
文本处理一般包括词性标注,句法分析,关键词提取,文本分类,情感分析等等,这是针对中文的,如果是对于英文来说,只需要基本的tokenize。本文为大家提供了以下这些工具包。
1.Jieba
【结巴中文分词】做最好的 Python 中文分词组件
其功能包括支持三种分词模式(精确模式、全模式、搜索引擎模式),支持繁体分词,支持自定义词典等。


代码主页:https://github.com/fxsjy/jieba
2.NLTK
【NLTK】一个构建Python程序以使用人类语言数据的领先平台,被称为“使用Python进行教学和计算语言学工作的绝佳工具”,以及“用自然语言进行游戏的神奇图书馆”。
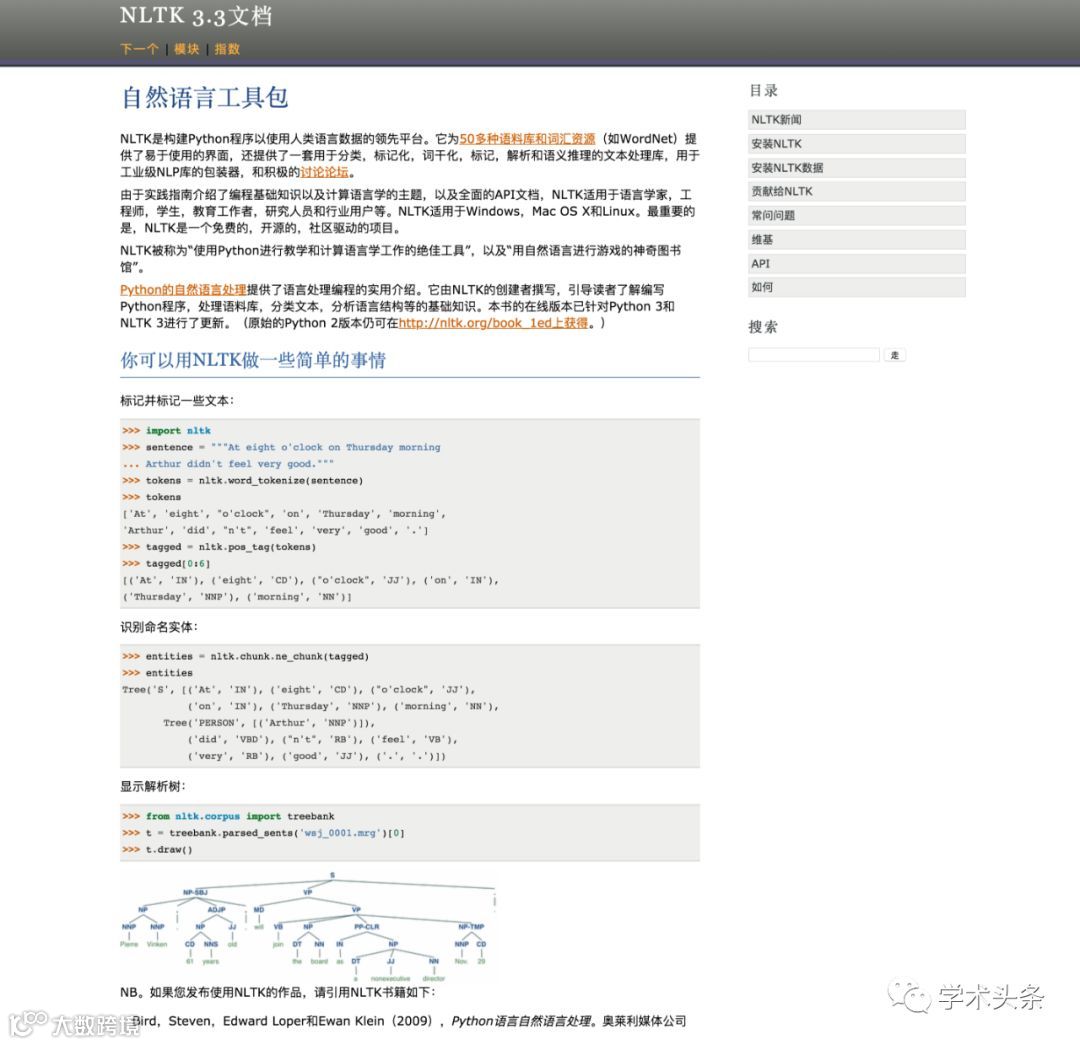

官方主页:http://www.nltk.org/
代码主页:https://github.com/nltk/nltk
3.TextBlob
【TextBlob】是一个用于处理文本数据的Python(2和3)库。它为潜入常见的自然语言处理(NLP)任务提供了一个简单的API,例如词性标注,名词短语提取,情感分析,分类,翻译等。
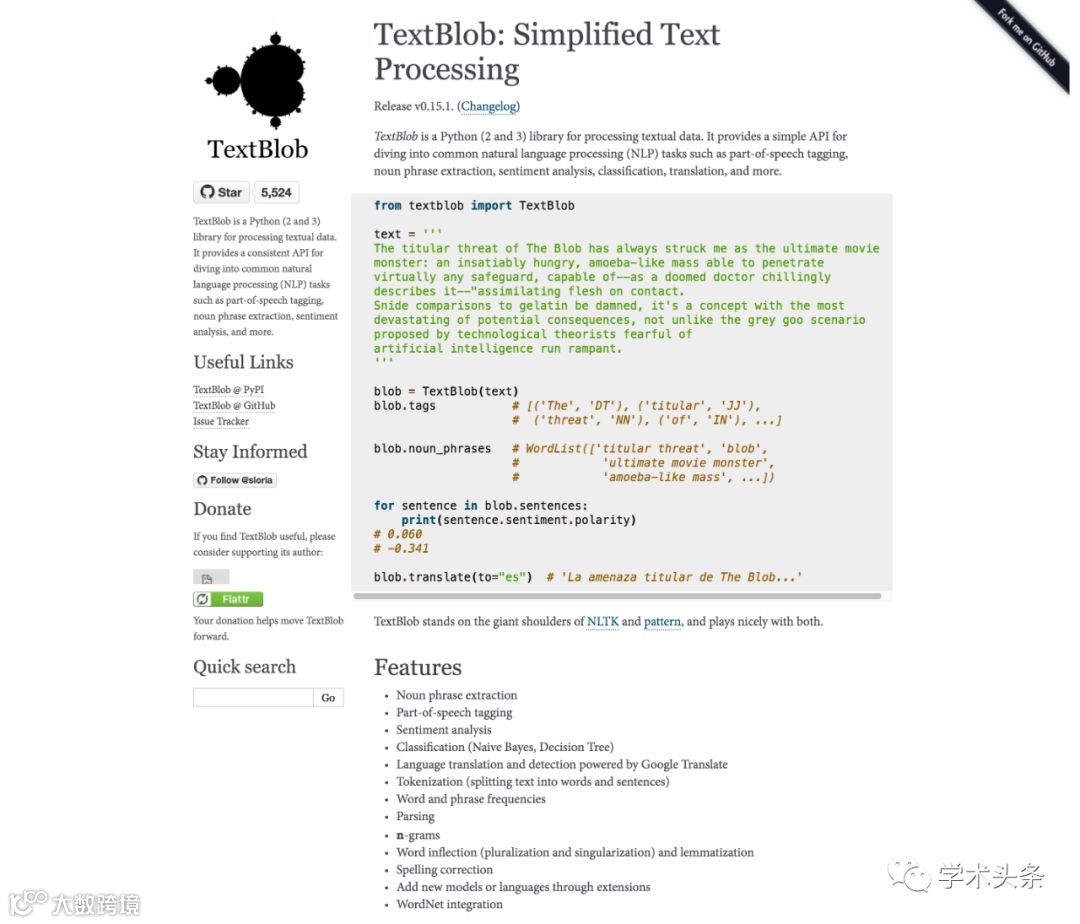
官方主页:http://textblob.readthedocs.org/en/dev/
代码主页:https://github.com/sloria/textblob
4.MBSP for Python
【MBSP】是一个文本分析系统,基于CLiPS和ILK开发的基于TiMBL和MBT内存的学习应用程序。它提供了用于标记化和句子分裂,词性标注,分块,词形还原,关系查找和介词短语附件的工具。


官方主页:http://www.clips.ua.ac.be/pages/MBSP
5.Gensim
【Gensim】是一个免费的Python库
可扩展的统计语义
分析纯文本文档的语义结构
检索语义相似的文档


官方主页:http://radimrehurek.com/gensim/index.html
代码主页:https://github.com/piskvorky/gensim
6.langid.py
【langid.py 】是一个独立的语言标识(LangID)工具。接受过97种语言的预训练(ISO 639-1代码),培训数据来自5个不同的来源:JRC-Acquis、ClueWeb 09、维基百科、路透社RCV2和Debian i18n。
代码主页:https://github.com/saffsd/langid.py
7. xTAS
【 xTAS】是基于Celery的分布式文本分析套件。部分xtas使用GPL许可软件,例如Stanford NLP工具,以及可能产生额外限制的数据集,检查文档中的各个功能。

代码主页:https://github.com/NLeSC/xtas
8.Pattern
【Pattern】是Python编程语言的Web挖掘模块。它具有数据挖掘工具(谷歌,Twitter和维基百科API,网络爬虫,HTML DOM解析器),自然语言处理(词性标注,n-gram搜索,情感分析,WordNet),机器学习(矢量)空间模型,聚类,SVM),网络分析和

官方主页:http://www.clips.ua.ac.be/pattern

您可在后台回复“人脸识别”获取《人脸识别研究报告》。
回复“强化学习”获取105篇强化学习论文列表。
回复“物理学奖”获取"2018诺贝尔物理学奖"官方PDF。
回复“医学奖”获取"2018诺贝尔生理学或医学奖"官方PDF。
回复“信息学会”,可获取由中国中文信息学会发布的《2018知识图谱发展报告》。

后台回复如下对应关键词可获取研究报告(菜单栏可直接下载)
自动驾驶
机器翻译
机器人
行为经济学
区块链
通信
自然语言处理
计算机图形学
超级计算机
3D打印
智能机器人
人脸识别
关注我们
你想要的科技资讯都在这

戳阅读原文访问AMiner官网