

2024年7月16日至19日,以“重塑:数字遗产新质生产力”为主题的2024文化遗产保护数字化国际论坛在北京中关村国际创新中心成功举办,大会开设了历史城镇、人工智能、数字石窟寺、考古遗址、三山五园等多个学术专场,带来了近百篇精彩的学术报告。
7月17日,在人工智能专场上,北京通用人工智能研究院研究科学家陈以新受邀发表学术报告,本文将发言进行整理刊发如下,供大家学习交流。

从精确到泛化--
数字资产的三维重建技术研究

一、引言
人工智能技术已经被应用到了各行各业,在文化遗产方面也有非常多的应用,包括文化遗产的监测和分类工作,操控无人机或者机器人对建筑进行非接触式的观测,以及一些建筑模型的部件分割工作(图 1)。图2是机器学习或者人工智能技术应用到文化遗产领域的经典案例,这个案例是以滕王阁为对象的应用研究,相较于之前在普通和简单的场景下的三维分割研究,其目的是分割斗拱等复杂建筑构件,带来了非常多的新应用前景的启发。

图 1 文化遗产领域人工智能技术应用

图 2 滕王阁建筑模型结构分割案例(来源: Haiyang et al. THU. OmniSeg3D: Omniversal 3D Segmentation via Hierarchical Contrastive Learning. CVPR2024)
三维重建技术为数字资产赋能,重点分为从以下两个方面。第一个是怎样通过密集的多视角图像,捕捉以及重建三维几何信息。第二个是怎样提升三维重建技术的泛化性,泛化性的提升主要是得益于现在的以数据为依托的学习方法。
二、精确:多视角图像的三维重建
2.1 NeRF技术的出现
从视觉或者是图像输入来恢复它的三维几何是一个源远流长的领域,这个领域在图形学和计算机视觉领域,2020年又达到了一个新的高潮,得益于之前的NeRF技术;基于输入的图像,我们会去优化它的内部的特征,结果在各个视角渲染得到非常好的图像。

图 3NeRF渲染技术流程(图片来源: Ben et al. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. ECCV 2020)
例如下图(图 4),如果我们能够通过视觉输入,可以达到在任何、任意视角的渲染,非常多的应用可以因此受益。它可以提升计算机对于场景的理解程度,帮助三维资产的展示、理解、应用等方面,达到下一个技术的爆发点。

图 4NeRF渲染技术效果(来源:Video credit: Jonathan et al. Zip-NeRF: Anti-Aliased Grid-Based Neural Radiance Fields. ICCV 2023)
2.2 NeRF技术原理
NeRF技术利用了神经体渲染技术。渲染其实是求解图像上的每一个像素的颜色,也就是从相机原点发射出的射线上所对应的颜色。跟之前传统的渲染技术相比,NeRF用的是体渲染方法。这种渲染方式是连续的、可微的,两个特性使它方便进行机器学习,可以直接利用输入图像进行隐式表征的学习;最后用神经网络作为场景的表征,而不是更传统具体三维表征,如格栅化、网格化的表征;三维中每一个空间点,通过神经网络,依靠其自己的跟场景有关的特征(Scene properties)进行神经体渲染。
以上介绍的是利用三维的隐式表征(Implicit Surfaces)做渲染的技术流程,还有各种技术,可以获取三维的几何结构以及纹理特征;这些技术通过三维的隐式表征得到渲染特征,通过渲染特征变换得到几何特征。通过类似的技术就能够真正获取可交互的具有实体的三维网格模型特征。
2.3.通用人工智能研究院技术探索
通用人工智能研究院也进行了一些探索,主要侧重的方向是利用物理仿真器来优化生成结果。既往的方法只利用图片的信息,以及一些额外例如深度、辐射量、物体分割之类的表征。但传统方法在恢复三维空间的时候,会出现非常多的问题,这些问题导致最后得到的三维表征不稳定。如果把这样的三维表征放到了现实或者仿真环境中都会出现不稳定的情况,这也对我们接下来的应用提出了很大的挑战。因此,我们提出要在机器学习的过程中接入跟物理有关的特性的生成方法,利用物理仿真器获取额外信息,以此帮助进行更好的优化。

图 5 传统方法与应用了物理仿真器生成结果的对比
利用这样的优化方法,就可以从多视角的输入出发,真正重建一个符合物理约束的三维场景。物理重建不仅提升了重建的效果,而且也可以使重建的场景真正被泛化到一些真实的场景以及仿真器中,帮助训练机器人做一些类似于抓取和放下这样的操作。


图 6 生成场景在仿真器中辅助机器人训练动作
三、泛化:通过数据驱动学习增强的方法
从多视角、视频中进行重建的工作,可以形成非常高质量的重建成果,训练和渲染也是非常高效的,但是它的缺点在于重建需要非常密集视角的图像素材。换句话说就是你看不到的地方,那你就不知道它到底是长什么样子的;这个要求在一些图像、绘画领域,以及一些建筑的观测工作中,完整密集视角的图像素材其实是不存在的的,只有一些非常少量视角的图像,甚者对于文化遗产来说,有时候只有一张图片,并没有完整密集视角的图像素材;怎样利用相关的技术,能在更加现实的场景中利用少量的图像达到更好的效果,提升重建的精度,提高重建工具的泛化性,就成了一个新的研究工作方向。
3.1 现有数据集概况
泛化重建技术目前主要依靠的是数据驱动的方式来进行架构,回顾一下现在有一些非常高质而且大规模的数据集,在物体领域,Objaverse有80万个三维物体,OpenAI在2022年公布的一项研究里面也利用了一个有几百万个三维物体的数据集;之后Objaverse又进行了进一步地扩展,现在有超过1000万个三维物体;在三维场景方面,我们北京通用人工智能研究院推出了有6.1万个三维家居场景的数据集,同时也有针对城市方面的建模数据搜集,包括英国伦敦、中国及世界各地的城市,使得做出来的数据库可以真正写实的包括城市里面所有的资产。
3.2 针对泛化性验证及研究
有了这些大规模的数据就可以进一步验证方法的泛化性。目前提升泛化性主要是针对下面几个领域:一个是针对单张图像,可以去想象这个物体或者它描述的东西从另外一个角度看它到底是什么样子;二是能不能从单张图像恢复一个三维的几何模型资产;最后一个就是只通过一个文本,能不能得到比较好的几何模型资产。
在第一个方面,比如输入是一个单张的RGB图像,想象图像中的物体它在另外一个视角是什么样子的,(图 7)的案例是先驱性的工作。但是这项研究工作是在物体级别进行的,北京通用人工智能研究院近期则在场景级研究如何从单张图像生成另一视角图像的问题,由于场景中物体之间的会产生遮挡,并且存在多个物体之间的相互作用,包括支持的相互作用,因此不可能对场景中的每一个物体进行单独的操作,而需要对场景中多个物体整体进行操作,这都是物体级别建模所无法达到的(图 8)。
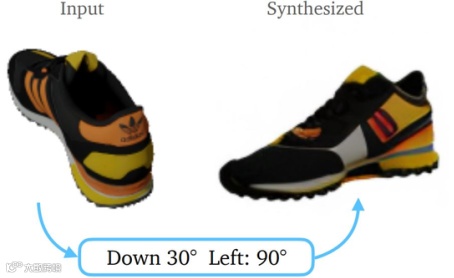

图 7 物体级别的单视角到其他视角重建(来源:R. Liu et al. Zero1-to-3)

图 8 场景级别的单视角到其他视角图像重建(来源:Y. Chen et al. Scene 1-to-3)
研究院针对单一视角图像,借助渲染技术得到三维表征的工作,也进行了研究工作(图 9),证明了通过数据驱动的方法,可以实现从比较少的观测信息当中恢复出比较精细的几何和纹理的信息。

图 9 少量观测信息生成三维表征研究成果比较(来源:Y. Chen et al. Single-view 3D Scene Reconstruction with High-fidelity Shape and Texture)
以下是现在各相关领域专业人员做的一些研究案例(图10)。左上角的案例是通过输入一张图像获得三维的信息,产生的成果有这个形状,但是并不精确。右边是两个例子是通过输入一个文本得到既有几何也有纹理特征的三维表征研究案例;这项技术应用在人物形象、卡通形象或者是比较新颖的一些物体的生成上,都表现出了比较好的效果。

图 10 图像、文本生成三维资产研究案例
四、总结
总结来说,从精确到泛化的各类不同场景,以现有技术对于文化资产的生成能力来说,现有情况总结如下:
1.现有的方法可以给做到从图像输入来恢复数字资产,可以为相关工作提供便利,但有需要较为密集完整视角图像的苛刻条件。
2.在稀疏观测的情况下,利用数据驱动的方法恢复生成三维几何和特征已经展现出了一些发展前景,这一方向还需进一步的研究。
3.未来发展方向:①第一个是研究如何对精确和泛化进行有机结合。怎样能够确保生成的数字资产符合我们观测信息,以及在观测不到信息的场景下,如何通过数据驱动,利用数据中学到的先验信息帮我们进行补全。②第二是关于场景的研究方向。目前大部分方法在单个物体上是可行的,怎样把类似的方法扩展应用到包含各种物体,或者前景、背景的复杂现实场景中;以及怎样使技术真正运用在各类场景中来发挥它的作用,也是之后的研究问题。
4.人工智能与更广泛领域(如文化遗产保护)的融合潜力巨大,这将激发创新解决方案和协作实践的新契机。一方面广泛的各领域可以给AI技术提出更多的需求,AI技术也可以以更多的方式从应用中汲取不同的场景,帮助技术的提升。

中国古迹遗址保护协会数字遗产专委会 | 秘书处
ICOMOS-CHINA Scientific Committee of Cultural Heritage Conservation by Digitalization | Secretariat
裴唯伊 杜寇
邮箱:peiweiyi@thid.cn ;dukou@thid.cn
电话:15010082521 18074104213
