
摘要:检索增强生成(RAG)技术已被证明在整合最新信息、减轻幻觉以及提高响应质量方面非常有效,特别是在专业领域。尽管已经提出了许多通过查询依赖的检索来增强大型语言模型的RAG方法,但这些方法仍然存在实现复杂和响应时间延长的问题。通常,一个RAG工作流涉及多个处理步骤,每个步骤都可以以各种方式执行。在这里,我们研究了现有的RAG方法及其潜在的组合,以确定最佳的RAG实践。通过广泛的实验,我们建议了几种平衡性能和效率的部署RAG的策略。此外,我们展示了多模态检索技术可以显著提高关于视觉输入的问题回答能力,并通过“检索即生成”的策略加速多模态内容的生成。资源可在https://github.com/FudanDNN-NLP/RAG获取。

一、研究背景
研究问题:这篇文章要解决的问题是如何在检索增强生成(RAG)技术中实现最佳实践,以提高生成内容的质量和可靠性,特别是在专业领域中。
研究难点:该问题的研究难点包括:RAG方法的复杂实现和延长响应时间;如何在多个处理步骤中找到最优组合;如何平衡性能和效率。
相关工作:该问题的研究相关工作有:通过查询和检索转换优化RAG管道;增强检索器性能;微调检索器和生成器;以及多模态RAG技术的应用。
二、研究方法
这篇论文提出了通过系统实验来识别RAG的最佳实践。具体来说,
查询分类:首先,对查询进行分类以确定是否需要检索增强。分类任务基于信息是否足够,分为“足够”和“不足”两类。使用BERT-base-multilingual模型进行自动化分类。

分块:将文档分成较小的段落以提高检索精度和避免长度问题。采用句子级分块,并使用LLM-Embedder评估不同的嵌入模型选择。
向量数据库:选择合适的向量数据库以高效存储和检索文档嵌入。评估了多个开源向量数据库,最终选择Milvus。
检索方法:评估了三种查询转换方法:查询重写、查询分解和伪文档生成。使用BM25和Contriever作为稀疏和密集检索的基线,并结合HyDE进行混合搜索。
重排:使用DLM重排和TILDE重排方法提高检索文档的相关性。DLM重排利用分类模型,而TILDE重排则基于查询词的概率。
文档重组:在重排后使用“反向”方法重新打包文档,以将更多相关上下文放在查询附近。
摘要:使用提取式和生成式摘要方法减少冗余信息。推荐使用Recomp进行摘要,因为它在性能和响应时间之间取得了良好的平衡。
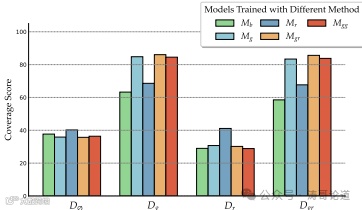
生成器微调:微调生成器以探索相关和不相关上下文对生成器性能的影响。定义了四种上下文组合:仅相关文档、随机文档、相关和随机文档的组合、两个相关文档的组合。
三、实验设计
数据集:使用了多个NLP任务和数据集进行评估,包括常识推理、事实检查、开放域问答、多跳问答和医疗问答。具体数据集包括MMLU、ARC-Challenge、OpenbookQA、FEVER、PubHealth、NQ、TriviaQA、HotpotQA、WebQuestions、2WikiMultiHopQA、MuSiQue和PubMedQA。
评估指标:根据任务类型选择不同的评估指标。对于常识推理和事实检查任务,使用准确率(Acc)和精确率(Prec);对于开放域问答和多跳问答任务,使用F1分数和精确匹配(EM);对于所有任务,计算RAG得分并测量每个查询的响应时间。
实验设置:在每个模块中使用默认或替代方法进行实验,并通过逐步优化单个模块来选择最有效的选项。最终使用Llama2-7B-Chat模型进行生成器微调。
四、结果与分析
查询分类模块:分类模块显著提高了整体得分,从0.428提高到0.443,并减少了响应时间,从16.41秒减少到11.58秒。
检索模块:虽然“HyDE混合”方法获得了最高的RAG得分0.58,但计算成本较高,每查询11.71秒。因此,推荐使用“混合”或“原始”方法以减少延迟并保持相似的性能。
重排模块:缺少重排模块导致性能显著下降,强调了其必要性。MonoT5实现了最高的平均得分,证明了其在增强检索文档相关性方面的有效性。
文档重组模块:“反向”配置表现出优越的性能,RAG得分为0.560,表明将更多相关上下文放在查询附近可以获得最佳结果。
摘要模块:Recomp表现出色,尽管通过移除摘要模块可以在较低延迟下获得可比结果,但仍推荐使用Recomp,因为它可以解决生成器的最大长度限制。
生成器微调:在训练中使用相关和随机文档的组合(Mgr)效果最佳,建议在提供金标准或混合上下文的情况下进行训练。
五、总体结论
这篇论文通过系统实验识别了RAG系统的最佳实践,提出了两种不同的实现策略:一种追求最高性能,另一种在效率和效果之间取得平衡。研究结果表明,每个模块都对RAG系统的整体性能有独特贡献。此外,论文还展示了多模态RAG技术在视觉输入问答中的显著改进,并通过“检索即生成”策略加速了多模态内容的生成。未来的工作将扩展RAG的应用范围,包括视频和语音等其他模态,并探索跨模态检索的高效技术。
六、优点与创新
系统评估:通过广泛的实验,彻底调查了现有的RAG方法及其组合,识别并推荐最佳RAG实践。
综合评估框架:引入了一套全面的评估指标和相应的数据集,以全面评估检索增强生成模型的性能,涵盖一般、专业(或领域特定)和RAG相关能力。
多模态检索技术的集成:展示了通过“检索即生成”策略显著增强视觉输入的问题回答能力,并加速了多模态内容的生成。
查询分类模块:提出了基于任务的查询分类方法,以确定是否需要检索,从而提高整体性能并减少响应时间。
块大小和技术选择:详细研究了块大小对性能的影响,并选择了最佳的块大小和技术,如小到大的方法和滑动窗口。
向量数据库的选择:评估了多种向量数据库,并选择了最适合研究需求的Milvus。
检索方法的优化:提出了结合稀疏检索和密集检索的混合搜索方法,并通过实验确定了最佳的超参数值。
重排方法的比较:比较了多种重排方法,推荐了表现最佳的monoT5方法。
摘要方法的选择:评估了多种摘要方法,推荐了性能优越的Recomp方法。
生成器微调的研究:探讨了相关和不相关上下文对生成器性能的影响,并提出了在训练中混合使用相关和随机文档的最佳方法。
七、不足与反思
联合微调的探索:虽然评估了各种方法对LLM生成器微调的影响,但未来工作将探索同时微调检索器和生成器的可能性。
块技术的影响:由于构建向量数据库和进行实验的成本高昂,评估仅限于块模块内的代表性块技术的影响。未来工作将进一步探讨不同块技术对整个RAG系统的影响。
跨模态检索的扩展:虽然将RAG扩展到图像生成领域,但未来工作将包括视频和语音等其他模态,并探索高效且有效的跨模态检索技术。