
![]()
点击上方蓝色字关注
▲交点AI▲
引言
在数据分析的世界里,“置信区间”听起来既高深又神秘,但它却是我们日常决策背后的隐形助手。无论是科研实验、市场调研,还是医疗诊断,置信区间都在告诉我们:“你的数据有多可靠?”
置信区间是不是越窄越好?
95%置信水平究竟意味着什么?
多次实验后,置信区间真的包含了真实值吗?
这些疑问今天一次性为你解答!通过通俗易懂的讲解和直观的图示,我们将带你轻松理解置信区间的奥秘,让数据的“不确定性”变得透明可控。
看完本文,数据分析的核心逻辑你就掌握了!
如何理解置信区间?
以样本均值为例,置信区间的计算公式如下:
其中,
决定置信区间大小的因素
置信水平:
较高的置信水平(如99%)意味着区间更宽。
较低的置信水平(如90%)则区间更窄。
样本量:
样本量越大,标准误越小,置信区间越窄。
样本量越小,不确定性增加,置信区间变宽。
数据变异性:
数据的标准差越大,置信区间越宽。
数据变异性越小,置信区间越窄。
置信区间的图解
下图帮助直观理解置信区间:

图1: 宽置信区间 vs 窄置信区间
左图:宽区间(较高置信水平,或样本量少)。
右图:窄区间(样本量大,或变异性低)。
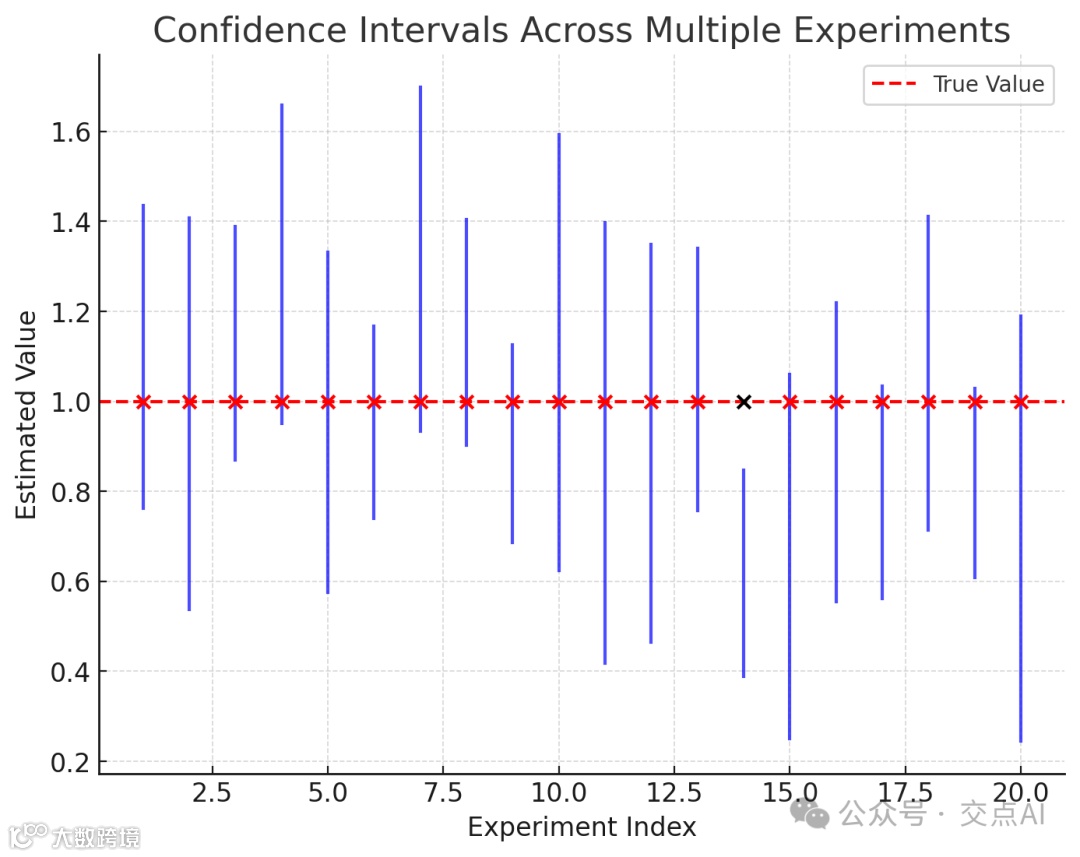
图2: 多次实验的置信区间分布
蓝线段代表每次实验的置信区间范围。
红色虚线表示真实值(假设为1)。
注意:95%的置信区间包含真实值(红点),但也有5%的置信区间未包含真实值(黑点),体现了置信水平的定义。
区间估计结果的解读
区间的宽度:
宽区间:说明估计的不确定性较高,可能因为样本量少或数据变异性大。
窄区间:表明估计的精确性较高,通常样本量大或数据稳定。
置信水平:
95%的置信水平意味着:若重复实验多次,约95%的置信区间会包含真实值,5%可能会偏离。
结果解读:
置信区间是范围估计,而非确定值。
不保证单次实验的区间一定包含真实值。
置信区间的应用场景
科学研究:
在医学、心理学、工程学中用于衡量实验结果的不确定性。比如,研究药物疗效时估计其平均效果的区间。
商业分析:
用于预测市场趋势或估计客户行为的范围。比如,预测销售额的可能范围。
机器学习:
用于评估模型性能的置信范围。比如,模型预测准确率的95%置信区间为 [85%, 90%]。
置信区间的注意事项
样本代表性:
置信区间依赖样本数据,若样本偏差大,区间可能不准确。
区间并非概率:
区间本身不是概率值,而是基于假设的推断范围。
结果的依赖性:
区间的可信度与研究假设和数据质量直接相关。
常见误解
置信区间包含真实值的概率:
实际上,置信区间是基于统计方法估计出的范围,单个区间无法直接描述包含真实值的概率。
区间越宽越可靠:
宽区间确实包含更多可能性,但可能由于数据不充分而导致不可靠。
与标准误混淆:
标准误描述的是单个样本统计量的波动性,而置信区间描述总体参数的可能范围。
总结
置信区间是统计推断中的重要工具,它为实验数据提供了更全面的信息,避免仅依赖点估计的局限性。通过结合置信水平、样本量和数据特性,置信区间能够帮助我们更准确地理解实验结果,同时也提醒研究者关注数据质量和实验设计的合理性。


