
昨天晚上刷到 Vidi2 的时候,第一反应是:字节这下真是把“视频理解”这仗,打到别人家客厅里去了。
以前聊多模态,更多还是图片、短视频那点事,这次他们干脆直接给出一个 120 亿参数、专门盯着长视频、还能顺带剪片子的家伙,名字叫 Vidi2,
定位很简单:就是要看懂你那几个小时的素材,然后帮你把片子剪完。

先说最直观的点。以前那种“视频问答”“长视频检索”,很多模型给人的感觉就是:你问“那只穿红衣服的小孩在滑梯上摔倒是哪一段?”,它要么给你一个模糊时间,要么根本找不到。
Vidi2 搞了个新词,叫 STG,也就是精细时空定位,简单粗暴理解,就是它既要知道“什么时候发生”,又要知道“画面里具体哪一块在发生”。 给一段描述,它能直接在时间轴上框出一个区间,再在每一秒的画面上画出那个目标的“管道”,本质是连续的边界框轨迹,编辑视角看,这玩意就跟直接在时间线上自动生成一个个可编辑的跟踪片段差不多。 这个能力在自己的 VUE-STG、VUE-TR-V2 基准上已经是第一梯队,tIoU 能跑到 53 这一档,在超长视频上直接把 Gemini3 pro 这类商用模型甩出去十几个百分点,这种差距在实际检索体验里,其实就是“能不能快速锁定一段关键镜头”的区别。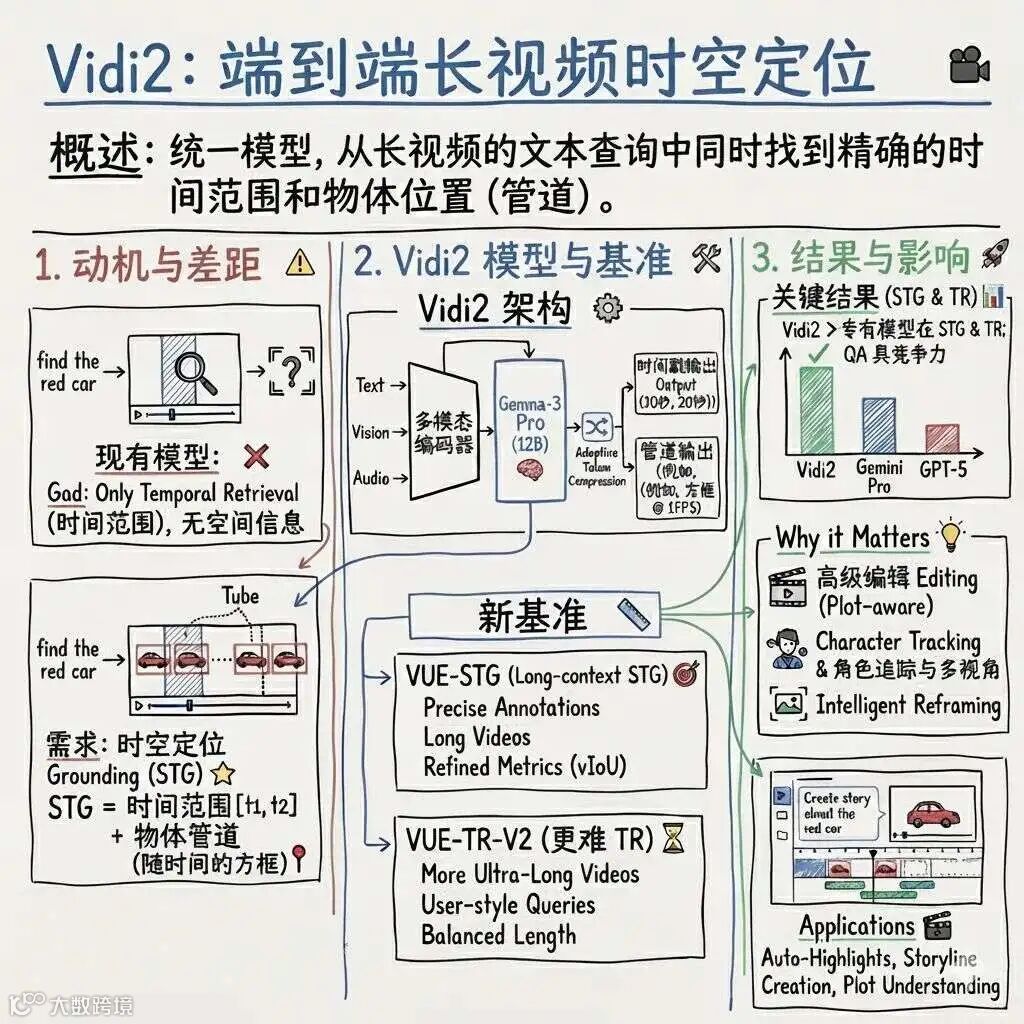
我一开始以为这又是一个“长视频版 CLIP”,顶多就是训练数据喂得更多,结果翻了下细节,发现它的思路有点不一样。
视觉主干他们选的是 Gemma-3,做了一层自适应标记压缩,把长视频拆成一秒一片,又尽量把关键帧的信息塞进去,这种处理方式有点像“强迫症剪辑师”在做逐秒标注。
更有意思的是,图片在这里会被处理成“1 秒静音视频片段”,也就是说,同一套管线里,图、短视频、长视频都被当成统一时间粒度的“序列”,这对后面做跨模态检索、问答,其实是加了很多一致性,代价就是模型本身得学会在不同时长上“收放自如”。
训练这块,它们一方面用大量真实视频,配合人工标的时间段、目标框,另一个是自己合成了一堆时空定位数据,用图像级的标注去拉长成视频级,这种“先学静态,再学动态”的路线,看起来有点土,但对长时间跟踪真的挺有效。
但模型再好,如果只停在论文里,那对普通创作者来说,就跟天文望远镜一样,看着高大上,摸不到。
字节这次明显不是只想发论文,它已经把一部分能力塞到了 TikTok 的 Smart Split 之类的功能里。
 Smart Split 做的事情很日常:把一段长视频,自动切出适合短视频平台的高光片段,顺带加字幕、改排版、重构构图,最后吐出一堆“可发可二次编辑”的短视频草稿,这里面那种“故事感知剪切”和“内容感知重构图”,背后就是 Vidi2 那一整套定位加检索的组合拳。
Smart Split 做的事情很日常:把一段长视频,自动切出适合短视频平台的高光片段,顺带加字幕、改排版、重构构图,最后吐出一堆“可发可二次编辑”的短视频草稿,这里面那种“故事感知剪切”和“内容感知重构图”,背后就是 Vidi2 那一整套定位加检索的组合拳。
你可以想象一下,将来你丢给它一场两小时的分享会,让它帮你剪成 10 条抖音或者 TikTok,小标题、镜头切换、关键镜头都提前铺好,你要做的事情变成“挑哪几条发”,而不再是“从哪剪起”,这种生产关系的变化,慢慢就是职业剪辑师和普通创作者之间新的分工线。

我们再绕回模型本身的“战力值”上。论文里给自己定了两个主战场:一个是细粒度时空定位,一个是开放式时间检索。
在 STG 上,他们用了 vIoU、tIoU 这些指标,整体 vIoU 30 多、tIoU 50 多,看起来数字不算惊人,但对比同场的 Gemini3 pro、GPT-5、Qwen3-VL 这些模型,就能发现长视频、特别是对象很小的场景里,其他家会“越拖越糊”,而 Vidi2 能把管道基本连起来,这种“稳定性”对真实项目来说,很关键。
时间检索那边,VUE-TR-V2 总体 IoU 快到 50,超长视频上领先商用模型十几个点,你可以把这理解成:在一个小时以上的视频里问“主持人情绪第一次明显变化是哪段”,Vidi2 更有可能给出一个“你看了会觉得对”的时间段,而不是一个需要你自己再拖动十几分钟的片段。
说到这里,其实就有点开始“威胁感”了。
最近几个月一直在看各种多模态模型,Gemini 家族、o3 系列、各家自研 VL 模型,大家都想做那个“统一入口”:文本、图、音、视频,一口气接完。
但 Vidi2 这条路,明显是“承认偏科”,它先把视频理解这块卷到极致,尤其是服务于长视频剪辑、检索的那一类场景,然后再往问答、生成那里扩展,这会让它在某些产品上,显得“很窄但很锋利”。
对独立 AI 视频工具创业者来说,这种“平台型偏科选手”其实是很危险的,因为它一边掌握算力、一边掌握数据闭环,再加上直接挂在 TikTok 上的入口,你很难跟一个顺手把训练样本和分发渠道都打通的平台,拼纯技术体验。
但也别太悲观,风水轮流转这句话,放到 AI 视频赛道上还是成立的。平台巨头有海量数据,也有一堆历史负债,哪怕是 TikTok 这种节奏,真正把 Vidi2 这种级别的模型大规模推到产品线,也需要很长的打磨周期。 对我们这些做工具、做工作流产品的人来说,反而更重要的,是看清楚这种“更聪明的视频理解”能被用在哪些缝隙里,比如做垂直领域的素材检索、做企业级的会议视频管理、做直播复盘等等,让巨头的通用模型变成一块基础设施,而不是直接的竞争对手。

总之,Vidi2 这次给我的感觉,不是又多了一个“参数更大、榜单更高”的模型,而是真的往前推了一小步:从“看懂一段视频”,走向“对整条时间线负责”。 当一个模型可以在几小时素材里帮你找剧情节点、跟踪人物、自动剪高光、改构图,创作者手里的那点“体力活”会越来越少,剩下的就只剩一个问题:你到底想讲什么故事。
工具会越做越厚,且越来越聪明,但“想讲什么”这句话,暂时还是谁都替代不了。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。