

AMiner平台(https://www.aminer.cn)由清华大学计算机系研发,拥有我国完全自主知识产权。平台包含了超过2.3亿学术论文/专利和1.36亿学者的科技图谱,提供学者评价、专家发现、智能指派、学术地图等科技情报专业化服务。系统2006年上线,吸引了全球220个国家/地区1000多万独立IP访问,数据下载量230万次,年度访问量超过1100万,成为学术搜索和社会网络挖掘研究的重要数据和实验平台。
贝叶斯优化(Bayesian optimization,BO)是一种顺序设计策略,用于对不采用任何功能形式的黑箱功能进行全局优化。它通常用于优化昂贵的评估功能。
近年来深度神经网络大火,可是神经网络的超参选择一直是一个问题,由于这个原因,贝叶斯优化开始被好多人用来调神经网络的超参,在这方面BO最大的优势是sample efficiency,也就是BO可以用非常少的步数(每一步可以想成用一组超参数来训练你的神经网络)就能找到比较好的超参数组合。另一个原因是BO不需要求导数,而正好一般情况下神经网络超参的导数是求不出来的。这两个原因导致BO成为了很好的调超参的方法。
根据AMiner-NeurIPS 2020词云图和论文可以看出,与Bayesian optimization是在本次会议中的热点,下面我们一起看看Bayesian optimization主题的相关论文。

1.论文名称:Multi-Fidelity Bayesian Optimization via Deep Neural Networks
论文链接:https://www.aminer.cn/pub/5f05939091e011c57e3e8c79?conf=neurips2020
简介:贝叶斯优化(BO)是优化黑盒功能的流行框架。在许多应用中,可以以多种保真度评估目标函数,以在成本和准确性之间进行权衡。为了降低优化成本,已经提出了许多多保真度BO方法。尽管取得了成功,但这些方法要么忽略要么过分简化了逼真度之间的强而复杂的相关性,因此在估算目标函数方面可能效率不高。为了解决这个问题,我们提出了深度神经网络多保真贝叶斯优化(DNN-MFBO),它可以灵活地捕获保真度之间的各种复杂关系,从而改善目标函数估计,从而提高优化性能。我们使用顺序的,逼真度的高斯-赫尔姆正交和矩匹配来实现基于互信息的采集功能,该功能在计算上易于处理且高效。我们在合成基准数据集和工程设计的实际应用中展示了我们方法的优势。

论文链接:https://www.aminer.cn/pub/5ee3525f91e011cb3bff70de?conf=neurips2020
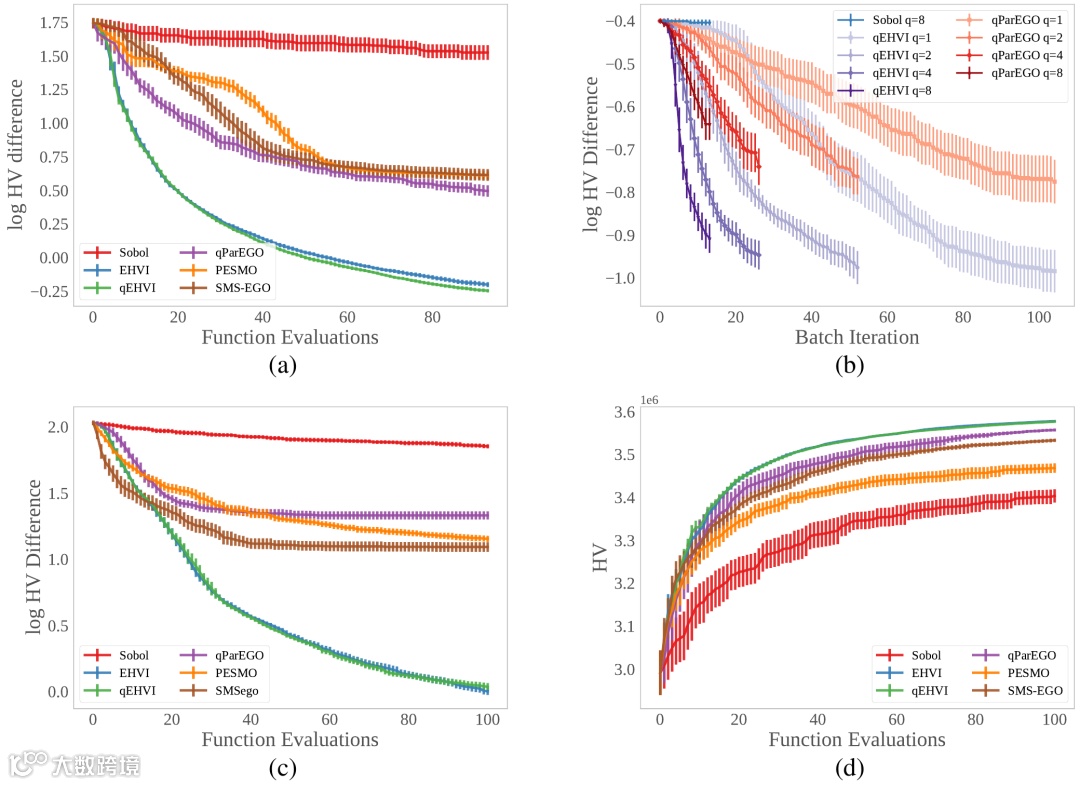
简介:在许多现实世界中,决策者都试图以样本有效的方式有效地优化多个竞争目标。多目标贝叶斯优化(BO)是一种常见的方法,但是许多现有的获取函数没有已知的解析梯度,并且存在较高的计算开销。我们使用预期超量改进(EHVI)来利用多目标BO的编程模型和硬件加速方面的最新进展-众所周知,该算法具有很高的计算复杂性。我们导出了q预期超量改进(qEHVI)的新公式,该函数将EHVI扩展到并行的受限评估设置。qEHVI是新的q新候选点的联合EHVI的精确计算(直至Monte-Carlo(MC)积分误差)。尽管以前的EHVI公式依赖于无梯度采集优化或近似梯度,但我们通过自动微分计算MC估计量的精确梯度,从而能够使用一阶和准二阶方法进行有效而有效的优化。最后,我们的经验评估表明,qEHVI在许多实际情况下都具有计算上的可控性,并且在短时间内节省了最先进的多目标BO算法。
论文链接:https://www.aminer.cn/pub/5d8898013a55acdc5ca089c0?conf=neurips2020
简介:深度(增强)学习系统的成功关键取决于正确选择超参数,超参数众所周知是敏感的,并且评估成本很高。训练这些系统通常需要在多个时期或情节上运行迭代过程。尽管可以轻松获得学习曲线的中间信息,但传统方法仅考虑超参数的最终性能。在本文中,我们提出了一种贝叶斯优化方法,该方法利用学习算法的迭代结构来进行有效的超参数调整。首先,我们将每条训练曲线转换为数字分数。其次,我们使用来自曲线的辅助信息有选择地扩充数据。此扩充步骤可提高建模效率,同时防止在添加整个曲线时出现高斯过程协方差矩阵的病态问题。我们通过调整超参数来训练深度强化学习代理和卷积神经网络,证明了我们算法的效率。我们的算法在最短的时间内识别出最佳超参数的性能优于所有现有基线。

论文链接:https://www.aminer.cn/pub/5f7fdd328de39f0828397b62?conf=neurips2020
简介:贝叶斯优化(BO)是一种优化昂贵的评估黑盒功能的杰出方法。诸如手机之类的边缘设备的强大计算能力,再加上对隐私的关注,引起了人们对联合学习(FL)的浓厚兴趣,该联合学习的重点是通过一阶优化技术对深度神经网络(DNN)进行协作训练。但是,一些常见的机器学习任务(例如DNN的超参数调整)无法访问梯度,因此需要零阶/黑盒优化。这暗示了将BO扩展到FL设置(FBO)的可能性,以便代理可以在这些黑盒优化任务中进行协作。本文介绍了联邦Thompson抽样(FTS),该抽样原则上克服了FBO和FL的许多关键挑战:我们(a)使用随机傅立叶特征来近似BO中使用的高斯过程替代模型,该模型自然产生以下参数: (b)基于Thompson抽样设计FTS,这大大减少了要交换的参数数量,并且(c)提供了对异构代理具有鲁棒性的理论收敛保证,这在FL和FBO。我们从通信效率,计算效率和实际性能方面经验证明了FTS的有效性。

论文链接:https://www.aminer.cn/pub/5f7fdd328de39f0828397b1d?conf=neurips2020
简介:本文开发了一种直接作用于原始字符串的贝叶斯优化(BO)方法,提出了BO循环中字符串内核和遗传算法的首次使用。 由于需要将输入映射到一个平滑且不受约束的潜在空间中,因此阻碍了BO在字符串上的最新应用。 学习此预测需要大量计算和数据。 相反,我们的方法基于字符串内核构建了一个强大的高斯过程替代模型,自然支持可变长度输入,并针对具有语法约束的空间执行了高效的获取函数最大化。 实验表明,在广泛的约束条件下,与现有方法相比,优化效果得到了显着改善,包括流行的设置,其中语法由上下文无关的语法控制。



阅读原文,直达“NeurIPS2020”会议专题,了解更多会议论文!