O路径、主机-存储接口以及SSD内部的闪存访问。我们的分析揭示,与现有文献中的观点相悖,性能退化的主要原因并非请求分割,而是源于Die级冲突(die-level collisions)的显著增加。在SSD中,当其他写入操作插入到相邻文件块的写入之间时,这些文件块不会被分配到连续的闪存Die上,导致随机的Die分配。这种随机性增加了Die级冲突的概率,从而导致后续读取性能的下降。我们还发现,文件覆写过程中也可能出现类似情况。为了解决这一问题,我们提出了一种NVMe命令扩展,并结合页面到Die(page-to-die)的分配算法,旨在确保即使在文件碎片化或覆写的情况下,相邻块始终能够分配到连续的闪存Die上。对商用SSD和SSD仿真器的评估表明,我们的方法有效地减少了由于碎片化和覆写引起的读取性能退化,而无需进行碎片整理。具体而言,当一个162 MB的SQLite数据库被碎片化为10011个片段时,我们的方法将性能下降限制在3.5%以内,而传统系统则经历了40%的性能降低。这一研究成果为优化SSD性能提供了新的思路,特别是在面对文件碎片化和频繁覆写的应用场景中。
1 引言
文件系统碎片化(file system fragmentation)是指同一文件的多个数据块在存储介质上呈现不连续分布,这将导致文件的顺序访问在存储层面转化为一系列随机访问。在机械硬盘(HDD)时代,随机访问引入显著的寻道延迟,导致额外的寻道操作,从而严重影响读取性能。为了防止碎片化引起的性能下降,文件系统采用了多种技术,如延迟分配(delayed allocation)和数据块预分配(block preallocation),以维持数据块的连续性。然而,由于多文件并发写入或长时间后的文件追加写入,文件系统无法始终找到与文件数据块相邻的空闲块,碎片化在某种程度上是不可避免的。
与HDD不同,基于闪存的固态硬盘(SSD)消除了机械运动,显著缩小了随机访问与顺序访问之间的性能差距。然而,最近的研究表明,在访问碎片化文件时,SSD的读取性能仍可能下降两到五倍,这促使研究者开发了多种碎片整理方案以应对这一性能退化。然而,这些研究仅从表面观察了基于碎片化模式的性能下降,并假设其主要原因是内核I/O路径中的请求分割。
本研究通过一系列实验揭示,先前关于文件碎片化对顺序读取性能产生不利影响的论断存在偏差,这些论断基于不完善的实验设置和分析。此外,我们发现在文件碎片化过程中,SSD内部的页面到闪存Die映射偏离了理想状态,导致Die级冲突(Die-level contention)数量大幅增加。相较于未碎片化的情况,这种增加是导致SSD读取性能下降的主要因素。
SSD固件通常采用轮询方式,根据写入顺序在闪存Die上分配页面。因此,当文件碎片化发生时,存储连续文件块的页面无法被放置在连续的闪存Die上,而是被随机分配到任意Die。为了防止因文件碎片化而产生的不当页面到Die映射模式,我们提出了一种NVMe协议的简单扩展,在写入命令中提供页面到Die映射的提示信息。通过这些提示,追加写入的页面被映射到前一个文件块页面所分配Die之后的Die。此外,对现有文件块的覆写操作也可能破坏页面到Die的映射模式,此时页面被映射到原页面所在的同一Die。通过这些简单的提示和映射规则,即使在文件碎片化或对现有文件进行覆写的情况下,也能避免读取操作的性能下降。
我们使用两种配置对所提出的方法进行了评估:首先,通过商业SSD的仿真;其次,在Linux内核和SSD仿真器NVMeVirt中实现。据我们所知,本研究首次通过实验证明,文件碎片化导致的SSD性能下降主要源于其内部并行性的退化。此外,我们表明,这一性能下降并非碎片化的必然结果,而是可以在不改变碎片化状态的情况下通过优化策略避免。
本文的结构安排如下:第二节介绍文件系统碎片化的背景和相关研究;第三节分析闪存SSD中碎片化对性能的影响;第四节提出避免文件碎片化和覆写操作导致性能下降的方法;第五节评估所提方法;最后,第六节总结全文并提出展望。
2 背景与动机
2.1 文件碎片化的旧观念
在硬盘(HDD)时代,文件碎片化导致性能下降的主要直接原因是文件中分散扇区之间的寻道时间。与写入操作可以在存储中缓冲不同,读取操作受到碎片化的影响更为显著,因为读取操作必须等待完成。HDD的长寻道时间掩盖了其他因碎片化而对性能产生负面影响的因素。然而,文件碎片化在三个层面上对性能产生不利影响:内核输入输出路径、存储设备接口和存储介质访问。
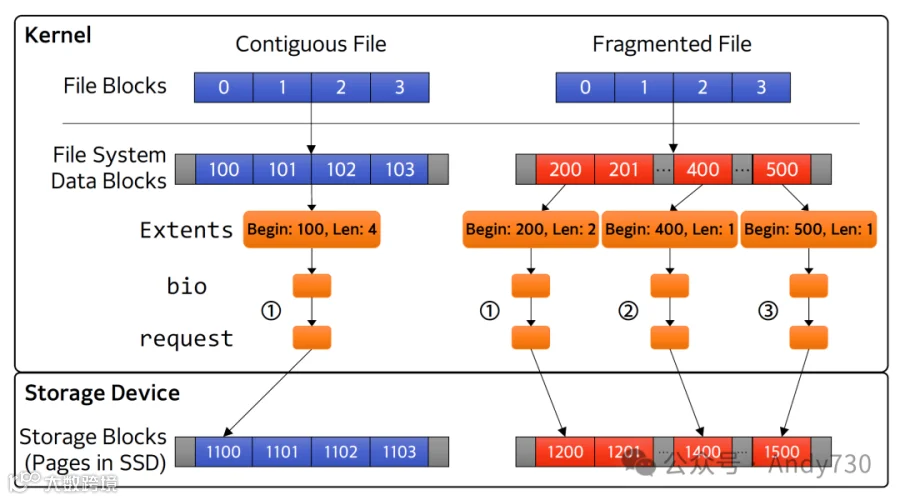 图1:对连续文件的顺序访问被转换为单个设备命令,而对碎片化文件的访问则会产生多个请求。
图1:对连续文件的顺序访问被转换为单个设备命令,而对碎片化文件的访问则会产生多个请求。
如图1所示,对于文件系统而言,文件是一个逻辑上连续的文件块数组。然而,这些文件块实际存储的文件系统数据块可能并不连续。文件系统自然希望将连续的逻辑块存储在连续的数据块中。然而,完全避免数据块分配的碎片化是困难的,特别是当文件随着时间的推移逐渐增长时,其他文件可能会在最后写入的数据块后写入。因此,文件的数据块可能被分配在不同的位置。
主机仅需一个命令即可指示存储设备对连续存储空间执行读取或写入操作。因此,当对文件进行顺序读取时,Linux内核会读取文件inode中的数据块映射,并为每个连续数据块区域创建一个bio(块输入输出)数据结构。该数据结构用于创建相应的请求数据结构,以传递给设备驱动程序,然后发出请求命令。通过这一过程,单次顺序文件访问可能因文件碎片化而分割成多个bio和相应的请求。
这种请求分割被认为会增加输入输出执行时间,因为它增加了数据结构创建和对底层函数(包括设备驱动代码)的调用次数。显然,设备命令数量的增加会导致在SATA或NVMe接口层级的时间延迟。存储设备命令的增加也延长了存储设备固件的处理时间。具体而言,提取、解码、将命令转换为存储介质操作以及排队介质访问操作的频率都会增加。因此,文件碎片化还延迟了存储设备控制器的处理时间。
最后,文件碎片化延长了存储设备中存储介质的访问时间。如前所述,在HDD情况下,需要寻道时间使磁头移动到请求扇区所在的轨道,同时发生磁盘旋转延迟以定位该扇区。然而,与由内核输入输出路径和存储设备接口引起的性能下降不同,由于SSD没有寻道时间和旋转延迟,预计碎片化不会增加存储介质的访问时间。
为了解决因碎片化引起的性能下降,进行了两类研究:一种旨在防止碎片化的发生,另一种则通过将碎片化的文件转变为连续文件以恢复文件访问性能。
在ext4文件系统中使用的延迟分配技术在处理写入系统调用时并不进行数据块分配,而是在页面刷新时进行。在小写操作与其他文件写入交错的情况下,延迟分配增加了为文件分配连续数据块的可能性。
此外,ext4为每个文件的inode预留了一个预定义的空闲数据块窗口。这些保留的空闲块将被实际分配给文件进行后续的追加写入。这显著减少了碎片化的发生,尤其是在同一目录下多个文件同时写入时。
尽管这些技术可以减少文件碎片化的频率,但研究表明,碎片化是文件系统老化的不可避免结果。因此,提出了各种碎片整理工具,以将分散的文件数据块重写为连续的块,从而恢复输入输出性能。
Sato提出了一种针对Linux ext4文件系统的在线碎片整理工具。该方案将连续的空闲块分配给一个临时inode,将碎片化的文件数据复制到该临时inode,删除原始文件,并将临时inode重命名为原文件名。
为减轻碎片整理带来的开销,提出了多种技术,因为复制所有碎片化文件可能需要大量时间。例如,F2FS的碎片整理工具defrag.f2fs允许用户通过手动输入起始块地址、长度和目标位置等参数,选择性地迁移用户选定的区域。XFS的xfs_fsr按扩展数对文件进行排序,将前10%的文件分组为一个称为“传递”的单元,针对每个传递执行碎片整理。Btrfs的内置碎片整理工具仅对小于指定目标扩展大小的扩展进行碎片整理。然而,最终,碎片整理消耗了大量时间和能量,因为它在相对较慢的存储设备上诱发了大量的读写操作。
2.2 SSD时代的文件碎片化
大多数研究人员和SSD制造商最初声称,SSD性能不受文件碎片化的影响,碎片整理是不必要的,甚至可能有害,因为碎片整理过程中涉及的写入操作可能减少闪存的使用寿命。然而,与最初声称SSD不存在碎片化问题相反,一些研究人员观察到了由于文件系统老化和随之而来的碎片化导致的性能下降。
SSD的性能远远高于单个闪存Die,因为它们可以并行操作多个闪存Die。具体而言,NVMe SSD提供65,535个命令队列,每个队列能够排队65,536个命令。即使碎片化导致请求大小减小,无法充分利用Die级并行性,命令队列中的较小闪存操作仍然可以无序处理,从而使大多数Die得到充分利用。这使得SSD在访问小片段时仍能接近其最大潜力。因此,一些研究人员推测,内核输入输出路径和请求分割带来的接口开销对碎片化引起的性能下降的影响大于闪存访问时间。
Conway等人在SSD上通过各种工作负载实证观察到由于文件系统老化导致的性能下降。他们发现,随着文件系统老化,文件碎片化在SSD上经常发生。在多次执行git pull命令的场景中,他们观察到读取性能可能下降多达五倍。Geriatrix是一个能够有效模拟文件系统和存储老化的工具。利用Geriatrix,作者展示了由于文件系统老化,SSD上性能下降高达78%。尽管这两项研究观察到了文件系统布局的变化以及由于文件系统老化导致的性能下降,但并未深入分析这种性能下降的潜在原因。
Park和Eom认为,SSD上由于碎片化导致的性能下降的主要原因是请求分割,因此数据块之间的距离并不显著影响读取性能,而碎片化的程度则确实有影响。在后续的论文中,他们提出了相矛盾的说法,指出碎片块之间的距离同样显著影响SSD上的性能。此外,他们提出了FragPicker,这是一种高效的碎片整理方法,能够在线迁移仅被访问的碎片。
Zhu等人提出了一种方案,可以同时为ext4中的碎片整理发出并行输入输出请求,从而最小化碎片整理时间并最大化SSD内部并行性。这种方法使碎片整理时间相比传统的e4defrag减少了三倍。
针对这些矛盾的说法,我们在第三节中澄清这一问题的根源在于之前研究的实验设置未能区分由碎片化直接引起的性能下降与碎片化对SSD内部数据布局影响间接引起的性能下降。
2.3 现代闪存SSD的内部结构
如前所述,现代闪存SSD配备了多个可以并行操作的闪存Die(die)。为了最大化SSD的带宽和吞吐量,维护较高的Die级并行性至关重要。相反,由于每个Die只能同时处理一个请求,如果要读取的页面存储在单个Die上,那么这些页面的读取请求必须在该Die内进行串行处理。这种Die级读取冲突显著降低了读取性能。
为防止读取操作中的Die级冲突,SSD固件的闪存转换层(FTL)必须以分散的方式进行物理页面分配,使存储连续逻辑页面的物理页面尽可能地分布在多个Die上。为此,大多数现代SSD的FTL在为处理传入页面写入请求分配闪存页面时采用循环选择Die的方式。此外,当垃圾回收(GC)过程进行时,如果Die中有足够数量的空闲页面,现代FTL会在页面所在的Die内执行有效页面的复制。这有助于保持Die的并行性。然而,由于GC在所有Die上并行进行,这一策略对GC的性能影响不大。
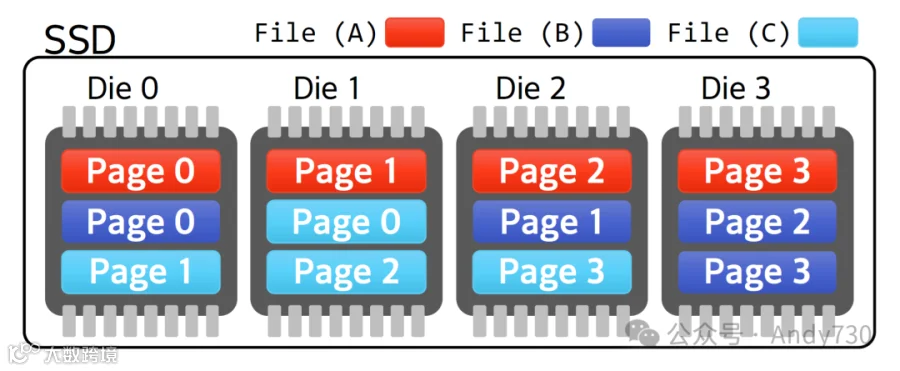 图2:在闪存SSD中,三个文件的数据放置情况,其中一个是连续的,另外两个是碎片化的。
图2:在闪存SSD中,三个文件的数据放置情况,其中一个是连续的,另外两个是碎片化的。
例如,在图2中,文件A均匀分布在四个Die上,因为其四个页面是无干扰地写入的。因此,对文件A的顺序读取将同时在这四个Die上进行,带宽可达到闪存Die性能的四倍。相反,假设对文件B和文件C的写入是交错进行的。由于存储逻辑页面的Die是根据SSD内的写入顺序以循环方式分配的,因此文件B的第三个和最后一个页面都被分配到Die3上。因此,读取文件B的时间是读取理想放置文件(如文件A)所需时间的两倍。
文件碎片化通常发生在多个文件同时写入的情况下。因此,当发生文件碎片化时,与文件相关的闪存页面的Die分配可能不均匀,导致单个文件的页面集中在某些Die上。这种现象的出现是因为FTL仅根据页面的传入顺序分配Die。然而,文件碎片化的存在并不必然导致页面在Die间的不均匀分布,就像连续文件并不保证其页面会始终均匀且顺序地分配到连续的Die上。
通过ext4的预分配机制,数据块可以在文件系统中连续分配,即使在此过程中其他文件进行写入。然而,由于闪存页面的Die映射是在其实际写入时发生的,即使在文件系统层面上连续的文件,在SSD中也可能出现不均匀的页面分布。相反,如果一个碎片化文件的数据块在适当的时机写入,则该文件的页面有可能在所有Die间均匀分布。
除了碎片化情况,文件覆盖时也可能发生不规则的Die分配。假设一个存储在连续文件系统块中的文件,其页面在SSD上被顺序分配到Die。在这种理想情况下,如果对文件的中间块执行覆盖,SSD必须为该块分配一个新页面,并根据闪存的特性使当前映射到该块的页面失效,因为闪存不支持原地更新。此时,根据循环分配策略,新页面将从最后一个分配页面的相邻Die中分配。因此,新页面很可能不会位于与原页面相同的Die上,这导致在对该文件进行顺序读取时,由于Die级冲突,性能显著下降。
3 文件碎片化分析
本节通过一系列实验探讨了碎片化引起的性能下降原因。实验系统的配置如表1所示。我们使用了ext4文件系统。为最小化内核页面缓存和区间缓存对实验结果的影响,在每次实验运行之前进行了缓存清除。此外,为了调整实验中的块I/O请求队列深度,我们使用了内核的nr_requests参数。所有实验结果均为10次重复的平均值。
处理器:Intel Xeon Gold 6138 2.0 GHz,160核
芯片组:Intel C621
内存:DDR4 2666 MHz,32 GB × 16
操作系统:Ubuntu 20.04 服务器版(内核版本 5.15.0)
接口:PCIe Gen 3 x4 和 SATA 3.0
存储设备:
NVMe-A: 三星 980 PRO 1 TB
NVMe-B: 西数 Black SN850 1 TB
NVMe-C: SK 海力士 Platinum P41 1 TB
NVMe-D: Crucial P5 Plus 1 TB
SATA-A: 三星 870 EVO 500 GB
-
SATA-B: 西数 Blue SA510 500 GB
首先,我们基于碎片化程度(Degree of Fragmentation,DoF)检查了在NVMe SSD上ext4的性能下降。DoF是实际区间数量与理想区间数量的比率。为此,我们创建了一组具有不同DoF的文件。每个碎片化文件大小为8 MB,文件的写入是通过将目标文件的写入与一个虚拟文件的写入交错进行多次完成的,以实现所需的DoF。在写入目标文件的虚拟文件大小方面,确保目标文件的两个碎片之间的偏移量为8 MB。例如,如果目标DoF为4,则需要四个碎片或区间构成8 MB的目标文件。我们首先写入目标文件的四分之一,然后写入6 MB的虚拟文件。通过重复这一过程四次,可以得到一个DoF为4的8 MB文件。
在我们的分析中,DoF的范围从1(表示连续文件)到256,与以往研究不同,后者的范围通常更大。在我们的分析中,当DoF为256时,碎片大小为32 KB。由于前述的延迟分配和块保留技术,ext4使用这些技术来抑制碎片化,因此碎片的大小很可能不会小于该值。
为了使用此方法精确创建具有所需DoF的文件,必须禁用延迟分配和块保留。为禁用延迟分配,我们在写入文件时采用直接模式,并提供了nodelalloc挂载选项。通过将reserved_clusters运行时参数和mkfs的保留块百分比都设置为0,从而中和了块保留。我们还禁用了每个inode的预分配功能。每个碎片化文件通过使用filefrag工具进行验证,以确认其具有所需的DoF。在ext4中,一个单独的区间可以表示215个连续块,即128 MB,文件系统的块大小为4 KB。由于所有碎片均小于128 MB,因此所需的DoF值恰好与构成该文件的区间数量相匹配。
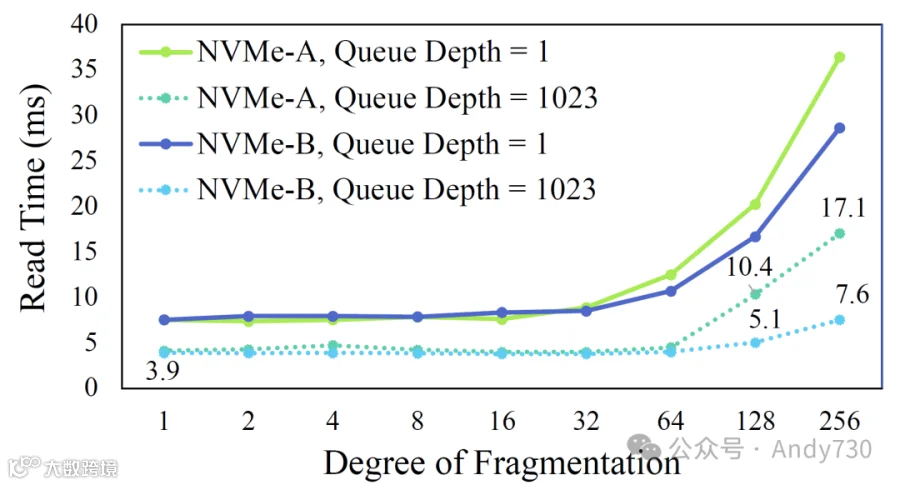 图3:在不同DoF(数据块深度)下,读取存储在NVMe SSD上的8 MB文件所需的时间。
图3:在不同DoF(数据块深度)下,读取存储在NVMe SSD上的8 MB文件所需的时间。
如图3所示,两个NVMe SSD的读取性能在DoF超过64时均有所下降,无论请求队列深度如何。由于Linux内核的默认最大请求大小为1 MB,因此当碎片大小超过1 MB时,没有观察到性能差异,这对应于DoF为8或更低的情况。
值得注意的是,当队列深度设置为1时,两款SSD的性能变化更为剧烈。当I/O队列深度设置为1023,即NVMe SSD的Linux默认值时,执行时间较短,而由于碎片化造成的性能下降相比于队列深度为1时不那么明显。然而,即使在1023的队列深度下,随着DoF的增加,执行时间也显著增加。在DoF为128和256时,NVMe-A的执行时间分别比DoF为1时长2.7倍和4.4倍。类似地,NVMe-B在DoF为128和256时的执行时间分别长1.3倍和1.9倍。
在该实验中,我们确认了文件碎片化确实会导致SSD的性能下降。为了进一步阐明这种性能下降的具体原因,随后进行了进一步的实验。
3.1 请求拆分造成的影响
如前所述,文件碎片化导致请求拆分,单个I/O操作被转化为多个设备命令。请求拆分造成的主机端处理时间增加对性能下降的影响在存储设备处理时间较短时更加明显。因此,我们使用ramdisk作为存储设备,测量了由于请求拆分在内核I/O路径中产生的延迟,因为ramdisk具有极短的主机与存储接口及存储介质访问时间。
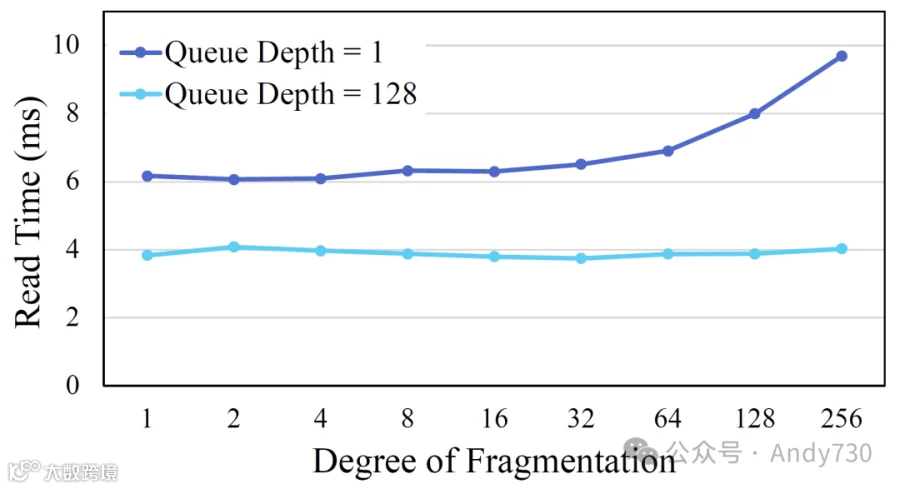 图4:根据DoF,顺序读取存储在ramdisk上的8 MB文件所需的时间。
图4:根据DoF,顺序读取存储在ramdisk上的8 MB文件所需的时间。
图4展示了根据DoF存储在ramdisk上的文件的顺序读取性能。由于ramdisk具有极快的访问速度,并且随机访问与顺序访问时间之间的差异可以忽略不计,因此图4中观察到的性能变化主要归因于内核I/O路径所消耗的时间,而非存储介质。我们的实验表明,当DoF增加且请求队列深度设置为1时,读取性能下降,当DoF为256时,读取时间增加了1.5倍。
如前所述,对于每个连续的存储地址范围,会生成一个对存储设备的请求。因此,直接I/O所需的iomap结构、bio结构和请求结构的数量随着DoF的增加而增加。此外,这些结构创建所需的函数调用数量也随着DoF的增加而增加。当队列深度设置为1时,这些过程是同步进行的。因此,随着DoF的增加,内核I/O路径的处理时间也相应增加,这种增加在DoF超过8时变得更加明显。
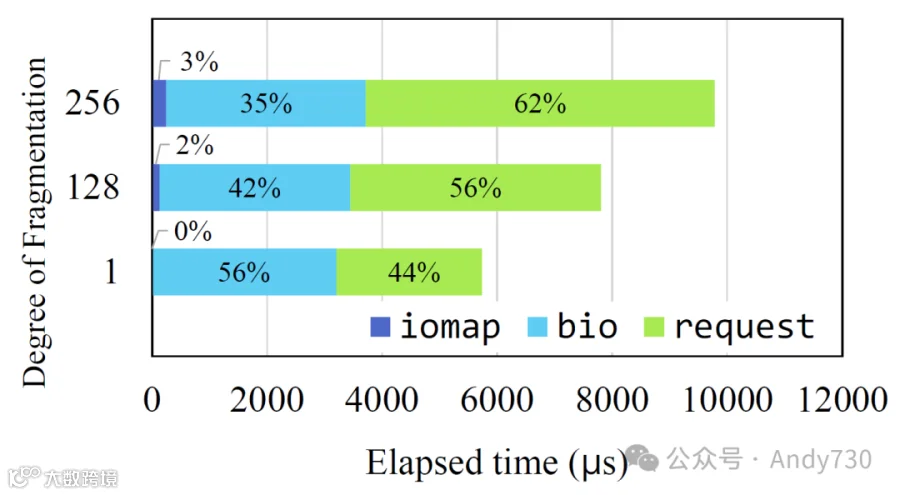 图5:在内核I/O路径中,根据文件的DoF创建请求数据结构所需的时间组成。
图5:在内核I/O路径中,根据文件的DoF创建请求数据结构所需的时间组成。
为了识别这些延迟的原因,我们测量了__x64_sys_read函数(处理读取系统调用)在DoF变化时分别创建iomap、bio和请求结构所需的时间。如图5所示,随着DoF的增加,iomap创建时间略有上升,因为每个区间创建一个iomap。相较于iomap创建时间,bio创建所花费的时间变化较小。这是因为大部分bio创建时间用于分配缓冲页面,而要分配的缓冲页面数量在2048时保持不变,与文件的DoF无关。在请求创建过程中,如果存在连续的bio地址,它们将被合并为一个请求。然而,碎片化文件妨碍了这一合并。因此,创建请求所花费的时间随着DoF的增加而增加。
值得注意的是,即使在DoF为256的极端情况下,内核I/O路径的处理时间也仅约为9.7毫秒。此外,当I/O队列允许排队多个未完成命令时,这种I/O路径延迟可以通过对后续碎片的连续读取操作大部分重叠。如图4所示,当请求I/O队列深度设置为128,即ramdisk的默认值时,文件的DoF对读取操作的时间几乎没有影响。
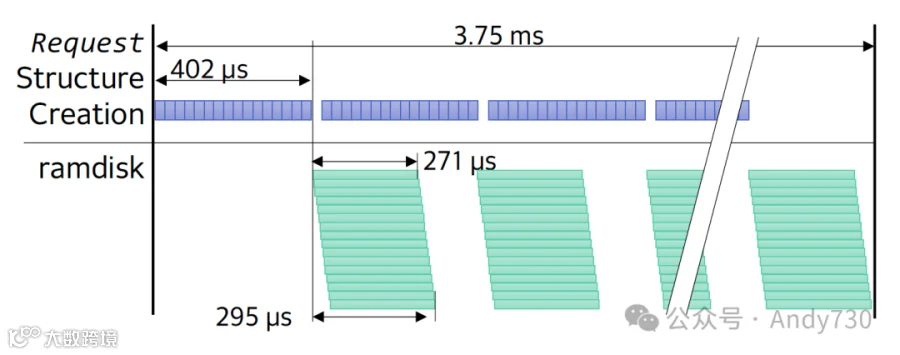 图6:当文件的DoF为128时,由于存储操作与请求创建的重叠,读取时间的减少。
图6:当文件的DoF为128时,由于存储操作与请求创建的重叠,读取时间的减少。
我们密切观察了可被I/O排队遮蔽的内核I/O路径延迟。图6显示了在读取DoF为128且队列深度为128的文件时,请求数据结构创建和ramdisk访问所花费的时间,这些数据是通过blktrace测得的。内核通过合并连续块的请求来减少发往存储的命令数量。当请求数量超过预定义的最大可插入请求数量,或单个请求的大小超过预定义的插入刷新大小时,插入的请求将被解除插入并发送到设备驱动程序。这些参数的默认值分别为16个请求和128 KB。因此,在实验中,16个请求被插入,然后由于它们均访问不同块,分别发往设备驱动程序。因此,内核I/O路径中创建后续16个请求所花费的时间大部分被ramdisk处理前16个请求的时间所遮蔽。此外,通过同时发出多个请求,ramdisk的处理时间因操作重叠而显著减少。
通过这些实验,我们发现即使在极端情况下,由于请求拆分引起的内核I/O路径延迟也仅在几毫秒的水平。此外,我们确认其对实际执行时间的影响因I/O操作的排队而微不足道。
接下来,我们分析了由于请求拆分在主机与存储接口以及SSD内部造成的执行时间延迟。由于SSD内部实现是一个黑箱,无法准确区分接口消耗的时间和闪存访问时间,因此我们分析了它们的综合执行时间。为此分析,我们使用了两种类型的SATA SSD和两种类型的NVMe SSD,如表1所示。
在此分析中,我们执行了从存储设备读取8 MB连续数据的任务,通过访问SSD的原始设备文件,以排除文件系统和内核I/O路径的影响。在此过程中,我们在将单位读取大小从32 KB逐步增加到8192 KB时测量性能,每次加倍。为了最小化SSD状态(如无效页面比率和空闲块数量)对结果的影响,我们在每次实验后使用trim命令对整个区域进行了处理,以恢复SSD至出厂状态。然后,我们在1 GB的区域上进行了顺序写入,以便读取。
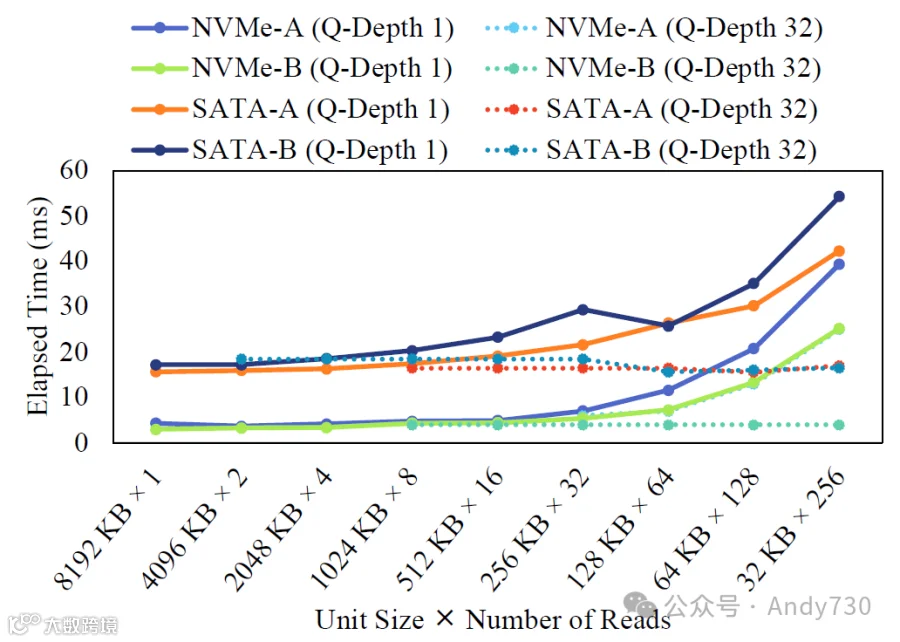 图7:通过原始设备I/O操作读取8 MB数据时,单位大小变化所需的时间。
图7:通过原始设备I/O操作读取8 MB数据时,单位大小变化所需的时间。
图7展示了从四个SSD中读取8 MB数据所需的时间,取决于读取操作的单位大小。与图4类似,当设备的队列深度设置为1时,读取8 MB数据的经过时间随着读取单位的大小减少而增加。根据结果的回归分析,对于NVMe SSD,每增加一个请求,经过的时间增加85微秒,而对于SATA SSD,每增加一个请求,时间增加136微秒。这些结果涵盖了请求拆分对主机与设备接口、SSD固件和闪存访问时间的影响。在这些因素中,随着单位读取操作大小的增加,闪存访问时间有望减少,这受到上述内部并行性的影响。
然而,当排队多个未完成I/O操作时,请求拆分导致的读取时间延迟消失,这与内核I/O路径中的情况类似。SATA标准的本地命令队列(Native Command Queue,NCQ)可以排队多达32个未完成命令,而NVMe标准则支持65,536个队列和65,535的队列深度。因此,当发生请求拆分时,SSD可以同时将拆分的请求放入命令队列,并无序处理它们。这减少了主机与设备接口之间的交互次数,并进一步增加了SSD的die级并行性。图7中的虚线显示了在命令队列深度设置为32时的结果。正如预期的那样,尽管读取单位大小减少,因此所有SSD中的读取命令数量增加,但总执行时间的差异仍在几毫秒之内。
基于我们的分析,我们确认内核I/O路径中的请求拆分开销与因碎片化造成的操作时间增加相比是微不足道的。此外,通过命令排队异步发出I/O操作时,其影响也大大减轻。此外,我们验证了即使发生请求拆分,主机与设备接口及存储设备内部的处理时间增加也极其有限,再次得益于大多数现代SSD所支持的命令排队。
3.2 碎片化导致的页面错位
如图2所示,当文件顺序写入且在顺序写操作之间没有中断写入时,SSD会以轮询方式均匀分配文件的页面到所有的闪存Die(die)上。然而,在文件碎片化的情况下,这种理想的页面分配变得不可能,因为在对碎片化文件进行写入时,其他文件的写入会插入其中。碎片化的情况下,断点之后的页面将被随机分配到某个闪存Die上,而不考虑其前面的页面所在的闪存Die。在现代SSD中,由于其通常有数十个闪存Die,包含碎片化块的页面被分配到与前一个文件块的页面相邻的闪存Die的可能性显著降低。因此,在对碎片化文件进行顺序读取时,导致的闪存Die级冲突显著多于理想页面分配情形。图3中的实验通过创建碎片化文件并以此方式进行读取,证实了这一点。以往的大多数研究也以类似方式进行了文件碎片化。因此,在实验中观察到的碎片化文件访问性能显著下降,很可能是由于闪存Die级冲突造成的。
在这些实验中观察到的闪存Die级读取模式,可以通过在特定间隔下读取连续写入的文件块来在实际SSD中进行模拟。例如,考虑一款将4 KB页面按轮询方式分配到16个闪存Die的SSD。如果我们顺序写入1 MB数据,即256个页面,然后读取每隔一个页面,这将产生类似于我们在实验中以DoF为128顺序访问512 KB文件的闪存Die级读取模式。在这种情况下,与读取128个连续页面相比,读取操作仅发生在一半的闪存Die集上。这将不可避免地导致闪存Die级冲突翻倍,使读取128个页面的时间几乎增加一倍。出于同样的原因,每隔四个页面读取,总共64个页面,读取时长几乎会比读取64个连续页面长四倍。
为了研究这种模式下读取性能的变化,我们进行了以下实验。在将SSD初始化至其FOB状态后,我们顺序写入1 GB数据到指定的读取区域。随后,我们配置fio以一致的间隔顺序读取4 KB的块。例如,如果读取起始点的间隔设置为16 KB,则将设置为读取4 KB,跳过12 KB的间隙,然后再读取4 KB。为此,我们修改了fio的blockalign参数,以4 KB为步长,从最小4 KB到最大1024 KB进行增量设置。在这些实验中,对于NVMe SSD,我们将fio的iodepth参数设置为512,而对于SATA SSD,设置为其支持的最大值32。此外,为了排除文件系统和内核I/O路径的影响,我们将fio配置为对原始设备文件进行直接访问。
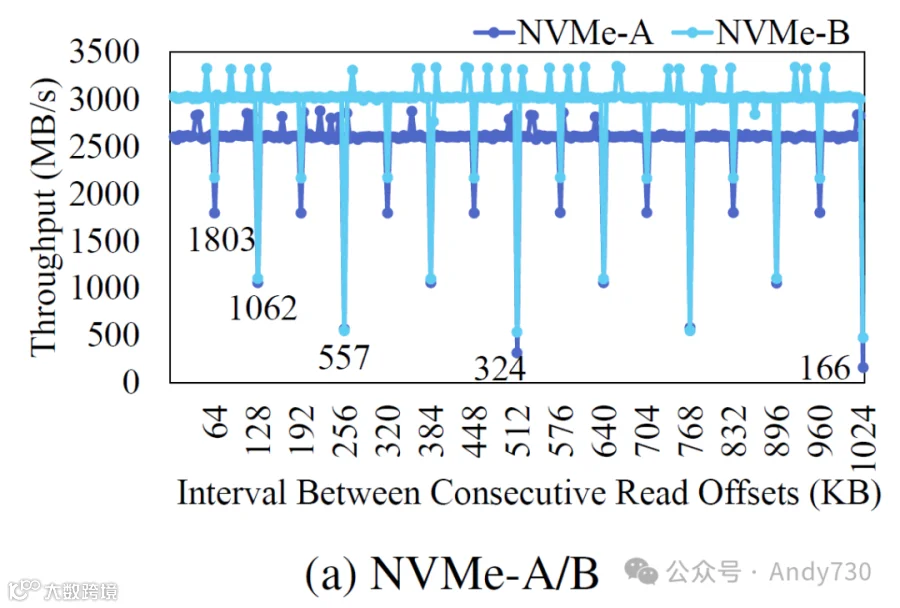
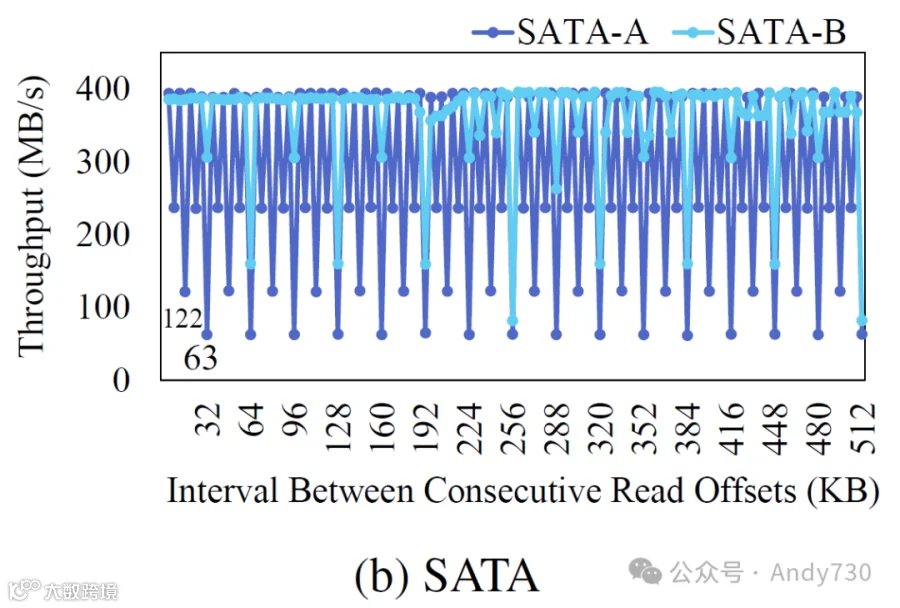
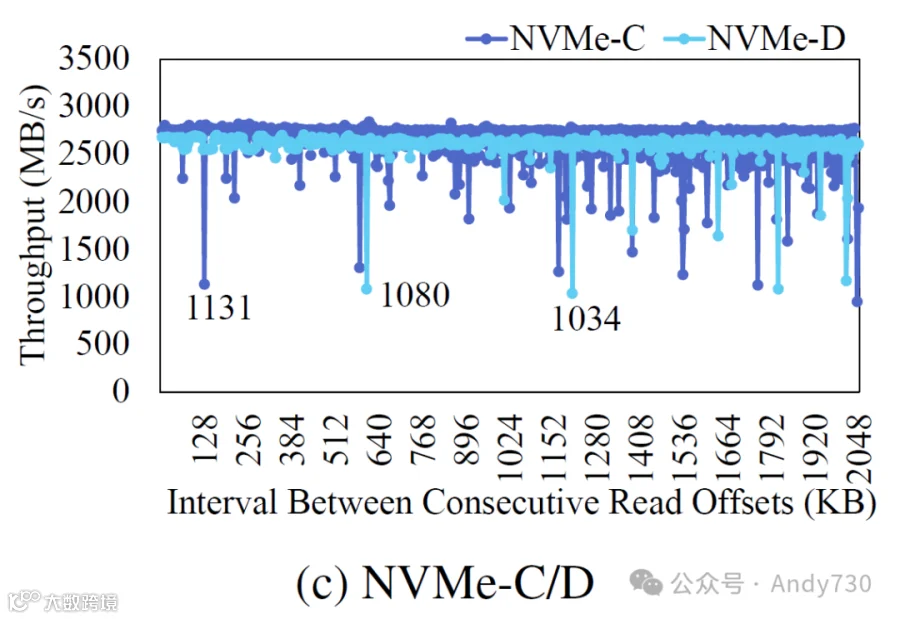 图8:在连续读取操作的起始点之间变化的间隔下的吞吐量。
图8:在连续读取操作的起始点之间变化的间隔下的吞吐量。
图8a展示了在改变读取间隔时,两个NVMe SSD的吞吐量测量结果。当内部并行性充分利用时,SSD实现了分别为2600 MB/s和3020 MB/s的吞吐量。然而,随着读取操作之间间隔的增加,观察到的持续吞吐量分别下降至166 MB/s和480 MB/s。在两个NVMe SSD中,当间隔达到64 KB时,首次出现明显的性能下降。这表明这两款NVMe SSD在对一个闪存Die分配32 KB大小页面后,才继续在后续闪存Die上进行分配,尽管一次分配到一个闪存Die的实际页面数可能根据设备的页面大小而变化。我们将给定时刻分配给单个闪存Die的页面大小称为闪存Die分配粒度。这两款NVMe SSD均使用16 KB的页面大小,闪存Die分配粒度为32 KB,意味着每个闪存Die每次分配两个页面。这表明这两款SSD采用了双平面编程方法存储两个页面。
在64 KB间隔开始时,显示的对齐大小出现显著的性能下降,随着每次间隔翻倍,性能下降的程度更加明显。这很可能是由于每次间隔大小翻倍时,用于读取的闪存Die数量减半,正如前面提到的。实际上,对于这两款SSD,当对齐大小从64 KB翻倍至1024 KB时,吞吐量每次下降41%到49%。对于NVMe-A,当对齐大小为1024 KB时,最低性能被观察到,其吞吐量降至典型值的约6.5%;而对于NVMe-B,最低性能在256 KB时观察到,降至18.5%。这些观察表明,表示在重新分配过程开始前写入到所有闪存Die的数据量的条带大小在SSD之间存在差异。我们的实验推测,NVMe-A的条带大小为1 MB,而NVMe-B为256 KB。对于超出条带大小的对齐大小,性能将与等于对齐大小与条带大小取模的情况相同。
在SATA SSD中也观察到了这一现象,如图8b所示。虽然两款产品在所有页面可访问时的吞吐量均为400 MB/s,但可访问页面的对齐大小变化导致吞吐量下降:SATA-A下降至62 MB/s,SATA-B下降至82 MB/s。SATA SSD的性能下降点与NVMe SSD相比存在显著差异,SATA-A在对齐大小为8 KB时首次出现性能下降。这表明其闪存Die分配粒度为4 KB。最显著的性能下降出现在32 KB,指示条带大小为32 KB。对于SATA-B,首次性能下降发生在间隔达到32 KB时,而在256 KB时仅显示其正常吞吐量的20.7%。因此,SATA-B的闪存Die分配粒度为16 KB,条带大小估计为256 KB。
考虑到文件碎片化,两个访问块之间的间隔通常与文件块大小的倍数对齐,通常为4 KB或8 KB。如在SATA SSD中所示,当以4 KB的倍数读取时,性能显著下降。因此,由于文件碎片化引起的闪存Die级冲突增加及随之而来的性能降低是不可避免的。虽然与SATA SSD相比,NVMe SSD通常具有更大的闪存Die分配粒度和条带大小,导致小读取间隔的性能下降不那么明显,但它们并未免于由于间隔读取模式带来的闪存Die级冲突增加。
然而,并非所有SSD在一致的间隔下都表现出性能下降,正如前面提到的四款产品所示。图8c展示了NVMe-C和NVMe-D在读取偏移间隔下的性能下降情况。与之前的SSD不同,这两款产品出现下降的间隔并不一定是2的幂。对于NVMe-C,在64 KB和128 KB间隔时注意到性能下降,而随后的下降则在584 KB的倍数下发生。对于NVMe-D,下降发生在604 KB的倍数间隔。SSD的闪存Die分配策略因制造商而异。然而,实验结果确认非顺序页面访问最终导致因高闪存Die级冲突而造成显著的性能降低。
与通过增加I/O队列深度来隐藏的I/O路径开销或接口开销不同,由于闪存Die级冲突导致的读取性能下降即使在I/O队列深度较大时仍然持续存在。因此,对于Linux内核默认队列深度为64的SATA SSD和队列深度为1023的NVMe SSD,我们可以得出结论,文件碎片化造成的性能损失的主要原因并非内核I/O路径或接口开销的延迟,而是SSD内部的闪存Die级冲突。换句话说,尽管在硬盘驱动器(HDD)中,文件碎片化导致额外的寻道时间和旋转延迟,但在SSD中,它则导致额外的闪存Die级冲突。
4 我们的方法
如前所述,读取碎片化文件时性能下降主要源于闪存Die级冲突的增加。然而,碎片化文件中观察到的不规则页面与闪存Die映射仅仅是导致碎片化的情况所产生的结果,而非碎片化发生的必要条件。
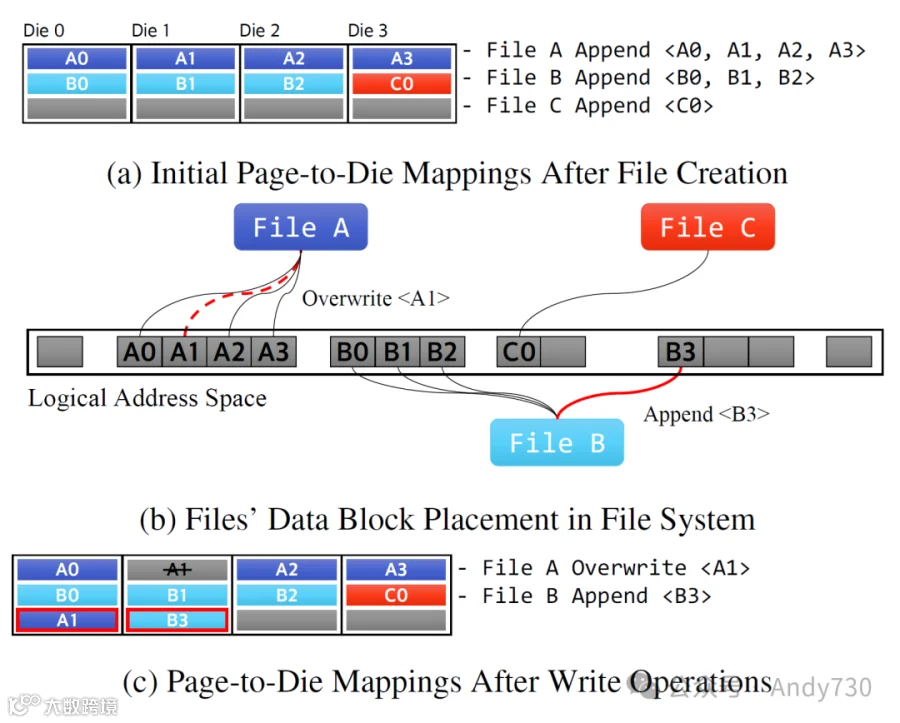 图9:写操作前后,文件系统级块放置和存储级页面分配的三种文件情况。
图9:写操作前后,文件系统级块放置和存储级页面分配的三种文件情况。
例如,假设文件B的三个块如图9a所示,而文件C和A分别写入一个块。从这个初始状态出发,如果应用程序向文件B追加B3,B3将与B1存储在同一个闪存Die上,如图9c所示。因此,对文件B的顺序读取将在闪存Die1处造成冲突。然而,如果在图9a所示的情况下,文件A不仅覆盖A1,还覆盖A2和A3,则B3的位置将移动两个闪存Die,位于闪存Die3。在这种情况下,文件B在文件系统中以不连续的块存储,如图9b所示,顺序访问该文件将导致请求拆分。然而,由于SSD内部的命令排队,所有闪存Die同时处理相同数量的操作,能够实现最大性能。如前所述,由于请求拆分导致的内核I/O路径和主机到存储接口的时间延迟微乎其微;因此,尽管文件B是碎片化的,其读取性能几乎不受影响。
反之,即使在没有文件碎片化的情况下,也可能发生不规则页面与闪存Die的映射。通常,覆盖现有文件块会打破页面到闪存Die映射的顺序性。例如,考虑在图9a所示的情况下覆盖A1。文件系统支持对块的就地更新,因此A1在文件系统中的位置保持不变。因此,即使在覆盖A1后,文件A仍然保持其连续状态。然而,由于对闪存页面的就地更新是不可能的,存储A1块的原始页面将失效,如图9c所示,更新后的A1的新页面被分配到闪存Die0,该Die位于闪存Die3之后。因此,尽管文件A在文件系统层面是连续的,但对文件A的顺序读取将在闪存Die0处显著减慢。
分析导致上述不规则页面与闪存Die映射的碎片化和覆盖两种情况,根本原因在于SSD固件无法识别闪存页面之间的文件级关系,反之,文件系统也无法明确指定存储文件块的闪存页面的位置。为了解决页面与文件块放置之间的不匹配,我们提出了一种NVMe命令扩展及相应的页面与闪存Die映射策略。
在我们的方法中,文件系统将需要新数据块分配的写操作视为追加写,而对已分配给文件的数据块进行的写操作视为覆盖。如果内核I/O栈识别出写入NVMe SSD的写操作为追加写或覆盖,则在现有的NVMe写命令基础上,向NVMe传达附加信息,以执行适当的页面与闪存Die映射。
 图10:在我们的方法下,覆盖A1和附加B3块后的页面到闪存Die映射。
图10:在我们的方法下,覆盖A1和附加B3块后的页面到闪存Die映射。
对于追加写,主机在写命令中提供正在写入的文件块之前的逻辑块地址(LBA)。例如,当在图9a中向文件B追加B3时,主机将B2的LBA与B3的写命令一并发送给NVMe。在这种情况下,NVMe固件偏离传统的轮询算法来确定B3的闪存Die位置。相反,如图10所示,它将B3分配给闪存Die3,该Die是存储B2之后的下一个闪存Die。如果写操作的大小超过了闪存Die分配粒度,则后续页面的放置遵循传统的轮询方法;例如,在此示例中,第二个页面在第一个页面放置在闪存Die3之后被分配到闪存Die0。
对于覆盖,主机在写命令中设置一个标志,以指示该写操作是对现有文件块的覆盖。对于设置了覆盖标志的写命令,SSD固件将使对应于给定LBA的现有闪存页面失效并分配新页面。通过将新页面分配到原始闪存页面所在的同一闪存Die,能够保持文件块的闪存Die级连续性。例如,当在图9a中覆盖文件A的A1块时,新的闪存页面分配给闪存Die1,即原始存储A1的闪存页面所在的地方,如图10所示,确保文件A的顺序读取保持最大内部并行性。对于超过闪存Die分配粒度的覆盖,通过将新页面分配到现有逻辑页面所在的同一闪存Die上,也可以保持闪存Die级连续性。
为实施所提出的方法,主机在发出写操作时需要向SSD提供附加信息。我们可以利用NVMe协议写命令中未使用的位来实现这一点,而不增加额外的协议开销。例如,可以利用命令字(CDW)12的第24位和第25位,这两个位当前未使用并被保留,用于区分追加写和覆盖写与传统写的不同。此外,对于追加写,可以使用保留的CDW 2和CDW 3来传达前一个文件块的LBA。
我们的方法具体只确定追加写的起始闪存Die,后续写操作遵循现有的映射策略,按照轮询方式分配到各个闪存Die。因此,它不会影响追加写的性能。虽然可以假设对同一文件块的重复小规模覆盖可能导致写入闪存Die的冲突,但这些通常会在主机缓冲区中合并,并且不频繁刷新到SSD。因此,即使在这些极为罕见的情况下,我们的方法也不会对写入性能产生不利影响。
然而,持续覆盖少量文件块可能会迅速耗尽某些闪存Die中的空闲页面,从而触发这些闪存Die更早进行垃圾回收(GC)。与此同时,这些覆盖会使被覆盖的页面失效,减少有效页面的数量。这种有效页面的减少在进行这些闪存Die的GC时,需要的有效页面副本更少,这不仅降低了写入放大因子,还缩短了GC过程的持续时间。
尽管这些情况很少发生,但并不理想,因为它们可能导致特定闪存Die上更频繁的GC,并导致闪存Die之间的磨损不均匀。这种磨损不均匀可能导致某些闪存Die过早磨损,最终缩短SSD的使用寿命。频繁覆盖的LBA可能会均匀分布并分配到多个闪存Die上,从而减少磨损不均匀的发生。然而,如果磨损差异变得显著,针对特定LBA的页面重新分配到不同闪存Die以进行磨损均衡的机制可以缓解这种情况,尽管可能会影响性能。
5 评估
为了评估所提出方法的有效性和效能,我们进行了两项评估。首先,为了验证所提方案,我们模拟了在商品SSD上应用该方法的写入模式,并测量了读取性能。其次,为了检验应用程序通过所提方案能够获得的性能收益,我们在ext4文件系统和NVMeVirt SSD模拟器中实现了该方案。
5.1 我们方法的验证
要实施所提出的方案,SSD的NVMe协议栈必须修改以处理NVMe命令扩展,并调整页面与闪存Die的映射策略,以利用主机通过命令扩展提供的提示。然而,修改实际的SSD固件并不可行。因此,为了验证我们方法的有效性,我们创建了在文件碎片化和部分文件覆盖情况下,能够产生与所提方法相同的页面与闪存Die映射的写入模式。随后,我们测量了以这种方式写入的文件的读取性能。在这些实验中,我们推迟了文件系统元数据的写入,以防止其干扰闪存Die分配控制,并将日志配置为在单独的存储设备上执行。在这些实验中,我们使用了NVMe-A、NVMe-B、SATA-A和SATA-B,这些SSD均具有规则的闪存Die分配粒度和条带大小,如图8所示。
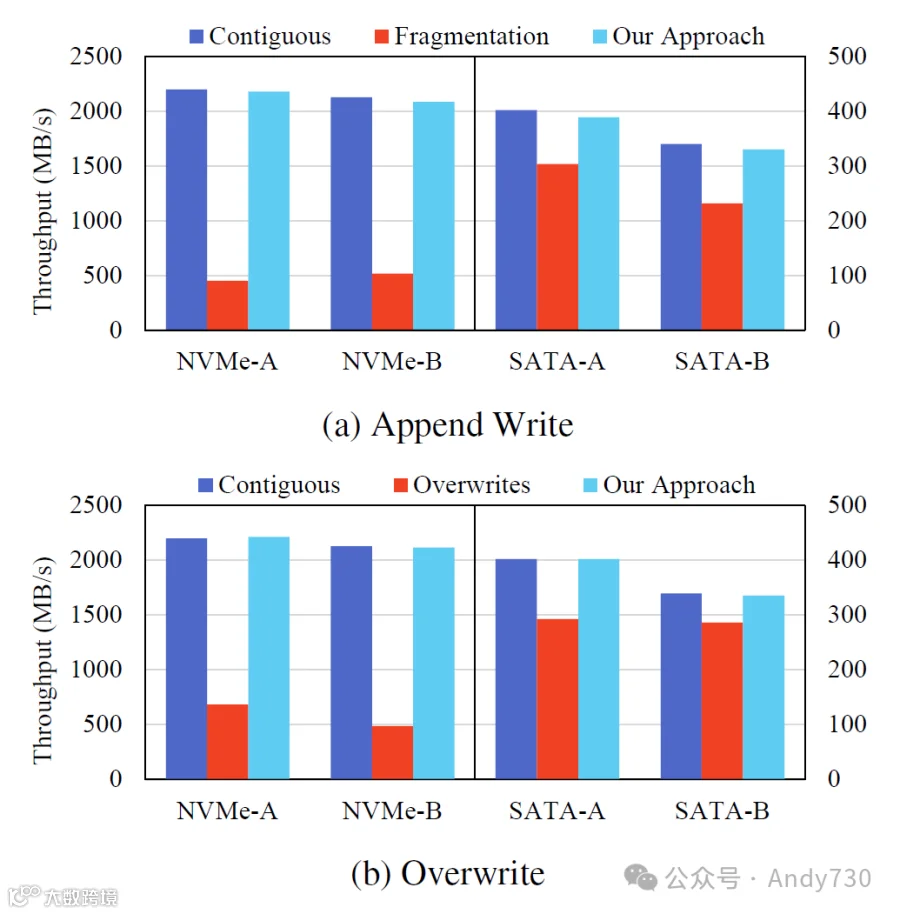 图11:四种SSD对连续文件、碎片化文件以及我们提出的方法下的碎片化文件的读取性能。
图11:四种SSD对连续文件、碎片化文件以及我们提出的方法下的碎片化文件的读取性能。
为了评估我们提出的方法在碎片化条件下的有效性,我们在FOBstate SSD上生成了一个碎片化文件并测量了其读取时间。该文件由256个大小根据SSD的闪存Die分配粒度的片段拼接而成,最终形成一个8 MB的文件。在写入每个闪存Die粒度大小的片段后,如果我们写入足够的数据填满SSD条带的剩余空间,之后再写入下一个片段,那么目标文件的所有片段将被分配到同一个闪存Die,导致显著的性能下降,这在图11中标记为“碎片化”。由于SATA SSD的闪存Die分配粒度较小,256次追加不足以达到所需的8 MB文件大小。为此,我们调整了最后一次追加的大小,以确保总文件大小为8 MB。注意,结果是只有文件的初始部分在SATA SSD中变得碎片化。
为了模拟所提出的方法,我们首先写入一个片段,然后向一个虚拟文件写入与SSD条带大小相等的垃圾数据。随后,我们将下一个片段写入目标文件。重复这一过程,如图10所示,目标文件的每个片段将位于前一个片段所在的闪存Die之后。因此,尽管在文件系统级别发生了碎片化,但在SSD内部,闪存页面将按顺序分配给连续的闪存Die。我们在反复读取已写入的碎片化文件时测量了吞吐量。
如图11a所示,NVMe SSD上碎片化文件的读取性能相比连续文件下降了79%(NVMe-A)和76%(NVMe-B)。由于该文件在NVMe SSD上以32 KB的大小进行了256次追加,因此它完全存储在一个闪存Die上。这导致在大多数读取操作中发生了闪存Die级冲突。我们认为NVMe-A的性能下降较大是因为其拥有比NVMe-B更多的闪存Die。我们的方法缓解了这一问题,性能仅比连续文件下降了2%。
对于SATA SSD,由于其较小的闪存Die分配粒度,碎片化导致的性能下降比NVMe SSD小,因为只有文件的前部发生了碎片化。尽管目标文件中碎片化的部分在SATA-A和SATA-B中分别占12.5%和50%,但与连续情况相比,其性能下降分别为27%和16%。在这两种产品中,我们的方法减少了性能下降,使其几乎达到了连续文件访问的相同水平,仅有1.2%的差异。
为了理解覆盖文件造成的页面与闪存Die映射的不对齐,以及由此导致的闪存Die级冲突引起的性能下降,我们对四种类型的SSD进行了实验。首先,我们创建了一个文件。然后,从文件的开始到结束执行256次32 KB的覆盖。最后,我们读取该文件。目标文件的大小再次设为8 MB。在连续的覆盖操作之间,我们写入大小为(条带大小 - 闪存Die分配粒度)的随机数据。
在完成一系列覆盖操作后,文件的页面将位于同一个闪存Die上,这在图11中标记为“覆盖”。请注意,即使在执行覆盖后,文件的数据块仍将在文件系统级别保持连续。
图11b显示了覆盖实验的结果。NVMe SSD的性能下降与碎片化文件相似,性能大幅下降至四分之一。然而,当应用我们的方法时,性能下降减少到与连续情况相比的平均1%。在SATA SSD的情况下,由于前述闪存Die分配粒度的差异,其性能下降较小,但仍显示出27%和16%的性能下降。然而,我们的方法成功实现了与覆盖操作前相似的性能水平。我们的方法在四种SSD上均表现出良好的效果。在我们的方法下,最大性能下降仅为SATA-B的1.2%。
通过以上分析,我们确认所提出的方法能够有效防止即使在高度碎片化文件情况下读取性能的损失,同时也成功避免了覆盖操作导致的读取性能下降。
5.2 应用工作负载的有效性
为了评估所提方法的整体有效性,我们在ext4文件系统和Linux内核的NVMe设备驱动中实现了该方案的主机端部分。这使得应用程序能够通过文件系统直接利用我们的方法。在SSD端,我们在NVMeVirt中实现了所提方案的写命令扩展和页面到闪存Die的分配机制。NVMeVirt的参数来源于表2。模拟SSD的闪存Die分配粒度设定为32 KB,条带设定为256 KB,这与NVMe-B的设置一致。为减缓碎片化的发生,ext4文件系统根据第3节中描述的实验配置进行了调整。
容量 60 GB
主机接口 PCIe Gen3 ×4
FTL L2P映射 页面映射 [1, 6]
-
通道数 4
每通道Die数 2
读/写单元大小 32 KB
读取时间 36 μs
写入时间 185 μs
-
通道速度 800 Mbps
首先,我们使用上述实现执行了基于图11所示配置的实验。与之前需要精确控制虚拟写入大小的实际SSD实验相比,该实现能够在随机偏移量交错的情况下维持最佳的闪存Die映射。这使得我们能够将分析扩展到不仅限于最坏情况,还包括更符合实际操作的情况,即在目标文件写入之间插入随机大小的虚拟写入。因此,与早期实验将文件块页面限制在单个闪存Die的做法不同,这些页面在完成追加或覆盖操作后随机分布在所有闪存Die上。
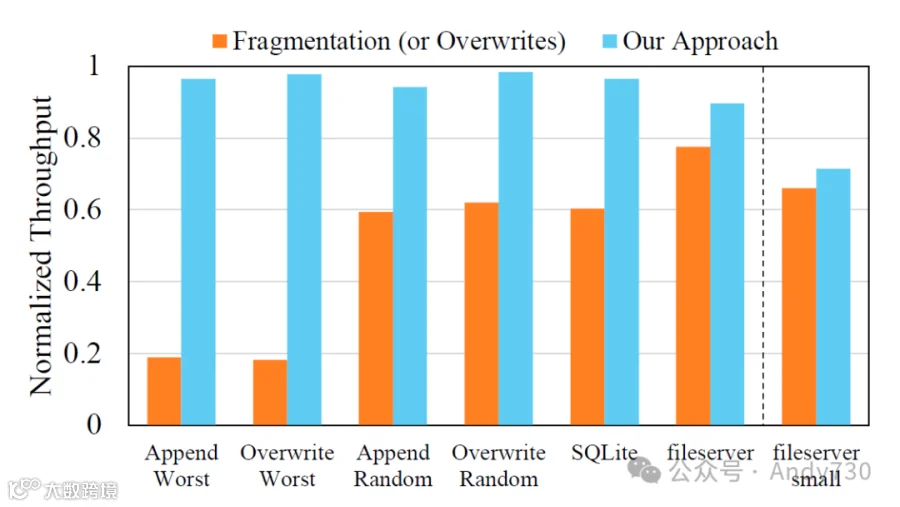 图12:在实现我们的方法的应用程序执行过程中,相对于理想的文件块和闪存页面放置的归一化读取吞吐量。
图12:在实现我们的方法的应用程序执行过程中,相对于理想的文件块和闪存页面放置的归一化读取吞吐量。
在最坏情况实验中,由于碎片化或覆盖,所有文件块被分配到单个闪存Die,结果如图12所示,与图11中的结果一致。我们观察到读取性能显著下降,碎片化文件的读取性能仅为正常吞吐量的19%,而覆盖文件的读取性能为18.2%。我们提出的方法成功保留了追加和覆盖操作后的读取性能,仅在“最坏追加”情况下下降了3.5%,在“最坏覆盖”情况下下降了2.3%。
在随机干扰实验中,目标文件写入之间的虚拟文件写入大小在32 KB粒度下随机变化,范围从32 KB到32 MB,性能下降至碎片化追加实验理想值的59.4%,覆盖实验为62%。我们的方法再次成功将读取性能下降抑制至“随机追加”情况下的5.8%,而“随机覆盖”情况下为1.6%。
除了假设的工作负载外,我们还分析了在SQLite和Filebench的fileserver工作负载下所提方法的有效性。我们在SQLite中建立了一个表并插入了10,000条每条16 KB大小的记录。同时,我们重复向一个虚拟文件追加100 KB的数据块。随后,我们执行了一次选择查询以检索从结果数据库文件中获取的所有10,000条记录,该文件的DoF为5,005。如图12中SQLite列所示,选择查询的性能仅为未执行干扰写入的情况的60%。相比之下,在我们的方法下,尽管存在虚拟写入,数据库文件块依然按预期存储在连续的闪存Die上。因此,我们观察到性能提升了1.6倍,仅比没有碎片化的情况下降了3.5%。
fileserver工作负载模拟了文件服务器的I/O模式。为此,它使用多个线程执行文件创建、随机大小的最多16 KB的追加写入、随机文件的顺序读取和文件集中的随机文件删除,文件集包含10,000个平均为128 KB的文件。为了引起更严重的文件碎片化,我们修改了工作负载,使其预分配一个由10,000个128 KB文件组成的文件集,10个线程对文件集中的随机文件进行32 KB大小的追加写入,持续1分钟并测量读取性能。我们还将文件创建和删除从工作负载中去除。在实验结束时,平均文件大小约为600 KB,平均DoF为15.7,文件集总大小为11 GB。结果显示读取性能达到了存储在连续文件块时的80%。与之前实验相比,这一性能下降较小,主要是由于多个线程同时读取,增加了未完成命令的数量。这确保了大多数闪存Die持续接收操作,提高了闪存Die级的并行性。我们的方法能够将碎片化文件的顺序读取性能恢复至理想文件放置条件的93%。
图12中的fileserver小实验是与fileserver相同设置的实验,但追加写入大小设为16 KB,低于闪存Die粒度。在此实验中,碎片化进一步降低了读取性能。当写入32 KB的数据块时,单个闪存页面(大小为32 KB)可以容纳一个写请求。然而,当写入16 KB的数据块时,两个块被组合并写入同一个闪存页面。结果,来自两个不同文件的写入可能记录在同一页面上,意味着相同大小的文件被分散存储在更多页面上。这导致在读取文件时,所需的闪存页面读取次数增加。我们确认,当一个文件使用fallocate预分配连续文件系统块,并随后以小增量填充数据以形成连续文件时,特别是如果虚拟文件的小写入介入,这一现象也会发生。这进一步证明了碎片化引起的性能下降并非直接由于碎片化,而是SSD内部数据放置的问题。
此实验凸显了所提方法的局限性。尽管其设计旨在在文件碎片化期间实现文件块的连续闪存Die分配,但并未具备抵消小规模插入写入的影响,因此文件写入可能跨越多个页面。因此,其性能提升仅为8.2%。解决闪存页面级的碎片化问题,也可能在文件系统级连续文件中出现,尤其是在写入大小小于闪存页面大小的情况下,需要一种新的页面分配策略来应对这一问题。这类研究超出了本文的范围,指向未来研究的一个有趣主题。
6 结论
与早期认为文件碎片化不会影响固态硬盘(SSD)性能的观点相悖,现已证实SSD确实会因文件碎片化而遭受显著的读取性能退化。本研究表明,这种性能退化的根本原因并非文献中所描述的请求分割(request splitting)导致的内核I/O路径延迟,而是源于SSD内部页面到闪存Die(page-to-die)映射的不对齐,从而增加了闪存Die级的冲突(die-level contention)。此外,我们证实了这种不对齐不仅在文件碎片化过程中会发生,在文件覆写时同样会出现。
为解决这一问题,我们提出了一种NVMe命令扩展,使文件系统能够向SSD提供写入操作的提示信息,并设计了一种考虑这些提示的新型页面到闪存Die映射算法。这确保了页面根据其在文件中的顺序被分配到连续的闪存Die上。因此,优化后的页面到闪存Die映射有效防止了由文件碎片化和覆写导致的额外闪存Die级冲突。
我们的评估结果表明,在不依赖代价高昂的碎片整理或文件重写的情况下,所提出的方法能有效地将碎片化或覆写文件的读取性能退化控制在仅几个百分点的范围内。这一成果为提高SSD在面对文件碎片化和频繁覆写场景下的性能提供了新的解决思路。
参考资料:Yuhun Jun, Shinhyun Park, Jeong-Uk Kang, Sang-Hoon Kim, and Euiseong Seo. We Ain’t Afraid of No File Fragmentation: Causes and Prevention of Its Performance Impact on Modern Flash SSDs. In Proceedings of the 22nd USENIX Conference on File and Storage Technologies (FAST 24), Santa Clara, CA, February 2024.
---【本文完】---
近期受欢迎的文章:
更多交流,可加本人微信
(请附中文姓名/公司/关注领域)
