

近年国际大数据概念被炒得愈发火热,相关的产品厂商也如雨后春笋般应运而生,大数据服务市场迎来爆发期。值得注意的是,大数据真的像我们想象那样理想吗?为何大数据总给人一种华而不实的感觉?

其实造成这种感觉的原因是媒体、厂商对大数据的解读,都在给人们造成一种认知偏差,认为“大数据能分析我们身边的一切,大数据是万能的,抓住大数据可以获得财富”。
但其实这是一种言过其实的说法。只不过媒体需要吹捧新颖吸睛的概念;厂商需要夸大其应用市场、商业价值来吸引融资;企业需要将自己的改革和大数据挂钩来确保成功的可能性,表明自己是在真创新。
大数据的应用和成功可能性还远没有这么成熟。
大数据的本质是什么?
现在叫大数据,以前可以称为信息、情报等等名字。以前的信息搜集技术没有这样发达,只能以样本信息形式出现,而且由于结构类型不同,只能分类处理,有些数据还不便于储存和比较。为什么现在叫大数据,是因为现代互联网技术,可以把不同结构类型的所有数据都能搜集到,形成全数据,并且随着大数据技术的深度发展,这些复杂结构类型的全数据,会被自动分类比较统计,所以称为大数据。

吴军在他的《智能时代》里提到对于大数据的观点:
只有量的积累的数据,通常并不能称之为大数据。除了大量性,大数据常常还应该具有多维性和完备性。
大数据的多维性,可以理解为针对单一“个体”(人/物/事件等)不同角度的数据。比如之前提到的:收集全国所有人的出生年月,单收集这一项,数据单一缺乏意义;但如果再加入收入、所属地区、受教育程度等等多维的信息,那数据本身就变得鲜活了。我们可以从数据中分析人口的地域分布、经济分布、教育分布等并在此基础上给出宏观的资源调控计划。
大数据的完备性,则可以理解为数据的全面性。比如2012年一位名叫内德·斯威尔的年轻人,利用大数据成功预测了美国50+1个州的大选结果。他其实就是在投票前利用互联网尽可能的搜集当年的大选数据(如地方媒体数据、社交网络留言、朋友间评论等),从而近似的知道每个人对大选的态度,并按照州进行分类整理,最终成功预测了当年的大选结果。

缺少多维性的“大数据”会让数据承载的信息“片面”,进而导致数据本身的利用价值大大下降;缺乏完备性的数据则会由于缺乏“完备样本”的支撑,也会使得获取的信息“局限性”。
大数据最好还应具有“及时性”,但及时性却并不是其必备条件,只是有了“及时性”的大数据,会实现一些过去无法做到的事情。

大数据的及时性,可以理解为数据收集的时效性。一方面,要分析当前情况,就要尽可能使用与当前时间点较为接近的数据;另一方面,数据本身就在时刻产生(特别是今天的互联网),新鲜的数据能更快速的反应当前社会的一些情况。比如使用百度地图导航的时候,它能根据数据库中人们当前的(及时的数据)车辆出行地点,和即将要去的地方大概估算出此人的行程规划,并通过众多数据的整合估算出某一路段可能的堵塞情况,进而在导航的时候给出“避免拥堵”的导航建议。
由此可见,所谓的大数据,一定要同时满足大量、多维和完备(相对来说)的特点,并在此基础上,最好具有“时效性”。
核心在于大数据思维
网络的诞生给世界带来了大量的数据积累和信息流通,并带来了一次“大数据思维”的思想变革。
机械思维时代,由于数据收集的局限性,科学家们只能在有限的样本下“大胆假设小心求证”,然而受限于人类大脑的“创造力”,所谓的“大胆假设”也并不是真的“大胆”;随着互联网时代的到来,“数据”不再成为问题,当大量数据堆积在一起时,就产生了“质”的变化。
与此同时,伴随着数据的大量积累和统计数学的发展,人们惊喜的发现:在数据量达到一定程度的时候,数据和数据之间的关联可以反映出某些意想不到的结果。于是大数据思维就诞生了:

世界本身是不确定的,利用大数据可以尽可能的消除这种不确定性,因果关系可以利用数据间的相关关系进行代替。
大数据思维,也有人将其成为“信息论”,其本质就是:
①利用不确定性看待世界,然后利用大数据来尽可能的消除这种不确定性;
②利用具有多维度特征的大数据,数据之间的相关关系来代替机械思维时代的因果关系,帮助我们在“创造”难以掌控的情况下,发现意想不到的结论。

举例来说:
我们在投放广告时,机械思维要我们先有一个假设:目标人群可能的特征,并进行调研和证实;而大数据思维则是:我们不确定要投放给什么样的人群,紧接着我们利用已有用户的数据特征发现了“用户群体画像”这就是消除不确定性的过程,最终我们直接根据数据给出的结论来制定计划。
大数据的基本处理流程与传统数据处理流程并无太大差异,主要区别在于:由于大数据要处理大量、非结构化的数据,所以在各处理环节中都可以采用并行处理。目前,Hadoop、MapReduce和Spark等分布式处理方式已经成为大数据处理各环节的通用处理方法。
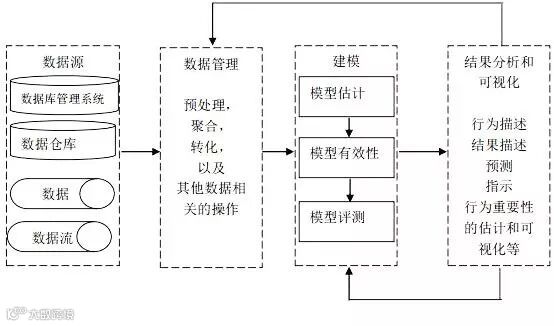
上图显示了传统的大数据工作流分析经历的一些阶段。数据以数据库,数据流,数据集合以及数据仓库等方式来建模。数据的数量级以及数据的多样性要求在处理之前要进行数据的集成、清洗以及过滤等工作,以保证其后续工作的开展。
无界悦联认为
大数据没有那么神秘,也并不神奇,只是对一堆数据的剖析运用,运用的手法如何,掌握的您的手上!
-END-
