
大数据相关技术发展到今天,日趋成熟,包括数据抽取,传输,流式计算,存储,可视化等方面,但是,对于每一项具体实现技术,有自身的优点,也存在局限。具体的架构方案,一旦上线,再进行替换,成本非常高,如果要平滑迁移,代价更加巨大。
典型技术栈如下图:
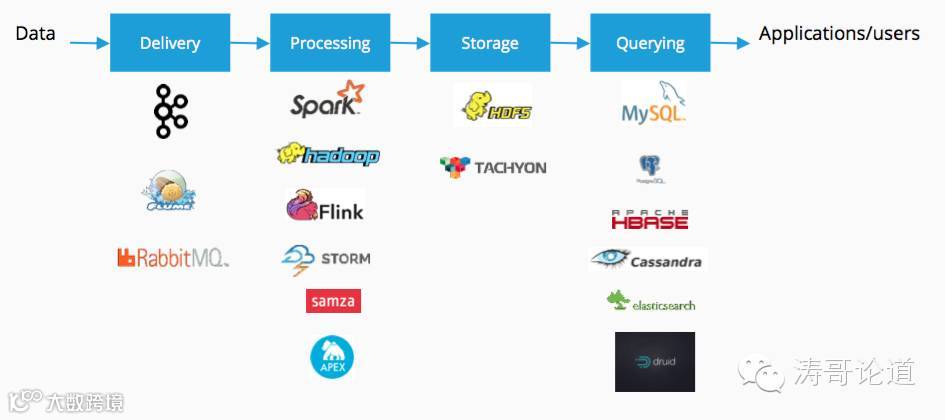
因此,我们在研发大数据应用系统的时候,不应该是先选择技术方案,更糟糕的是照抄大公司的解决方案,再进行产品设计。合理的做法是根据应用的场景,进行分析,然后,再选择对应的技术方案。
进行应用场景分析,我们优先考虑两个维度,实时性和一致性,这样就会有四个应用场景,实时强一致,实时弱一致,离线强一致,离线弱一致,对于每个场景,有各自适应的业务。也不是实时性越强,一致性越强就是最好,因为,实施需要的技术难度最高,所花费的成本也是最大。
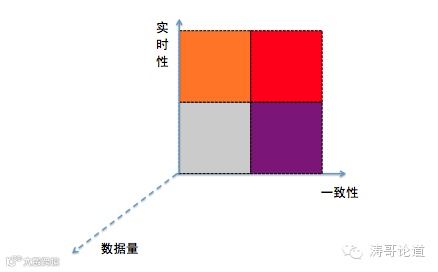
实时&强一致场景:这个在大数据技术成熟之前,是非常棘手的,但是,现在解决方案已经比较成熟了。典型应用是生产系统的实时监控,例如实时生产量,各个生产环节差异量等,其实是作为生产系统的一部分。利用当前主流的大数据处理架构是可以解决的,例如线上生产库binlog实时读取,Kafaka进行数据传输,Spark进行流式计算,ES进行数据存储等。如果利用传统的ETL抽取方案来解决,频繁对生产数据库进行抽取,并不是可行的方案,因为,这样会极大的影响线上OLTP系统的性能。还可以举一个生产系统实时监控案例,架构方案是应用系统完成写数据库的同时,把内容通过消息发送,后面的大数据处理系统接收消息来进行处理,这个架构方案,对于实时性某种程度上可以保障,但是,也存在效率问题,但是,对于强一致性就非常不合适了,因为消息系统如ActiveMQ等不仅无法保障消息数据不能丢失,而且对应消息顺序也是无法保障,项目实施后,虽然采取了很多补救措施,也无法满足强一致性需求,不得不重起炉灶。
实时&弱一致性场景:典型的应用场景是消息通知,例如电商的全程跟踪消息,如果个别数据出现丢失,对于用户的影响并不大,也是可以接受的,因此,可以采用更加廉价的解决方案,应用完成对应的动作后,将消息发出即可,使用方订阅对应的消息,按照主键,如订单号,存储即可。
离线&强一致场景:这是典型的大数据分析场景,也就是众多的离线报表模式。从技术上,传统的ETL抽取技术也能满足要求,数据仓库对应的技术也能够解决。
离线&弱一致场景:对于抓取互联网数据,日志分析等进行统计系统,用于统计趋势类的应用,可以归为此类,这类应用主要是看能够有足够廉价的方案来解决,是不是可以巧妙的利用空闲的计算资源。这个在很多公司,利用晚上空闲的计算资源,来处理此类的需求。
以上讨论的都是大数据应用,也就是从数据量大的应用场景。但是,对应现实中很多数据处理系统来讲,例如很多B2B业务系统,或者传统行业,其实是数据量并大,那么采用更加廉价的OLTP的方法,例如复制读库等,也是可以完成对应的工作的。
因此,架构设计应当针对具体应用场景的,满足当前业务的发展需求,可以考虑两年的需求,最合适的架构就是最好的,而不存在放之四海都是最好的架构设计。不分析清楚自己的应用场景,盲目照抄大公司的技术架构,显然也是不合适的。当然,如果选择的架构本身,不能满足应用场景的需求,后续,不论进行多少补救,依然无法满足需求,并且,架构会变得异常复杂,替换的成本也将是非常高昂,不得不慎重。