
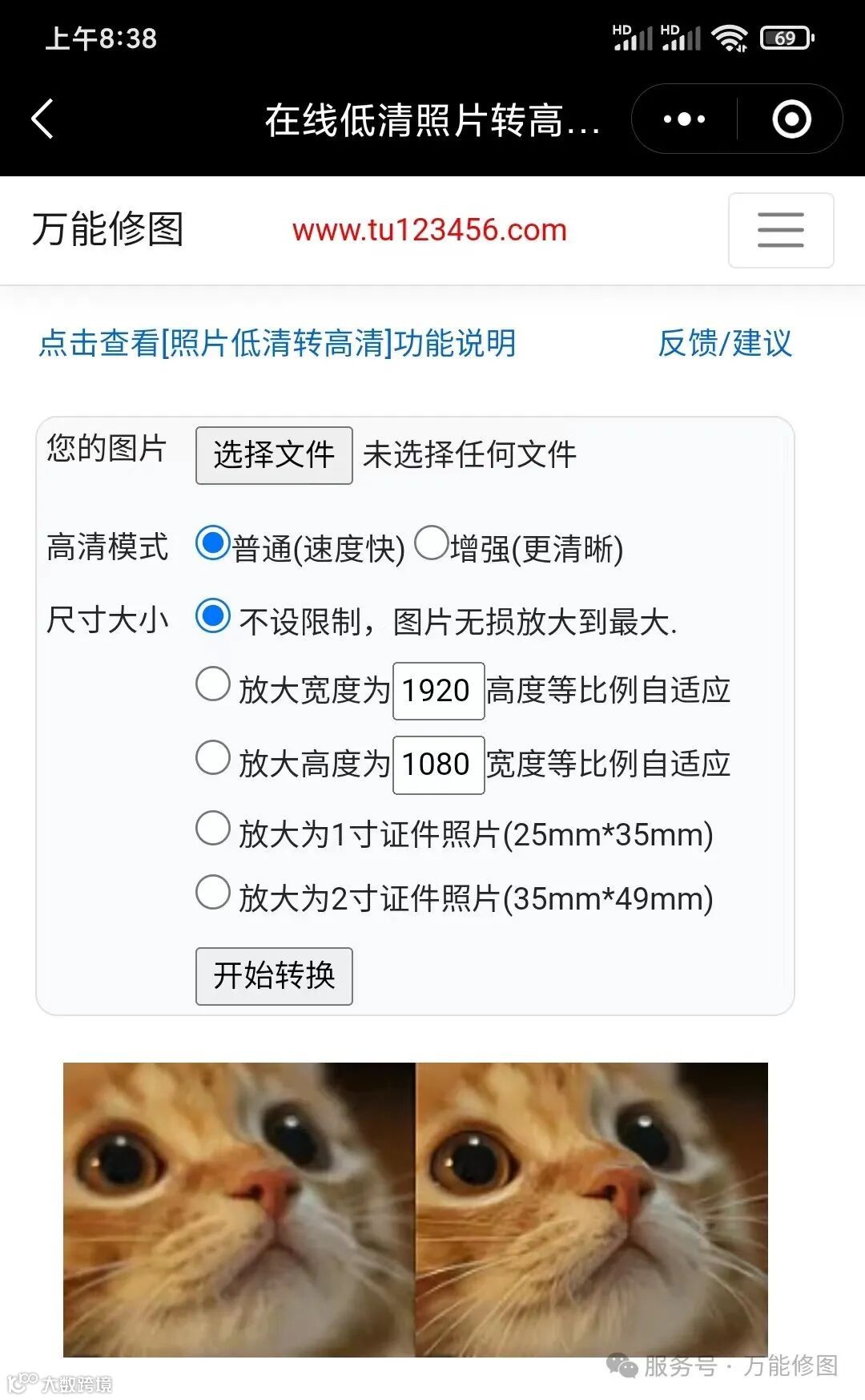
简单易用的AI人工智能在线图片处理工具平台(无需安装,“万能修图”微信小程序可直接在线处理照片和p图),各种图片、照片处理工具一应俱全,一键修图!
在线“图片低清转高清/无损放大”工具链接见本篇文章结尾。⬇️
图片放大,尤其是无损放大,一直是图像处理领域的一个核心挑战。人们常常需要将低分辨率的图片放大到更高的分辨率,以满足打印、展示或其他应用的需求。然而,简单的像素插值方法往往会造成图像模糊、细节丢失等问题,与“无损”的目标相去甚远。因此,探索有效且“无损”的图片放大技术具有重要的理论意义和实际应用价值。本文将探讨几种主要的图像放大技术,分析其优缺点,并展望未来发展方向。
首先,我们需要明确图片无损放大的含义。严格意义上讲,对数字图像的放大不可能是完全“无损”的。因为原始图像的信息量是有限的,放大后的图像像素数量增加,必然需要对缺失信息进行某种程度的估计或推断。因此,“无损放大”更准确的描述应该是“尽可能减少信息损失,并提升图像清晰度”。
目前,常见的图像放大技术主要包括以下几种:
1. 最近邻插值:这是最简单的一种插值方法,它直接将原图像像素复制到放大后的图像中对应位置。该方法计算速度快,但放大后的图像会出现明显的锯齿状边缘和马赛克效应,图像质量严重下降,因此不适合追求高质量放大的场景。
2. 双线性插值:该方法考虑了相邻四个像素点的灰度值,通过线性加权平均计算放大后像素点的灰度值。相比最近邻插值,双线性插值可以有效改善图像的平滑度,减少锯齿效应,但仍然会造成图像细节的模糊和损失。
3. 双三次插值:双三次插值利用周围16个像素点的灰度值进行加权平均,其计算复杂度高于双线性插值,但可以获得更好的图像质量,减少模糊现象,保留更多的细节。然而,它仍然无法从无到有地生成新的图像细节,只能对现有信息进行更精细的处理。
4. 基于样本的图像放大: 这类方法利用大量的图像样本进行训练,学习图像的内在结构和纹理信息。通过学习到的模型,可以对低分辨率图像进行更准确的细节重建,从而获得更高的放大倍率和更好的视觉效果。代表性的算法包括 SRCNN和 ESPCN。这类方法的优势在于可以有效地恢复图像细节,提升图像清晰度,但需要大量的训练数据,计算复杂度也相对较高。
5. 基于机器学习的超分辨率技术: 这是目前最先进的图像放大技术。它利用深度学习模型,例如卷积神经网络 (CNN),从大量低分辨率和高分辨率图像对中学习复杂的映射关系。通过这种方式,可以对低分辨率图像进行更加精确的重建,获得更高的分辨率和更清晰的图像质量。近年来,GAN也被广泛应用于超分辨率任务中,其生成图像的真实感和细节丰富度都得到了显著提升。

然而,即使是基于深度学习的超分辨率技术也存在一些局限性。例如:
1.对训练数据的依赖: 深度学习模型的性能高度依赖于训练数据的质量和数量。如果训练数据不足或质量较差,模型的泛化能力就会下降。
2.计算资源需求: 训练和应用深度学习模型通常需要大量的计算资源,这限制了其在一些资源受限的设备上的应用。
3.无法完全恢复丢失的信息: 即使是最好的超分辨率算法也无法从无到有地生成图像中缺失的信息。放大后的图像仍然可能存在一些失真。

展望未来,图像放大技术的进一步发展方向可能包括:
1.更强大的深度学习模型: 研究更高效、更强大的深度学习模型,例如改进的CNN架构、更有效的训练策略等。
2.多模态学习: 结合多种图像信息,例如颜色、纹理、边缘等,进行更全面的图像重建。
3.针对特定应用场景的优化: 针对不同的应用场景(例如医学影像、卫星图像等),设计专门优化的超分辨率算法。
4.轻量化模型: 开发更轻量级的深度学习模型,以便在资源受限的设备上运行。
总之,“无损放大”图像是一个充满挑战的问题。虽然目前的技术已经取得了显著的进步,但仍然存在一定的局限性。未来的研究需要不断探索新的算法和技术,以进一步提升图像放大效果,最终实现更接近“无损”的图像放大目标。 我们需要根据实际应用需求选择合适的放大方法,并认识到任何放大方法都存在一定的局限性,不可能完全避免信息损失。