
2026年1月5日 3℃ 今天下班很早,最近没有加班。中午看到一篇斯坦福的文章,关于超长视频问题,觉得还不错,下班回到家仔细看了一下。
Pretraining Frame Preservation in Autoregressive Video Memory Compression

言归正传,回到论文。
别看标题拗口,它解决的是一个让无数开发者头秃的难题:如何让AI像人类一样记住超长视频的所有细节,而不至于变成“金鱼脑”。
先来说说背景。现在的AI视频模型,比如Sora、Veo这些当红炸子鸡,生成短视频还行,但一遇到长视频就露怯。问题出在“上下文长度”上:模型需要把历史视频帧作为参考,但帧数一多,内存就爆炸。想象一下,你让一个快递小哥送包裹,他每次只记得最近几单,远处的包裹全忘光,这配送链肯定乱套。传统方法比如滑动窗口或压缩编码,要么切掉历史帧导致剧情断裂,要么压缩过头丢失细节,好比把高清电影压成马赛克动图。
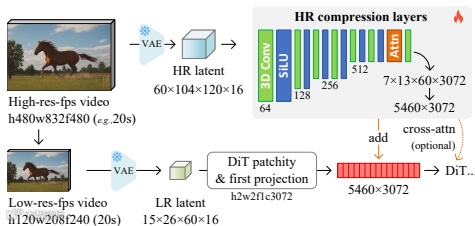
这篇论文的逆天之处在于,它给模型装了个“超级压缩硬盘”。作者设计了一种神经网络结构,能把长达20秒的视频压缩成一个只有约5000个token的短上下文,同时还能任意检索出历史帧的高频细节。这就像把一整部电影塞进一个U盘,随时能调出任意一帧的高清画面。

核心方法分两步走。第一步是“预训练”:让模型学习一个压缩任务,随机从长视频中挑帧并尝试重建,逼它掌握细节保留的秘诀。作者用了个巧妙的随机掩码策略,防止模型作弊——比如只记住结尾帧糊弄事。这训练就像让AI参加记忆力大挑战,随便抽考一帧都得答对。

第二步是“微调”:把预训练好的压缩模型作为内存编码器,接入主流视频扩散模型(如Wan或HunyuanVideo),实现长历史自回归生成。架构上,作者用了轻量级的3D卷积和注意力层,避免重计算开销。这波操作相当于给模型加了外挂,让它在生成新帧时能随时查阅压缩版历史笔记。
实验结果更是炸裂。在消融测试中,他们的方法在PSNR和SSIM指标上秒杀基线模型,比如4x4x2压缩率下PSNR达到17.41,而传统方法只有12.93。视觉对比显示,即使高压缩下,人物面部、服装纹理等细节依然清晰,而其他方法已糊成一片。

更绝的是,这套框架还能灵活扩展。比如加个滑动窗口,能让单镜头连续生成;或者用交叉注意力增强一致性,对付超市货架排列这种魔鬼细节。用户评测的ELO分数也证实,它在内容一致性上表现黑科技级别。

总的来说,这篇论文把上下文长度与质量的权衡问题玩出了花。它让长视频生成不再是土豪公司的专利,普通玩家用消费级显卡也能搞出电影级连贯剧情。这波操作不仅给自回归模型打了强心剂,还可能催生下一波AI短视频应用的狂欢。各位看官觉得这技术能颠覆行业吗?欢迎在评论区聊聊你的脑洞。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。