
您在上一节中学到了计算模型的预测精度,并将模型的预测与该测试集的已知真实结果进行比较。
问题是,如果以错误的方式执行交叉验证,很容易将测试数据的信息泄漏到训练数据中,我们称这种现象是训练数据的污染。污染提供机器学习方法在训练期间无法访问的信息。在受到污染的情况下,该模型的性能将优于预期的效果。
You learned in the previous section to calculate the predictive accuracy of a model, and compare the model’s predictions with the known true result for this test set.
The problem is that it is still very easy to leak information about the testing data into the training data if you perform a cross-validation in the wrong way. We call this phenomenon contamination of the training data. Contamination provides access to information the machine learning method should not have access to during training. With contamination, the model will perform better than you expect it to perform when compared to situations when this information is not available.
让我们来看一些典型的情况,测试数据泄露导致训练数据的意外污染。这不是一个完整的示例列表,但是如果你想避免这个问题,它应该足以给出关于该问题的解决思路。
Let’s show a few typical situations where accidental contamination of training data by leaking information about the test data can happen. This is by no means a complete list of examples, but it should be enough to give you the general idea about the problem and what to look for if you want to avoid this.
您希望规范化数据,以便所有列的范围相似。在使用任何基于相似度的模型(如k-Nearest Neighbors)之前,这一点尤为重要。这似乎是一个简单的任务:只是规范化数据,然后训练模型并通过交叉验证来验证它。在RapidMiner中流程如下:
You would like to normalize data so that all columns have a similar range. This is particularly important before using any similarity-based models like, for example, k-Nearest Neighbors. This seems to be a simple task: just normalize the data and then train the model and validate it with a cross-validation. This is how this would look like in RapidMiner:
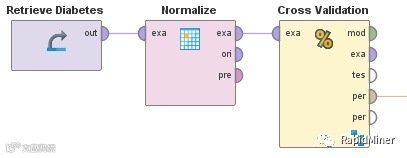
你觉得看起来没错?错!上图方法会导致误差估计错误。如果在交叉验证之前对数据进行规范化,您实际上将按照规范化训练数据的方式泄漏有关测试数据的信息。虽然你没有使用测试数据来训练模型,但是您将其中的一些信息灌输到训练数据中,因而我们称之为效应污染。
您应该做的是在交叉验证内部进行规范化,并且仅在训练数据上执行。然后,您将收集有关训练数据的信息,并将其用于测试数据的转换。您可以在下面RapidMiner流程图片中轻松查看正确的设置:
Looks good you say? Wrong! Because the approach shown will lead to a wrong error estimation. If you normalize the data before the cross-validation, you actually leak information about the distribution of the test data into the way you normalize the training data. Although you are not using the test data for training the model, you nevertheless instill some information about it into the training data. This is exactly why we call this effect contamination.
What you should do instead is to perform the normalization inside of the cross-validation and only on the training data. You then take the information you gathered about the training data and use it for the transformation of the test data. You can easily see the correct setup in the image below:

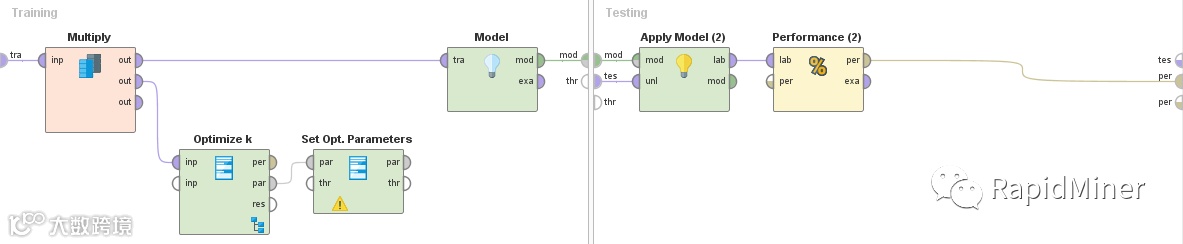
在左边的训练阶段做的第一件事就是只规范化训练数据。转换后的数据之后传送到机器学习方法中(本例中的逻辑回归)。规范化的预测模型和变换参数将递送到右侧的测试阶段。我们在将预测模型应用于转换的测试数据之前,根据训练数据的分布,对测试数据进行变换。最后,我们像往常一样计算出误差。
下表总结了交叉验证的测试误差,一次在交叉验证之前执行规范化,一次在交叉验证内部进行规范化。它清楚地显示了在验证模型前不衡量数据预处理本身的影响将会对误差带来的影响。
The frst thing you do in the training phase on the left is to normalize only the training data. The transformed data is then delivered to the machine learning method (Logistic Regression in this example). Both the predictive model and the transformation parameters from the normalization are then delivered into the testing phase on the right. Here we frst transform the test data based on the distributions found in the training data before we apply the predictive model on the transformed test data. Finally, we calculate the error as usual.
The table below summarizes the cross-validated test errors, one time with the normalization performed before the cross-validation and one time with the normalization inside of the cross-validation like. It clearly shows the effect on the error if you validate the model without measuring the impact of the data pre-processing itself.

如果在交叉验证之前完成规范化,则所有情况下计算的误差都太乐观。平均来说,逻辑回归的实际误差高出3.9%,k =5时KNN的误差高出3.4%。对于Random Forest的差异为0%,因为无论数据是否规范化,模型都不会改变。
最后需要注意的是:正确的验证并不能帮助您创建更好的模型,而是告诉您关于模型在生产中的效果好坏。
If the normalization is done before the cross-validation, the calculated error is too optimistic in all cases. On average, the actual error is 3.9% higher for Logistic Regression and 3.4% higher for a k-Nearest Neighbors with k=5. The difference is 0% for Random Forest simply because the models do not change at all if the data is normalized or not.
A final thing which is important to notice: Correct validation is not helping you create better models, instead it is telling you the truth about how well (or poorly) the model will work in production.
接下来,我们来看一下优化模型参数的影响。数据科学家经常搜索最佳参数以改善模型的性能。他们可以手动更改参数值手动执行此操作,并通过使用指定参数交叉验证模型来衡量测试误差的变化;或者使用自动方法,如网格搜索或进化算法。目标是找到适用数据集的效能最佳的模型。
如果您选择参数以使给定测试集上的误差最小化,则该参数设置仅针对该特定测试集 - 因此误差对模型不具有代表性。许多数据科学家建议除了测试集之外,还要使用所谓的验证集。所以您可以先用测试集来优化参数设置,然后您用验证集来验证参数优化的误差和模型。
如果仅使用验证集,您将无法获得正确交叉验证的所有优势。但是您可以通过将多层交叉验证嵌套在彼此中来正确执行此操作。内部交叉验证用于确定特定参数设置的误差,可以在自动参数优化方法的内部使用。此参数优化成为您的新机器学习算法。现在,您可以围绕这种自动参数优化方法包装另一个外部交叉验证,以正确计算在生产场景中可以预期的误差。
Next let’s look at the impact of optimizing parameters of the model. Data scientists often search for optimal parameters to improve a model’s performance. They can do this either manually by changing parameter values and measuring the change of the test error by cross-validating the model using the specifed parameters. Or they can use automatic approaches like grid searches or evolutionary algorithms. The goal is to always fnd the best performing model for the data set at hand.
If you select parameters so that the error on a given test set is minimized, you are optimizing this parameter setting for this particular test set only – hence this error is no longer representative for your model. Many data scientists suggest to use a so-called validation set in addition to a test set. So you can first use your test set for optimizing your parameter settings, and then you can use your validation set to validate the error of the parameter optimization plus the model on this set.
You won’t get all the advantages of a proper cross-validation if you use validation sets only. But you can do this correctly by nesting multiple levels of cross-validation into each other. The inner cross-validation is used to determine the error for a specifc parameter setting, and can be used inside of an automatic parameter optimization method. This parameter optimization becomes your new machine learning algorithm. Now you can simply wrap another, outer cross-validation around this automatic parameter optimization method to properly calculate the error which can be expected in production scenarios.
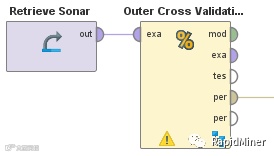
如预期的那样,使用上述“嵌套”方法的正确验证误差高于直接用于指导搜索的验证误差。平均偏差约为0.5%,最大偏差为1%。 但是,即使您的期望与模型即使是1%的差距也可能相距甚远。
As expected, the properly validated errors using the “Nested” approach as described above are higher than the errors taking directly out of the validation used for guiding the search. But the differences are rather small with roughly 0.5% difference on average and a maximum deviation of 1%. But still, even a difference of 1% between your expectation and how well the model performs in production can be a huge and costly surprise.

作为最后一个例子,我们来看一下经常执行的另一个预处理步骤,用于优化机器学习模型的精度,即特征选取。目标是选择模型使用的特征或数据列的最佳子集。
类似于参数优化,数据科学家可以通过仅使用简化特征集的数据计算交叉验证的测试误差来手动选择特征的子集并评估模型的准确性。与参数优化一样,选择最优特征集基本上是训练预测模型的延伸,也需要适当的验证。
更好的选择是将自动特征选择(使用内部交叉验证来引导搜索最佳特征集合)再次嵌套到外部交叉验证中,就像在参数优化的情况下一样。
As a last example, let’s look at another pre-processing step which is frequently performed for optimizing the accuracy of machine learning models, namely feature selection. The goal is to select an optimal subset of features or data columns used by the model.
Similar to the parameter optimization, data scientists could manually select a subset of features and evaluate the model’s accuracy by calculating a cross-validated test error using only the data of the reduced feature set. But just as in the case of parameter optimization, picking the optimal feature set is basically an extension of training the predictive model, and it needs to be properly validated as well.The better alternative is to nest the automatic feature selection (using an inner cross-validation to guide the search for the optimal set of features) into an outer cross-validation again, just as we did in case of the parameter optimization.
如上所述,正确的设置从外部交叉验证开始,我们使用外部交叉验证来评估参数优化的性能。这种交叉验证的内部设置看起来略有不同,如下所示:
The correct setup starts with an outer cross-validation just as described above where we used an outer cross-validation to evaluate the performance of the parameter optimization. The inner setup of this cross-validation looks slightly different though, as follows:


在这里,您可以看到,您的期望值最高高于4.2%。最大的偏差甚至高达11%(Sonar上的5-NN) - 甚至高于上述规范化情况下看到的最大值8%。你的预期误差是双倍的(22% vs. 11%)!值得指出的是,计算的平均和最大偏差很大程度上取决于您使用的数据集和模型类型。
Here you see that the amount by which your expectations would be off is on average up to 4.2%. The largest deviation was even as high as 11% (5-NN on Sonar) – which is even higher than the maximum of 8% we saw in the normalization case above. Think about this: your error in production would be double (22% vs. 11%) what you expected. It is worth pointing out that the calculated average and maximum deviations greatly depend on the data sets and model types you use.
如何避免意外污染?
How to avoid accidental contamination?
任何可视化数据科学产品需要四个主要组件来执行正确的验证:
1.正确的验证方案,如交叉验证:许多可视化产品(如Alteryx)不支持提供的所有机器学习模型的交叉验证。
2.模块化验证方案:这意味着交叉验证的测试误差不仅仅需要自动传送,或者启用机器学习方法的参数,而且验证方法需要细致的建模。
3.多级嵌套:要测量模型选择之外的活动效果,您需要将多个交叉验证嵌套在彼此中。如果您要同时测量对多个优化的影响,则尤其如此。
4.预处理模型:可视化平台需要足够的功能,可以在不同的测试数据集上对应训练数据进行完全相同的预处理。
Any visual data science product needs four main components to perform correct validations:
1. Proper validation schemes like cross-validation:Many visual products (like Alteryx) do not support cross validation for all the machine learning models they offer.
2. Modular validation schemes: This means that the cross-validated test error is not just delivered automatically or if a parameter of the machine learning method is switched on, but the validation method is explicitly modeled.
3. Multi-level nesting: To measure the effect of activities outside model selection, you need to be able to nest multiple cross-validations into each other. This is especially true if you want to measure the impact on multiple optimizations simultaneously.
4. Pre-processing models: The visual platform needs enough capabilities to apply exactly the same preprocessing you applied on the training data also on a different test data set.
RapidMiner Studio是唯一行业领先的支持上述四个组件的可视化数据科学和机器学习产品。它们都是创建正确的验证的必需品,在您投入生产使用之前,给出必要的模型置信度级别。
RapidMiner Studio is the only visual data science and machine learning product which is well-known for supporting all four components above. They are all a must to create correct validations that give you the necessary level of confdence in your models before you go into production usage with them.
赶紧登录www.rapidminerchina.com下载RapidMiner进行试用吧!
Go to www.rapidminerchina.com now and download the basic version of RapidMiner for a trial~
了解更多RapidMiner相关信息:
网址:www.rapidminerchina.com
电话:4006 326 339
邮箱:sales@rapidminerchina.com

阅读往期精彩内容:
最新资讯:
RapidMiner在2017年连续第四年被Gartner评为数据科学平台魔力象限领导者
RapidMiner被Forrester誉为预测分析和机器学习解决方案的领导者
RapidMiner 7.5 性能全面升级,正式发布咯~
干货分享:
机器学习平台RapidMiner之如何正确验证模型Part1
机器学习平台RapidMiner技巧篇(1):Excel报表处理
机器学习平台RapidMiner技巧篇(2):从PDF中提取数据表
机器学习平台RapidMiner技巧篇(3):从网页中提取数据表
