
一张梦露照片:

风情万种的梦露

优雅得体的梦露

一张蒙娜丽莎画像:

话痨的蒙娜丽莎

焦虑的蒙娜丽莎

一张爱因斯坦照片:

委屈的爱因斯坦

跟人扯皮的爱因斯坦

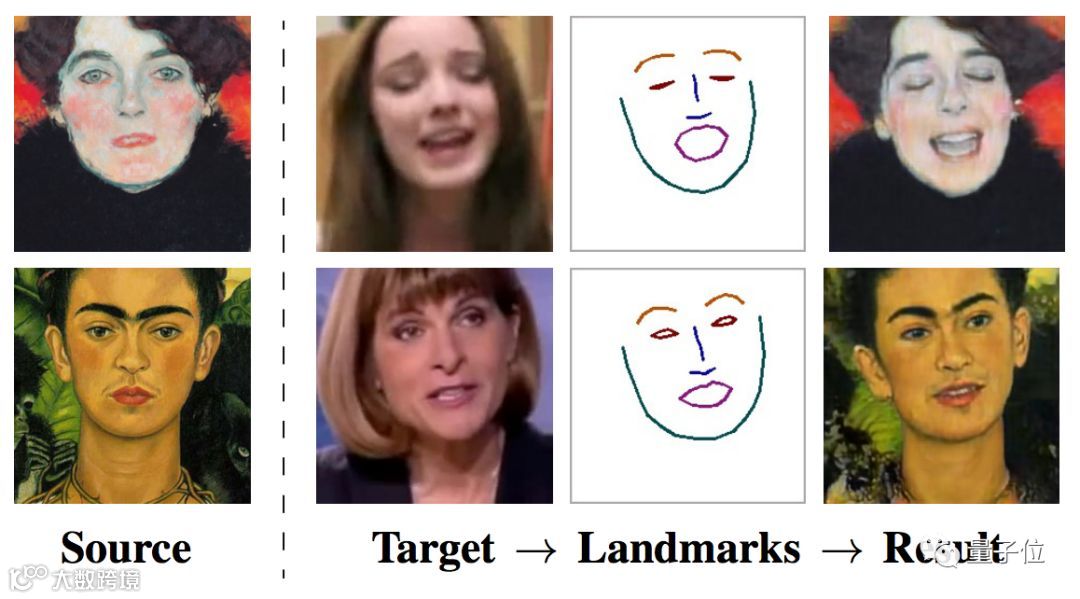
是的,所有这一切,只需要一张图,无论是照片还是油画,只要有一张人像,都能立马动起来,照片变真人。
而且,你想用什么表情控制它,就可以用什么表情控制它。

甚至,控制画风鬼畜一点的人像也没问题。
当然,你要是觉得一张图出来的效果破绽比较明显,也可以用八张同一个人的照片,比如这个胡须男:

然后照着另一个人说话的视频

就可以生成胡须男做出一样动作的视频

或者十六张照片:
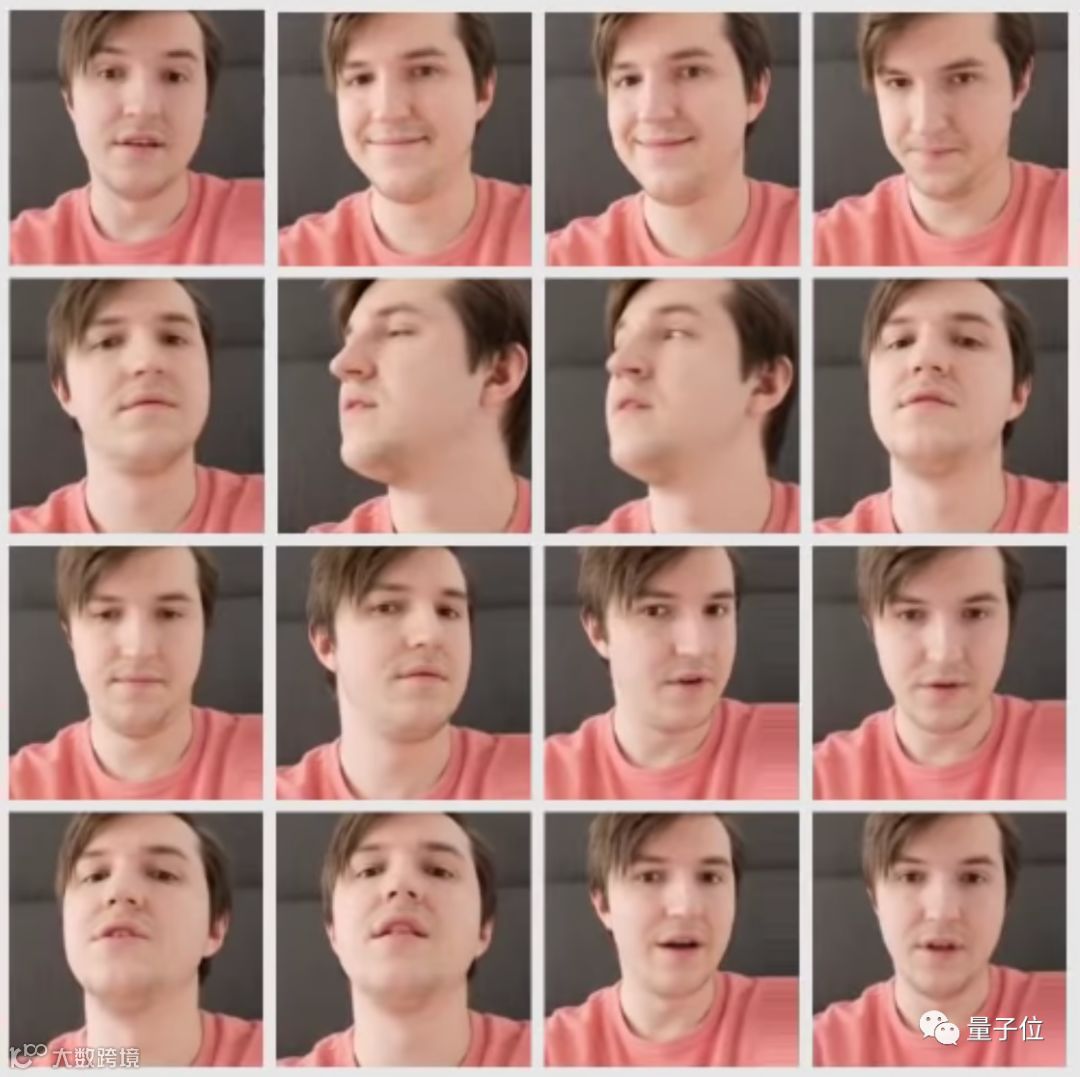
生成的效果长这样,几乎看不出bug了。

这项研究来自三星和俄罗斯斯科尔科沃科学技术研究所,堪称目前最强换脸神器,Deepfakes被拍在沙滩上,瑟瑟发抖。
甚至有人觉得,这已经完全可以“商用”了,拿来忽悠人什么的,压根区分不出来。
保持警惕,谨防新型电信诈骗。
还有人已经陷入恐慌,觉得这类技术已经弊大于利了。
有人认为这类技术可以停止研究了。

不知道是觉得太可怕,还是觉得换脸技术已经走到了终极?
当然,也有乐观主义者。

这么超现实的风格,简直让人想去买三星手机。

可以拿家里老照片来拍电影了~
放博物馆里好使啊!想想历史人物的画像能动起来,给我们做自我介绍多有趣。
嗯,这位朋友可能参观过故宫。

怎么实现
研究团队用到了元学习(meta learning),结合VoxCeleb1和VoxCeleb2两个视频数据集,将面部图像通过嵌入式网络映射到嵌入向量。
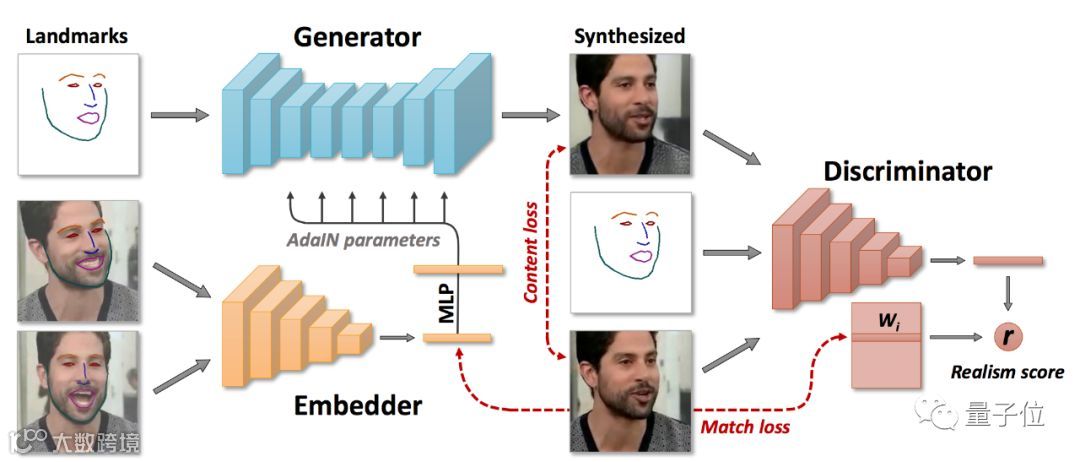
生成器网络通过卷积层集将面部特征输入映射到输出帧中,之后,通过嵌入器传递来自同一视频的帧集,平均得到的嵌入并使用它们来预测生成器的自适应参数。
然后,通过生成器传递不同帧的坐标,将得到的图像与人脸实际情况进行比较。
传送门
论文:
Few-Shot Adversarial Learning of Realistic Neural Talking Head Models
Egor Zakharov, Aliaksandra Shysheya, Egor Burkov, Victor Lempitsky
https://arxiv.org/abs/1905.08233
视频:
https://www.youtube.com/watch?v=p1b5aiTrGzY&feature=youtu.be
作者系网易新闻·网易号“各有态度”签约作者

来源:量子位,如有侵权联系删除。
一实科技(科技牛)专注于为企业精准匹配科研专家,快速提供技术解决方案,如果您有企业遇到技术难题、寻求转型升级,点击文末“阅读原文”填写技术需求反馈表,我们将有专业对口的项目人员为您提供全程专业化服务。
诚邀您入驻科技牛产学研平台
挖技术/问专家/就上科技牛
▼

识别二维码下载科技牛APP