↑↑ 这里,是你的“科技智库”,想看什么,可随时搜索备查。进公众号,回复行业名,可快速查看相关报告。
↑↑ 加入科技讨论社群,获取报告库、景气跟踪图集、行业脑图,可加微信:bgys2015
自然语言处理(NLP,Natural Language Processing),是一门研究如何让计算机能够理解和处理人类自然语言的学科;
大模型(LLM,Large Language Model),则是一种算法工具,让机器处理人类自然语言。
NLP和大模型,不是同一件事,两者是学科VS工具的关系。如今,人们经常用大模型工具来解决NLP的细分任务,比如生成文章、对话、摘要、翻译等,甚至逐步开始做更加复杂的多模态任务,如文生图片(OpenAI开发的DALL·E模型),以及刚刚引爆市场的文生视频(OpenAI的Sora模型)。
2月16日,OpenAI发布了震撼人心的Sora模型。与以往的文生视频模型Runway和Pika不同,Sora可以根据文本的提示,持续生成60秒的人物、动物和物体场景和镜头运动,或者扩展现有视频以及从图像中生成视频。

图:Sora生成的视频,以及原理
来源:OpenAI、国君研究所
60秒是什么概念?这可以辗轧目前全球范围内所有的文生视频模型,因为在它之前,同类参数最高的,也只能做到4秒。
这不是一星半点的突破,而是具有“颠覆性”、“里程碑意义”的存在。
不过,再彪悍难懂的技术,最终都能倒推回一个本质内核。无论是OPEN AI的Sora、ChatGPT,还是谷歌的Gemini、T5,或者Meta的Llama,抑或是至国内如雨后春笋般出现的各种大模型,如百度的文心一言、科大讯飞的星火、字节的豆包、阿里的通义千问、华为的盘古、昆仑万维的天工……
所有这些大模型,共同的技术底座只有一个,那就是:Transformer。本篇报告,基本就围绕Transformer而展开。
Transformer,像一个漏斗,将NLP自然语言处理这个融合了语言学、计算机学、数学、统计学、心理学的大综合学科,硬生生切成了两部分,一部分是它之前,一部分是它之后。没有它,就没有如今AI大模型的繁荣。
图:Transformer对大模型的重要性
来源:国君研究所
规则学习阶段(1956年到1970年):早期的自然语言处理,是基于人类专家预先设定好的规则,来处理语言任务。这一时期的关键技术,比如:专家系统、正则表达式等。
不过,它的缺点也很明显,编写大量规则太过耗时,并且难以覆盖所有可能的情况,并且如果面对新的语言环境,就难以适应。
就像一个严格按照菜谱做菜的机器人厨师,一旦让他做菜谱上没有的菜,就懵圈了。
统计机器学习阶段(1970年到2000年):基于“人编写规则”的缺点,科学家们开始探索,能不能让机器自己从数据中去学习规则,然后发现其中的规律,然后再去执行任务。这一时期的关键技术,比如决策树、支持向量机(SVM)、K近邻算法(KNN)等。
就像一个厨师,根据过去的数据中,川菜更受顾客喜爱,然后它就在自己的菜里多放一些辣椒。
不过,它的缺点仍然很明显,只能处理简单场景,对复杂、非线性问题无能为力。
神经网络与深度学习阶段(2000到2018年):模仿人脑神经元传递信息的工作原理,在此基础上,形成多层、非线性的神经网络,不仅能自己学习人类已有规则,还能创造新规则,它能从原始数据中提取高级特征,并进行发散演绎。
这一时期的关键技术,比如卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)等。
能够一个智能大厨,不仅能依据过往菜谱、顾客反馈数据,来调整烹饪策略,还能通过理解不同食材之间能碰撞出什么风味,以及温度、时间对口感的影响。然后它还能跳出菜谱,创造出新的烹饪方法。
大规模预训练模型阶段(2018年至今):这一阶段,科学家开始尝试在超大规模的数据集上,预先训练神经网络模型,然后再到具体使用场景中做微调。这一阶段的核心技术,如Transformer架构、微调、多模态学习等。
Transformer架构,是人工智能领域神一般的存在,它是目前几乎所有大模型的祖师爷。
把Transformer用于图像生成领域,衍生出了Vit模型(Vision Transformer),这是Sora的技术源头;
把Transformer用于文本生成领域,衍生出BERT、GPT、T5三大代表模型,分别采用Encoder only、Decoder only、Encoder+Decoder三种技术流派。
其中的Decoder only,就是GPT之所以能够爆发,所依赖的核心技术。
理解Transformer、Decoder only,才能理解在大模型时代,为什么数据量会几何级数增长,大模型为什么能越来越聪明。
数据量的增长有多快?2020年,OpenAI推出了GPT-3,模型参数规模达到1750亿,而到202年的GPT4,则指数级增长到1.8万亿的参数规模。
GPT外部文档和数据库的截止更新日期,从21年9月更新至23年4月,意味着OpenAI的大模型在半年内,已学习互联网一年半的知识。
上游——基础层(算力和数据):以云服务、AI芯片、光模块、数据采集/标注等厂商为主,为行业提供基础性支持。代表公司有英伟达、AMD、华为昇腾、燧原科技、壁仞科技、阿里云,以及复旦微电、中科曙光、中际旭创等。
数据/训练参与者主要包括海天瑞声、科大讯飞、云从科技、汉王科技、拓尔思、云从科技等。
图:通用服务器VS AI服务器成本构成
来源:华福证券
中游——模型层:涉及计算机视觉、智能语音语义、机器学习平台等,主要提供人工智能算法等核心技术和解决方案。国内代表公司有百度、阿里、华为、科大讯飞、商汤、昆仑万维等。
下游——场景层:可用于办公(金山办公、致远互联、万兴科技)、文娱、营销、电商、教育(科大讯飞)、金融(宇信科技、中科软、恒生电子、同花顺)等多领域,代表公司还有微软、谷歌、百度、腾讯、阿里巴巴等。
对于科大讯飞(星火模型)、百度(文心一眼)、昆仑万维,我们在前一篇大模型报告中覆盖过,
三六零——根据业绩预告,营业收入较去年同期略有下降,预计2023年度归母净利润约为-5.5亿元至-3.7亿元,同比增长75.0%~83.2%;扣非归母公司净利润约为-8.5亿元至-5.7亿元,同比增长54.4%~69.4%。
大华股份——根据2023年年度业绩预告,全年实现营业收入322.31亿元,同比增长5.45%;归母净利润73.71亿元,同比增长217.10%;扣非净利润29.61亿元,同比增长87.35%。
神思电子——根据业绩预告,预计2023年营业收入5-6亿元(上年3.8亿元),归母净利润700万元~1050万元,同比扭亏为盈。
图:机构一致预期增长和景气度情况
来源:并购优塾、choice
基金清算退出是私募基金隐藏的问题与矛盾集中爆发的阶段。私募基金应该怎样完成合规退出与清算?基金管理人与投资人可以采取何种方式解决这些问题?关于私募基金的退出存在很多困惑和未解的难题,亟待业界的交流与探讨。
为此,围绕“新《公司法》对私募基金的影响&基金清算退出”这一主题,我们并购优塾将在2024年3月9日-10日 在上海举办本次精英训练营,希望可以抛砖引玉,与您共同探讨如何应对新《公司法》后私募领域的新问题和新风向。
注:报名咨询,请联系工作人员:bgysyxm2018
2024年3月23日-24日,并购优塾将在上海举办为期两天的《数字化背景下的业财融合、全面预算与资金管理》主题研讨会。本课程从数字化技术发展对财务影响、业财融合、全面预算、资金管理等主要内容出发,目的在于帮助财务总监升级现代财务管理思维与管理方法。
人工智能、机器学习、神经网络、深度学习、强化学习、深度强化学习,这几个词之间的关系,举例来说:
如果人工智能是一位全能的厨师,那么,机器学习是厨师掌握的一种自我提升技艺,他通过不断学习过往做的菜,来优化自己的菜谱。
而神经网络,是实现机器学习的一种工具,就像厨师手中的锅,它是一个工具,能模仿人类大脑神经元,来对信息进行处理。信息是它的原材料,炒出来的菜是输出结果。
深度学习,是神经网络的一种复杂形式,是将单个神经元基础上加入多个隐藏层级,好来处理非线性复杂任务,相当于多层繁复的烹饪流程,好让多种菜品和调味料之间发生复杂化学反应。
强化学习,是厨师的成长机制,它根据顾客的反馈,来调整它的菜谱。
而深度强化学习,是将深度学习和强化学习结合在一起,形成更加强大的学习体系。
AI大模型,本质原理是基于人类大脑的神经元衍生而来。下图,是一个神经元:

图:脑神经元结构,来源:CSDN博客肖恩林
https://blog.csdn.net/linxiaoyin/article/details/104082552
科学家为了复制这个神经元的功能,将它抽象化为一个计算机模型,如下图。其中,X1、X2、Xn是多个输入信息,W1、W2、Wn是各信号的权重,在达到一定阈值θj后,神经元被激活,然后将输入信息消化处理,传递出输出信息Y。
图:MP模型,模拟神经元处理信息过程
来源:CSDN博客,THE ORDER
https://blog.csdn.net/weixin_44498127/article/details/124119249
这是单层神经元,它能够处理单层线性信息,如“番茄炒土豆”。
这个模型,跨越了心理学和数学两大学科,由心理学家Warren S. McCulloch 和数理逻辑学家 Walter Pitts合作开发,命名为“MP模型”。
那么,如果在MP模型的输入层、输出层之间,再加入多个隐藏的逻辑层(取名为“隐层”),就能处理更加复杂的多层信息,比如“番茄土豆牛腩,这个菜的背后逻辑是什么,具体是什么化学成分,发生了什么样的化学反应,以及未来加什么调料,能让它更好吃”。

图:神经网络基础架构
来源:CSDN博客,浪子私房菜
https://blog.csdn.net/niuxuerui11/article/details/108694979
从这以后,神经网络和深度学习的发展史,其实就是科学家不断增加中间层数,改变各层逻辑的历史。
这中间,经历了卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)等多个阶段,但结果,都不是很理想。
一直到Transformer模型出现,像万丈光芒一般扫除漫漫长夜。
2017年6月,谷歌发布论文《Attention is All You Need》,它首创了自注意力机制,并且可以并行化训练,不仅大幅提升深度学习的性能,而且大幅提升了机器学习人类语言的效率。现在火爆全网的GPT、Sora,其实就是把Transformer拿来修修改改而成。
Transformer,也是在神经元之间增加多个层,只不过,它增加的更清晰、更有效。它的逻辑,是这样的:
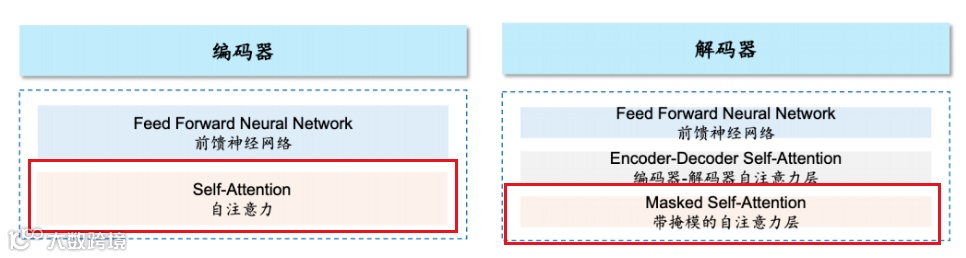
上面的Transformer模型比较复杂,如果把它简化一下,核心部分主要是两块:编码器(Encoder)和解码器(Decoder)。

图:Encoder和Decoder
来源:CSDN博客,Sophia$
https://blog.csdn.net/sophicchen/article/details/117804862
编码器,Encoder,负责提取信息,细致分析输入文本,理解文本中各个元素的含义,并为每个文本贴上特殊标签(向量)。
这个过程,就像一位厨师A,先阅读菜单上的配方(原始信息),然后根据配方,把番茄去皮、土豆切丁、牛腩切块,酱油、醋、盐、糖分别倒在小碗里,进行预处理(贴标签,成为向量)。
解码器,Decoder,依托编码器提供的信息(向量),负责生成最终输出结果(新的信息)。
这个过程,像另一位厨师B,把前一位厨师准备好的番茄、土豆、牛肉、调料,按照它大脑里对这个菜的记忆(预训练阶段形成),把调料入锅,翻炒、加水、小火焖炖,最终把番茄土豆牛腩这盘菜端上桌。
Transformer之所以强大,是因为Encoder和Decoder中的核心点:自注意力机制(Self-Attention)。
传统的卷积神经网络(CNN)、循环神经网络(RNN),在处理序列数据时,需要按顺序逐步处理每个元素,难以捕捉长距离的依赖关系。
比如,CNN这位厨师,只能看到土豆、牛腩、番茄这三样食材(局部感受野,只能看到固定区域内的食材),无法充分考虑整体菜品加上调味料如酱油、醋、糖之后的搭配效果。
而RNN这位厨师,只能记住三、五个做菜步骤,如果做菜步骤达到10个以上,可能会忘掉之前的第一个步骤。
而自注意力机制,允许模型在处理每个元素时,能够关注到序列中的其他元素,从而捕捉到更全局的信息。它的核心逻辑,是通过计算输入序列中每个元素与其他元素的相关性,从而构建权重矩阵。
比如,Transformer这位厨师,在做菜时候,能够先扫视整桌食材(当下全局视野,所有食材尽在眼中),然后调用三年前做这道菜的历史数据,知道影响这道菜口感的关键,在于慢炖过程中,肉和香料的融合程度,然后,它会给每种食材一个“注意力权重”(权重打分)。
基于这种“注意力权重”,他会在炖煮后期,更多关注一个小时前添加的某种香料是否已经充分释放香气,并据此调整火力和搅拌频率(关注历史全局,以及各事物之间的关系权重,而不会受限于最近的几步操作)。
注意力机制的具体操作机制,是通过给每件事物贴上查询(query)、键(key)、值(value)的标签,然后做计算。
然后,它先分析用户需求(query,查询向量),和备选物体的标签(key,键向量)之间的关联度,然后根据这个权重,将事物对用户需求的贡献强度度(value,值向量)进行加权求和计算。
通过这个过程,两件事物的关联度高低数值,就能计算出来。
图:注意力机制计算过程
来源:淘嘟嘟,博客
http://www.taodudu.cc
关于注意力机制,如果举个形象化例子,可以理解为,当你接到老婆的指令“去买一大瓶花生油回来”,那么你进入超市后,就只会快速关注货架上大桶装的、液体呈现金色的瓶子,而不会把所有货架从头到尾看一遍。
这样,就大幅增加了效率(计算时间),减少了资源浪费(存储和算力)。
以我们每个人日常生活中经常用到的“电影兴趣推荐机制”为例,假如你想在APP里找“科幻类的高评分电影”:
这时,大模型会将你的兴趣偏好(喜欢的类型、评分要求),标记为查询(query)向量。
然后,对应的各电影,会被标记为各种标签,比如键1(key1,科幻)、键2(key2评分),这些键下对应的具体值为值1,1(value1,1,如是科幻电影,则值就是1,不是就为0),值2,8.5(value2,8.5,代表具体评分为8.5)。
数据按照上面的流程,先计算query和key之间的关联度,然后和每个key对应的value数值,进行加权求和。
正是这样的关联度打分机制,能够让大模型,能够将一些看上去八竿子也打不着的两个词联系在一起,从而创造性的生成新句子,帮助人类探索新的知识边界。
比如,“人形机器人谐波减速器柔轮”和“心脏瓣膜”,这是两个行业完全不相关、表面看上去根本没什么关联的抽象专业词汇,大模型能给你造出这样的句子:
“如何理解谐波减速器柔轮的材料难点,我们举个例子:就像你的心脏里面的瓣膜,它和减速器柔轮一样,都需要长时间、反复发生形状改变,所以需要有具备超强柔韧性、抗疲劳性、耐久性的先进材料”。
图:谐波减速器柔轮案例
来源:通义千问大模型,并购优塾团队与其对话
从Transformer开始,后人开始修修剪剪,衍生出文本大模型的三大技术流派:
Encoder only(如谷歌的BERT模型);
Decoder only(如Open I公司的GPT模型、谷歌的Gemini模型);
Encoder-Decoder(如谷歌的T5模型);
三大流派中,在最为重要的Decoder only路线中,GPT是这么干的:它将Transformer的编码器Encoder部分去掉,只留下Decoder部分,并且删除了Decoder中的一小块,如下图:
图:GPT是如何对Transformer模型做修改的
来源:谷歌、华泰研究
并购优塾团队在原图基础上加了标注
黑框打叉的地方,是GPT去掉的部分
同时,科学家们触类旁通,进行不同的修改,就形成了如下的技术进化图谱。
比如,只保留Encoder部分,将Decoder部分去除,就形成Encoder only模型(如谷歌的BERT模型);或者两部分都保留,就形成Encoder-Decoder模型(如谷歌的T5模型)。
图:大模型进化树
来源:华泰证券
注:开源模型由实心方块表示,而闭源模型由空心方块表示。
1)Decoder-Only架构(上图蓝色分支):从已有的信息(开头)扩展出新的内容,类似于成语接龙,像小说家一样,擅长创造性的写作,可以自动生成文章。
这种架构能够更好地理解和预测语言模式,尤其适合处理开放式的、生成性的任务。以OpenAI的GPT、谷歌的Bard、Meta的LLaMA、DeepMind的Chinchilla、Anthropic的Claude为代表。
国内模型中,智谱、昆仑万维、通义千问、商汤是基于GPT-2模型开发的;科大讯飞是基于LLaMA开发的。
2)Encoder-Only模型(上图粉色分支):专注于理解和分析输入的信息,而不是创造新的内容。
以谷歌的BERT为例,BERT是采用带有掩码(mask)的大语言模型,类似于完形填空,根据上下文预测空缺处的词语,适用于理解类以及某个场景的具体任务,例如文本分类、情感分析等。
百度自研的ERNIE模型也是Encoder-Only模型,但ERNIE 3.0是Decoder-Only架构。其他国内模型中,百川大模型基于谷歌的BERT开发。
3)Encoder-Decoder 模型(上图绿色分支),先理解输入的信息(Encoder部分),然后基于这个理解生成新的、相关的内容(Decoder部分)。
这种模型在翻译类任务中表现良好,例如机器翻译、问答系统等。代表模型有Meta的BART、谷歌的T5、清华大学的GLM。
其最大的贡献,是采用了预训练+微调策略:使用大规模无标注数据预训练模型,然后在特定任务上微调,增强了模型的泛化能力和迁移学习效果。
这个过程,和咱们中学英语做的“完形填空题”,有异曲同工之妙。给大模型一个牛津词典,然后随机遮蔽住其中几个单词,然后让大模型尝试做“完形填空题”。做完一次,给它公布一次正确答案,然后持续不断优化它做题的能力。
图:用完形填空的思路训练大模型
来源:金锄头
https://www.jinchutou.com/p-33967471.html
经过大量的训练和纠错,模型就能将词典中所有词语中的隐含关联,全都学会。学会之后,自然就可以来生成新的文本。
那么,既然文本可以这么训练,那么也可以迁移到语音、图像、视频上,它们都可以被切割成一个个小块,然后让模型通过做“完形填空题”的方式来学习。
所以,从GPT-3之后,OpenAI开始研发支持多模态输入输出的模型。
之后的关键节点,是Vision Transformer模型。Vision Transformer (ViT, Dosovitskiy et al., 2021) 将Transformer模型直接应用于图像分割成的小块上,实现对图像的全局建模。
图:ViT模型工作流程
来源:知乎,博主yearn
https://zhuanlan.zhihu.com/p/428886652
就像玩乐高积木,ViT模型会将这个大积木先切割成多个小块(补丁,patches),比如,每个补丁大小切为16x16像素(图片),或者每秒24帧(视频)。
然后是编码,它会给每块拼图或者积木,贴上一个独特的标签或描述,进而变成一个固定长度的高维向量(将二维图片、三维视频,统一都转换为一维的编码序列)。
之后开始组织信息流,将所有积木小块的编码,嵌入向量排成一列,形成一个类似句子的序列。

接着,自注意力机制,就可以挖掘其中每一个部分和其他部分之间的关联。之后的训练过程,相当于让大模型做拼图游戏(图片版的完形填空题)。
如果把人类世界所有的图片和视频,都按照“完形填空题”的思路遮掉一小块,来让它练习,久而久之,就可以输出新的语音、图片、视频。
最终,到了今天,技术进化到了Sora文生视频模型时代。
它不仅采用Transformer架构为底座,并且在此基础上融合了Diffusion扩散模型,进而形成更加强大的视频生成能力。
Diffusion扩散模型,是文生视频领域的突破性技术,它通过一种逐步添加和减去随机噪声的机制,好让模型对视频图像……………………………………………
以上,仅为本报告部分内容。关于核心增长空间测算、行业重点竞争态势、关键竞争要素分析等内容,后文还有大约6000字及数十张图表,详见《产业链报告库》,可联系工作人员咨询获取,微信:bgys2015。
【引用资料】本报告写作中参考了以下材料,特此鸣谢。[1]
【数据支持】Wind数据、东方财富Choice数据、智慧芽专利数据库、data.im数据库、理杏仁、企查查、Capital IQ、Bloomberg、路透。

























