
复旦、字节等推出多环境强化学习智能体框架 AgentGym-RL
首个统一端到端架构支持交互式多轮训练,7B模型性能追平顶尖商业模型
人工智能正从“数据密集”迈向“经验密集”时代。强化学习之父 Richard Sutton 指出,真正的智能源于在真实环境中主动探索与持续积累经验的能力。特斯拉前AI负责人、OpenAI联合创始人Andrej Karpathy进一步强调,环境的多样性与真实性是智能体实现泛化决策的关键基础。
在此背景下,复旦大学、创智研究院与字节跳动的研究团队基于AgentGym框架,提出全新多环境强化学习智能体训练框架——AgentGym-RL。该框架由复旦大学自然语言处理实验室博士生奚志恒担任第一作者,桂韬教授和张奇教授为通讯作者。
AgentGym-RL 是**首个无需监督微调(SFT)、具备统一端到端架构、支持交互式多轮强化学习训练**的LLM智能体框架,并已在多种真实场景中验证其有效性,为自主智能体的发展提供了标准化基础设施。
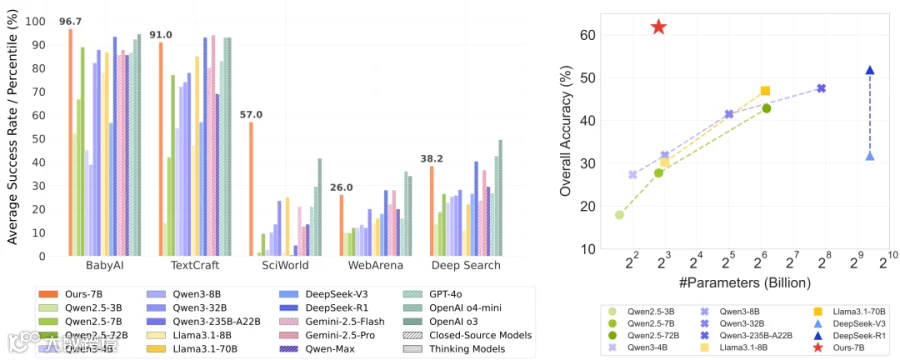
商业模型、开源模型及本文强化学习模型在不同智能体任务中的表现对比。
创新范式:扩展环境交互(Scaling Interaction)
研究团队提出“扩展环境交互”作为测试时计算的新路径,通过增加模型与外部环境的交互回合数,使智能体在多轮反馈中逐步优化决策策略。相比传统仅延长思维链的方法,该方式打破封闭推理局限,实现动态修正与结构化决策,显著提升复杂任务应对能力。
针对长轮次训练易导致模型崩溃的问题,团队进一步提出ScalingInter-RL交互轮次扩展策略:采用分阶段递增最大交互轮次的方式,让智能体先掌握基础技能,再逐步挑战复杂任务,有效平衡探索与利用,构建稳定训练范式。
实验成果:7B模型超越百B级开源模型,对标顶级商业模型
实验表明,仅7B参数规模的模型在五类真实任务环境、26项测试任务中展现出卓越性能:
- 在网页导航任务中,ScalingInter-7B准确率达26.00%,大幅超越GPT-4o(16.00%),媲美DeepSeek-R1与Gemini 2.5 Pro;
- 在科学实验任务中,其总体得分达57.00%,远超OpenAI o3(41.50%),创下当前最优成绩。
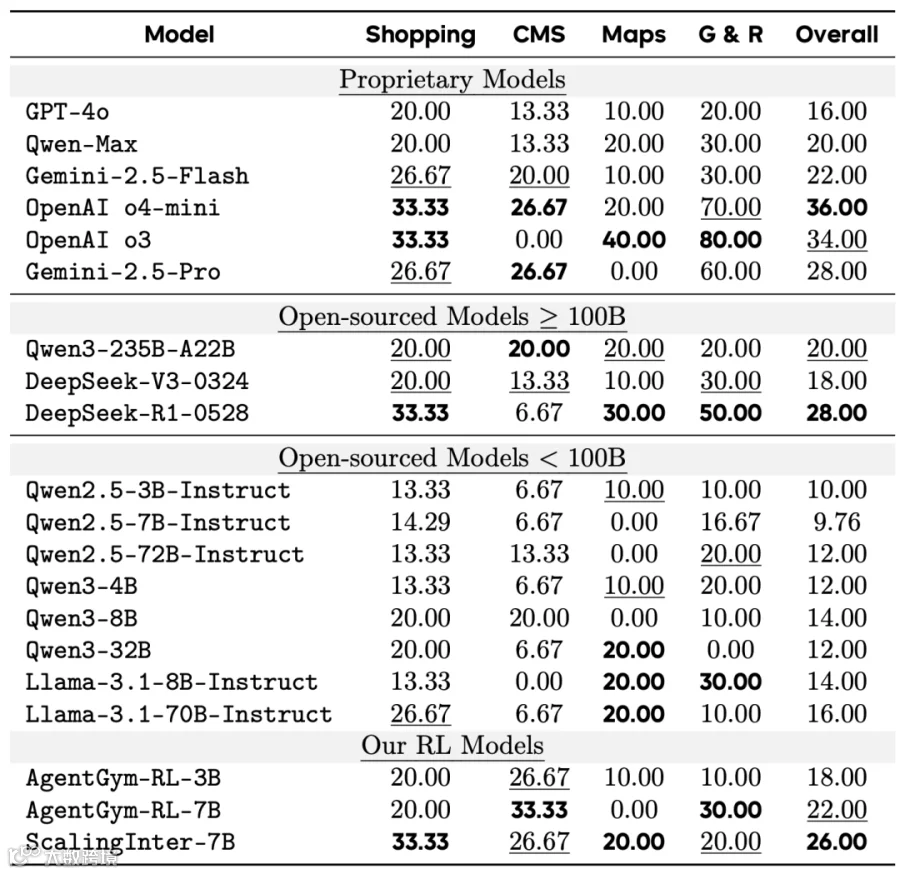
WebArena环境下的实验结果。
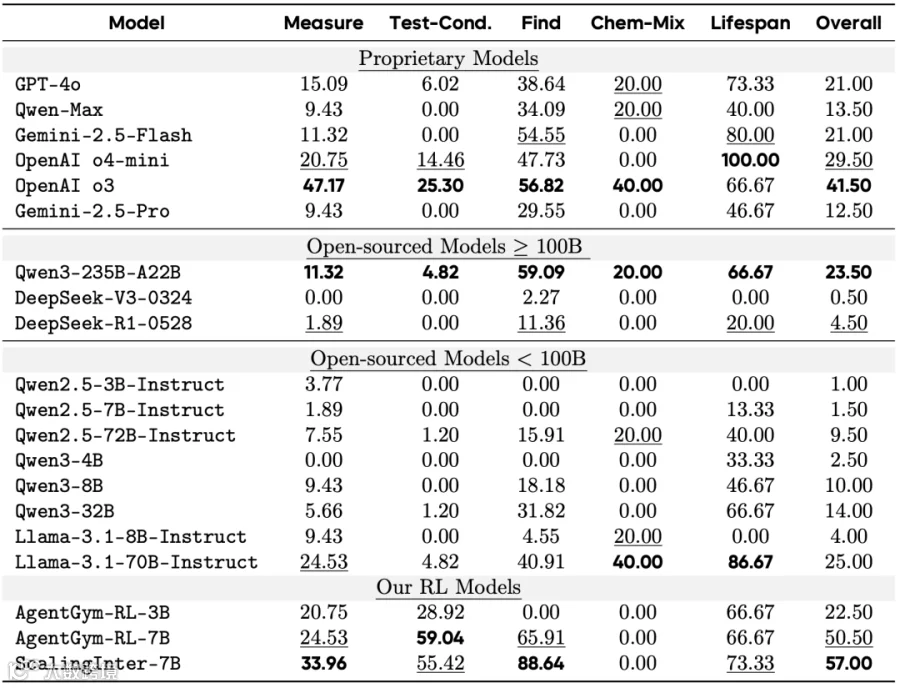
SciWorld环境下的实验结果。
框架设计:模块化、可扩展、兼容主流算法
AgentGym-RL采用解耦化架构,包含环境、代理与训练三大模块:
- 环境模块:支持并行服务调用,涵盖网页导航、深度搜索、文字游戏、具身控制、科学探索五大类场景;
- 代理模块:封装LLM与环境交互逻辑,支持提示工程、采样配置及自我反思机制;
- 训练模块:集成PPO、GRPO、REINFORCE++、RLOO等主流在线强化学习算法,支持分布式训练与课程学习。
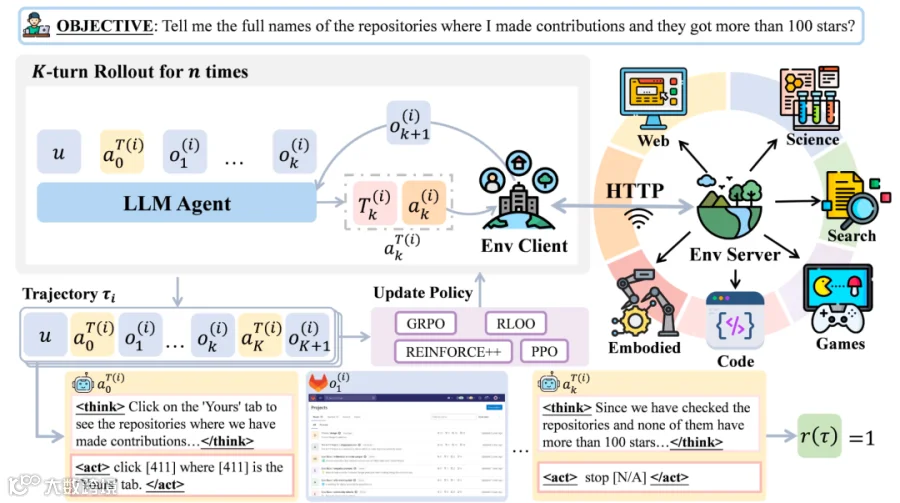
AgentGym-RL架构图:灵活性与可扩展性兼备。
核心优势:训练更稳、效率更高、缩放潜力更大
ScalingInter-RL在训练稳定性与效率方面显著优于传统方法:
- 奖励值持续上升,而固定轮次模型在150步后衰减32%;
- 在TextCraft任务中,以传统方法60%的步数达成89%成功率;
- WebArena任务中单位计算量性能增益为PPO的1.8倍。
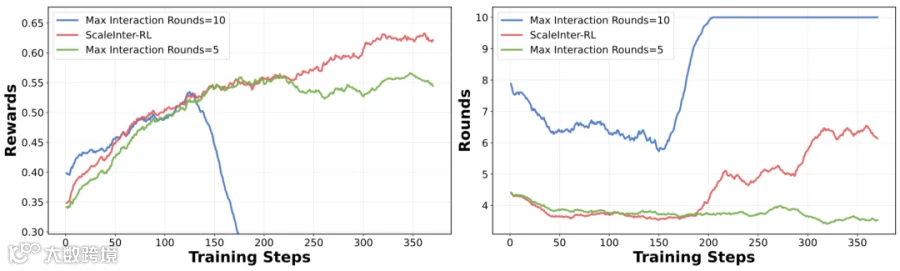
ScalingInter-RL与传统RL算法训练动态对比。
研究揭示关键洞察:后训练与测试时计算的投资比单纯扩大模型参数更具性价比。经AgentGym-RL训练的7B模型不仅超越同类开源模型,还显著优于近十倍参数的大型模型。
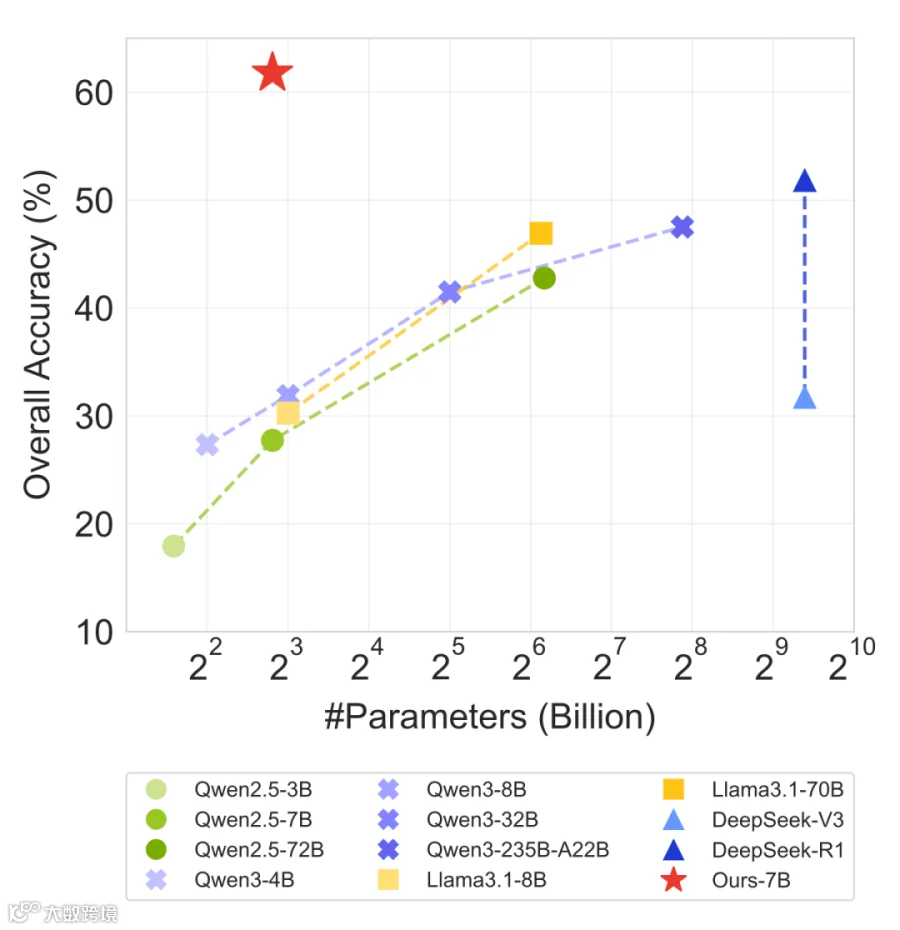
本文框架显著提升7B模型能力,超越更大规模模型。
未来方向:迈向通用、复杂与协同的智能体时代
研究团队指出,环境结构对强化学习效率有显著影响:规则明确、反馈清晰的环境(如TextCraft、BabyAI)提升明显,而开放性环境(如WebArena)仍面临挑战。
未来将聚焦三大方向:
- 通用能力升级:突破领域壁垒,提升跨环境与未知工具适应能力;
- 复杂场景拓展:向机器人操作、现实规划等长周期任务延伸;
- 多智能体协同:探索群体决策与协作机制。
AgentGym-RL已全面开源,项目地址:https://agentgym-rl.github.io,代码地址:https://github.com/WooooDyy/AgentGym-RL。
本研究获得华为昇腾AI处理器算力支持。昇腾910B NPU在多个实验阶段发挥作用,结合vllm-ascend框架,显著提升大模型在国产算力平台上的推理效率。