
LMCache 架构概览
LMCache 是一个专为大语言模型(LLM)服务引擎设计的 KV Cache 管理系统,旨在通过高效的缓存机制降低 Time-To-First-Token (TTFT) 并提高系统吞吐量。
本文档简要介绍了 LMCache 的核心架构及其主要组件。
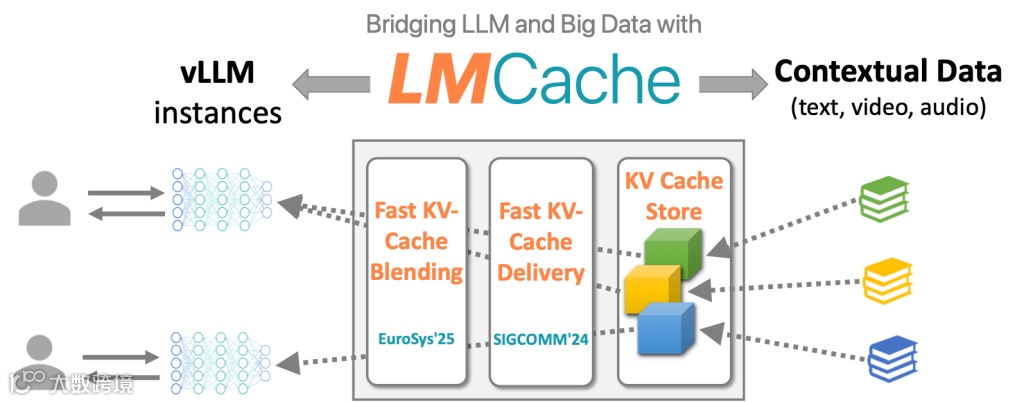
1. 高层系统架构 (High-Level System Architecture)
LMCache 通过扩展 LLM 推理引擎(如 vLLM),构建了一个跨越 GPU 显存、CPU 内存以及磁盘/远程后端的多层级 KV Cache 存储系统 (Multi-Tier Storage Architecture)。
1.1 多层级存储 (Multi-Tier Storage)
-
• GPU Memory: 保存当前正在使用的活跃 KV Cache 工作集。 -
• CPU DRAM: 作为“热缓存”层,使用 pinned memory 实现高效的 GPU-CPU 传输。 -
• Local Storage (本地磁盘/NVMe): 提供大容量的本地缓存层。 -
• Remote Storage (Redis, Mooncake, S3): 提供持久化的远程共享存储。
1.2 两种运行模式 (Two Modes)
LMCache 主要支持两种运行模式,分别对应不同的应用场景:
-
1. 存储模式 (Storage Mode): 侧重于 KV Cache 的卸载与复用(Offloading and Reusing)。通过将不常用的 KV Cache 卸载到 CPU/磁盘/远程后端,并在需要时重新加载,从而显著提高 Cache 命中率。 -
2. 传输模式 (Transport Mode): 侧重于分布式推理中的预填充-解码分离(Prefill-Decode Disaggregation)。通过点对点(P2P)通道在节点间低延迟传输 KV Cache,实现计算与存储的解耦。
2. 详细组件架构 (Detailed Component Architecture)
3. 主要组件说明
3.1 推理引擎进程内组件 (In-Process Components)
这些组件直接运行在推理引擎(如 vLLM)的进程空间内,与推理引擎共享内存和资源。
3.1.1 LMCacheConnector
角色:连接器 / 适配器
代码位置:lmcache/integration/vllm/lmcache_connector_v1.py
LMCacheConnector 是 LMCache 与推理引擎(如 vLLM)之间的桥梁。它作为 vLLM 的一个插件运行,拦截 KV Cache 的相关操作。
-
• 功能: -
• 拦截:拦截 vLLM 的 KV Cache 生成和读取请求。 -
• 转换:将 vLLM 的内部 KV Cache 格式(如 PagedMemory)转换为 LMCache 的通用格式。 -
• 转发:将请求转发给核心的 LMCacheEngine处理。
深入分析可参考:LMCacheConnector 源码分析
3.1.2 LMCacheEngine
角色:核心引擎
代码位置:lmcache/v1/cache_engine.py
LMCacheEngine 是整个系统的核心,负责协调所有的缓存操作。
-
• 功能: -
• 生命周期管理:管理 KV Cache 的存储、检索和预取。 -
• GPU 交互:通过 GPUConnector高效地在 GPU 和 CPU 之间传输数据。 -
• 策略执行:决定何时将数据写入后端存储,或从后端存储加载数据。 -
• 事件管理:处理异步 I/O 事件。
深入分析可参考:LMCacheEngine 源码分析
3.1.3 TokenDatabase
角色:元数据索引
代码位置:lmcache/v1/token_database.py
TokenDatabase 维护了 Token 序列与 KV Cache Key 之间的映射关系。
-
• 功能: -
• 索引:根据输入的 Token 序列(Prompt)计算并查找对应的 Cache Key。 -
• 树状存储:通常采用 Radix Tree 等数据结构高效存储 Token 前缀。
3.1.4 GPUConnector
角色:显存适配器
代码位置:lmcache/v1/gpu_connector.py
GPUConnector 负责处理不同推理引擎(如 vLLM)特有的显存格式(如 PagedAttention)与 LMCache 通用内存格式之间的转换与传输。
-
• 功能: -
• 格式转换:将非连续的 Paged Memory 转换为连续的内存块(或反之)。 -
• 数据传输:执行 GPU <-> CPU 之间的高效内存拷贝(D2H / H2D)。
3.1.5 StorageManager
角色:存储管理
代码位置:lmcache/v1/storage_backend/storage_manager.py
StorageManager 负责管理分层存储架构(Hybrid Storage Hierarchy)。
-
• 功能: -
• 分层管理:自动管理 L1(本地 CPU 内存)、L2(本地磁盘)和 L3(远程存储)之间的数据流动。 -
• 内存分配:负责 CPU 内存缓冲区的分配和回收。 -
• 后端抽象:通过统一的接口与不同的存储后端(如 Redis, LocalDisk, Mooncake 等)交互。
深入分析可参考:Hierarchical Storage 源码分析
3.1.6 LMCacheWorker
角色:控制代理
代码位置:lmcache/v1/cache_controller/worker.py
LMCacheWorker 运行在推理引擎进程内部(作为 LMCacheEngine 的一部分),是 Cache Controller 在本地的代理。
-
• 功能: -
• 通信:通过 ZMQ 与远端的 Cache Controller保持长连接。 -
• 执行:接收并执行来自 Controller 的指令(例如,将某段 KV Cache 从本地发送到另一个实例)。 -
• 上报:向 Controller 上报本地的缓存状态和心跳。
3.1.7 RuntimePluginLauncher
角色:插件启动器
代码位置:lmcache/v1/plugin/runtime_plugin_launcher.py
RuntimePluginLauncher 负责在 LMCache 生命周期中加载和管理外部插件,允许用户通过自定义脚本扩展系统功能。
-
• 功能: -
• 插件加载:根据配置扫描并启动指定目录下的 Python 或 Shell 插件脚本。 -
• 生命周期管理:确保插件进程随主进程启动和退出。 -
• 环境注入:向插件注入当前 Worker ID、Role 等上下文信息。
3.2 独立服务进程 (Independent Service Processes)
这些组件作为独立的操作系统进程运行,通常部署在单独的容器或节点上,为多个推理实例提供服务。
3.2.1 Cache Controller (lmcache_controller)
角色:控制平面(Control Plane)
代码位置:lmcache/v1/cache_controller/
Cache Controller 是一个独立的进程,负责管理整个 LMCache 集群的元数据和控制流。
-
• 功能: -
• 全局视图:维护集群中所有 KV Cache 的位置信息。 -
• 指令下发:向各推理实例的 LMCacheWorker发送指令(如lookup,pin,move,clear)。 -
• 负载均衡:在多实例部署中调度 KV Cache 的迁移和复用。 -
• 接口暴露:提供 RESTful API 或 gRPC 接口供外部系统调用。
3.2.2 LMCache Server (lmcache_server)
角色:数据平面(Data Plane) - 默认远程存储后端
代码位置:lmcache/v1/server/__main__.py
LMCache Server 是 LMCache 自带的一种轻量级远程存储服务,用于跨机共享 KV Cache。它在架构上与 Mooncake Store、Redis 等第三方存储后端处于同一层级。
-
• 注意:它只是众多远程存储后端的一种。用户可以根据需求选择使用 LMCache Server、Mooncake Store或Redis等作为远程存储。 -
• 功能: -
• 作为后端:为 StorageManager提供远程存储能力,支持 KV Cache 的存取。 -
• 默认实现:提供了一个基于 TCP 的简单实现,适用于没有部署复杂存储系统(如 Mooncake/Redis)的场景。 -
• 接收与提供数据:响应推理实例的读写请求,进行 KV Cache 的传输。
3.2.3 Controller Dashboard
角色:可视化监控看板
代码位置:lmcache/v1/cache_controller/frontend/
Controller Dashboard 是一个基于 Web 的可视化界面,用于监控 LMCache 集群的实时状态。
-
• 功能: -
• 集群监控:展示所有连接的 LMCache 实例及其状态(CPU/GPU 缓存使用率)。 -
• Worker 管理:查看各 Worker 的详细信息和连接状态。 -
• 实时指标:提供系统核心指标(如 QPS、命中率等)的图表展示。 -
• 访问方式:通常通过 Controller 启动时的监控端口(如 9001)访问。
4. 共享模式
LMCache 支持两种主要的 KV Cache 共享模式,用户可以根据基础设施条件灵活选择:
4.1 集中式共享 (Centralized Sharing) - 对应 Storage Mode
在此模式下,所有推理实例都连接到一个统一的共享存储后端(Shared Storage Backend),形成 Hub-and-Spoke(星型)架构。
-
• 核心机制:数据中心化存储。所有的 KV Cache 数据写入和读取都必须经过中心存储节点。 -
• 后端选项: -
• LMCache Server:LMCache 自带的轻量级存储服务器,支持 TCP/RDMA。 -
• Redis:通用的内存数据库,适合小规模或测试环境。 -
• Mooncake Store:高性能分布式存储,支持大规模集群。 -
• 工作流程: -
1. 写入:实例 A 生成 KV Cache 后,将其推送到中心存储后端。 -
2. 存储:中心存储后端持久化或在内存中保存该数据。 -
3. 读取:实例 B 需要该数据时,从中心存储后端拉取。 -
• 优势: -
• 架构简单:易于部署和理解。 -
• 数据持久化:中心存储通常具备更好的持久化能力,实例宕机不影响数据可用性。 -
• 解耦:生成者和消费者不需要同时在线。 -
• 劣势:中心存储节点容易成为网络带宽瓶颈,且存在单点故障风险。 -
• 适用场景: -
• 多轮对话上下文共享:用户在不同时间发起的请求被路由到不同实例。 -
• 跨实例复用公共前缀:如共享 System Prompt 或长文档背景。 -
• 非实时共享:对延迟要求不极端的场景。
4.2 点对点共享 (P2P Sharing) - 对应 Transport Mode
在此模式下,推理实例之间直接进行 KV Cache 数据的传输,无需经过中心化的存储后端。这是实现预填充-解码分离(Prefill-Decode Disaggregation)的核心架构。
-
• 核心机制:采用控制面与数据面分离的设计。 -
• 控制面: Cache Controller仅负责维护全局元数据(即 KV Cache 的 Key 与存储位置的映射关系),充当“目录服务”,不存储实际数据。 -
• 数据面:实际的 KV Cache 数据由 LMCacheWorker在推理实例之间通过网络直接传输。 -
• 关键组件: -
• Cache Controller:负责元数据管理和节点发现。 -
• LMCacheWorker:负责实例间的连接建立和数据传输。 -
• 工作流程: -
1. 注册:实例 A 生成 KV Cache 后,向 Controller 注册:“我持有 Key X”。 -
2. 查询:实例 B 需要 Key X 时,向 Controller 查询:“谁持有 Key X?”。 -
3. 定位:Controller 返回元数据:“Key X 位于实例 A”。 -
4. 传输:实例 B 直接与实例 A 建立连接并拉取数据,数据流不经过 Controller。 -
• 优势:消除了中心化存储的带宽瓶颈,充分利用集群内部的高速网络(如 RDMA),适合大规模分布式推理场景。 -
• 注意:此模式无需部署 LMCache Server,但必须部署Cache Controller。 -
• 适用场景: -
• 预填充-解码分离 (Prefill-Decode Disaggregation):Prefill 实例生成 KV Cache 后,需要极低延迟地传输给 Decode 实例。 -
• 跨实例上下文迁移 (Context Migration):在负载均衡或故障恢复时,将活跃的 KV Cache 从一个实例“流转”到另一个实例。 -
• 大规模集群内数据路由:避免单一中心节点成为瓶颈。
5. 典型工作流
5.1 Offload (写入流程)
当推理实例(如 vLLM)完成 Prefill 阶段或进行 KV Cache 驱逐时:
-
1. 捕获 (Capture): LMCacheConnector拦截 KV Cache 数据。 -
2. 传输 (Transfer): LMCacheEngine通过GPUConnector将数据从 GPU 显存高效传输到 CPU 内存。 -
3. 存储 (Storage): StorageManager根据配置策略(如 L1/L2 分层)将数据写入对应的存储后端: -
• 本地后端: 写入 LocalCPUBackend(内存) 或LocalDiskBackend(磁盘)。 -
• 远程后端: 发送至 RemoteBackend(连接LMCache Server或Mooncake Store)。 -
4. 发布 (Publish): (仅 P2P 模式) LocalCPUBackend通过LMCacheWorker异步通知Cache Controller:“我持有该数据 Key”,从而更新全局元数据。
5.2 Reuse (读取流程)
当新请求到达推理实例时:
-
1. 哈希 (Hashing): LMCacheConnector根据 Prompt 计算 KV Cache 的 Key (Hash)。 -
2. 查找 (Lookup): LMCacheEngine向StorageManager查询数据位置: -
• 本地查找: 检查本地内存或磁盘。 -
• 远程/P2P 查找: 若本地未命中,通过 P2PBackend查询Cache Controller(获取持有该数据的对端地址) 或查询RemoteBackend。 -
3. 拉取 (Retrieval): -
• 命中本地: 直接从内存/磁盘读取。 -
• 命中远程: 从 LMCache Server下载。 -
• 命中 P2P: LMCacheWorker与持有数据的对端实例建立连接,直接拉取数据。 -
4. 加载 (Load): 数据被加载回 CPU,再通过 LMCacheEngine传输回 GPU 显存。 -
5. 解码 (Decode): vLLM 引擎复用 KV Cache,跳过 Prefill 计算,直接开始 Decode 阶段。