
一、背景
NVIDIA 最近开放了其 GB300 SuperPod 集群参考架构,本文中我们结合其之前的 B200、B300 和 GB200 参考架构一起介绍。此外,这里主要以计算网络互联(后端网络)为主,存储网络,In-Band 网络,Out-of-Band 网络等类似,不再具体介绍。
相关资料可以参考笔者之前的文章:
二、相关 GPU
2.1 总览
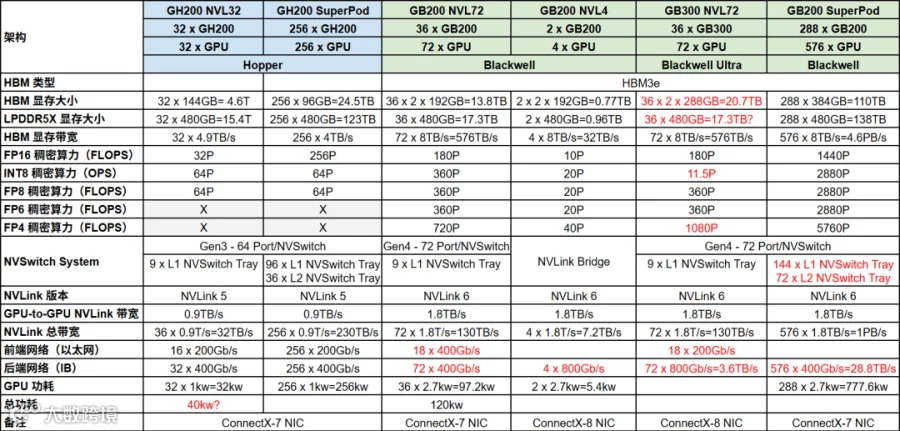
NVIDIA 当前最强的 GPU 包括 B200、B300、GB200 和 GB300,它们之间略微有些区别,如下图所示,主要体现在:
显存大小:192GB vs 288GB
对应网卡:400Gbps(CX-7) vs 800Gbps(CX-8)
TPU/SM 数量:74/148 vs 80/160
FP4 稠密算力:1 vs 1.5
NVLink 域:8 GPU vs 72 GPU
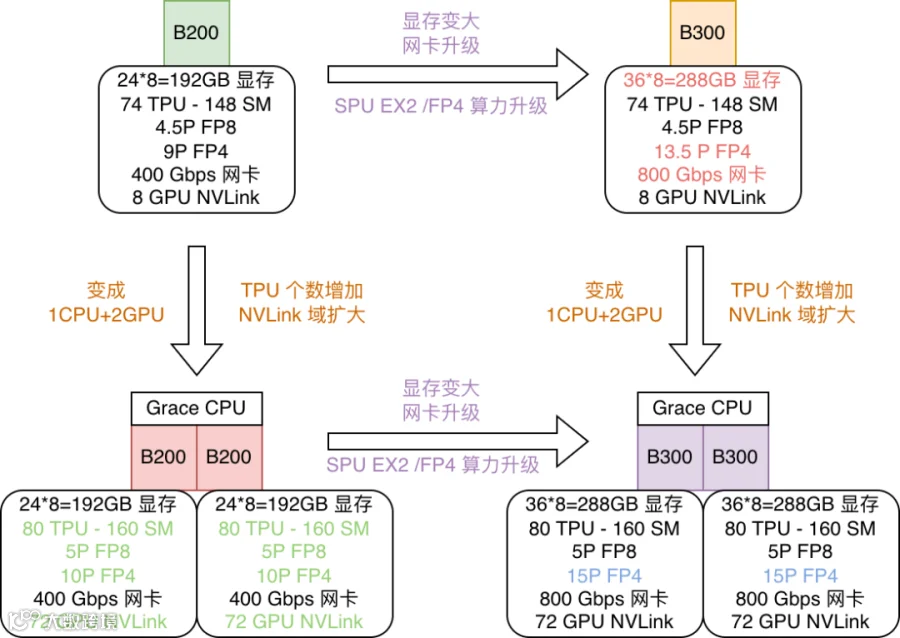
2.2 Blackwell B200
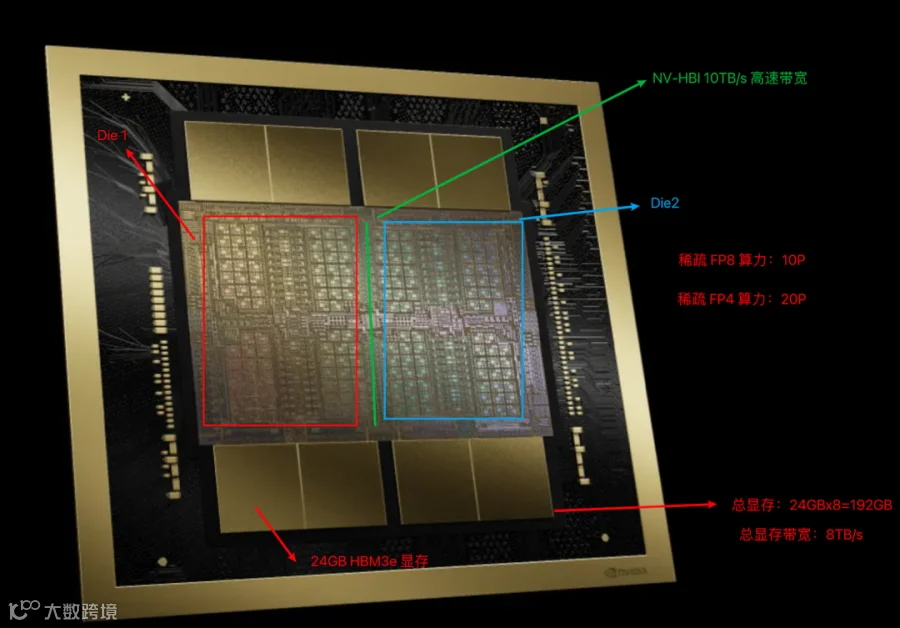
Blackwell B200 相比之前 NVIDIA GPU 的最主要区别是将两个 Die 封装到 1 个 GPU 中。如下所示,两个 Die 通过 NV-HBI 提供 10TB/s 的高速带宽。需要说明的是:
这里的算力是 Full GPU 算力,实际上 B200 的 稀疏 FP8 算力为 9P,也就是稠密 FP8 算力为 4.5P。这个主要差异是因为 Full Blackwell 有 80 个 TPC,而 B200 上实际只启用了 74 个,所以相应的算力大约为 74/80 (PS:还有频率的影响)。
8 个 24GB HBM3e Stack 对应 B200 的 192GB 显存;换成 8 个 36GB HBM3e Stack 则对应 B300 的 288GB 显存。
此外 B200 对应的后端网络是 400 Gbps 网卡。
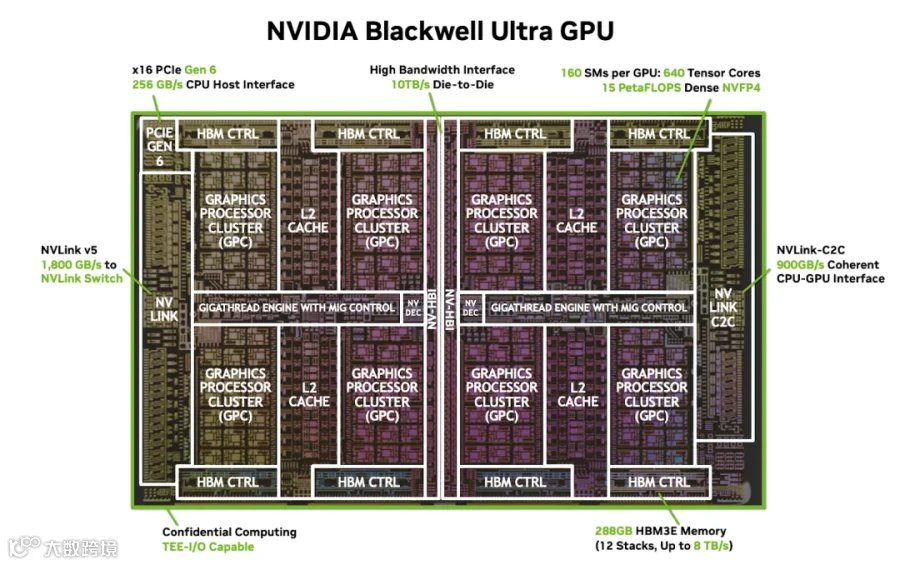
2.3 Blackwell B300
B300 相比 B200 整体架构略类似,个别配置有所不同:
显存:24GB Stack 换成 36GB Stack,8*24=192GB -> 8*36=288GB。
FP4 算力:
B300/GB300 的 FP4 Dense 算力是 FP8 Dense 算力的 3x。
但是 FP4 Sparse 算力依然是 FP8 Sparse 算力 2x。
也就是说:FP4 Dense 算力:9P -> 13.5P。
后端网络:CX7 400Gbps -> CX8 800Gbps。
功耗:1000W -> 1100W
Attention 加速(SFU EX2):H100(4.5T Exponentials/s) -> B200(5) -> B300(10.7)
2.4 Blackwell GB200/GB300
GB200/GB300 相比 B200/B300 的最大不同是包含了 2 个 GPU 和 1 个 Grace CPU。此外由于 GB200/GB300 中单个 GPU 包含完整的 80 个 TPC, 总体算力也会更大一些,大概是 B200/B300 的 80/74(PS:还有频率的影响)。比如:
B200/B300 vs GB200/GB300 FP16 算力:2.25P -> 2.5P x 2=4.5P。
B200 vs GB200 FP4 算力:9P -> 10P x 2=20P。
B300 vs GB300 FP4 算力:13.5P -> 15P x 2=30P。
B200/B300 vs GB200/GB300 功耗:1000W/1100W -> 2700W/?。

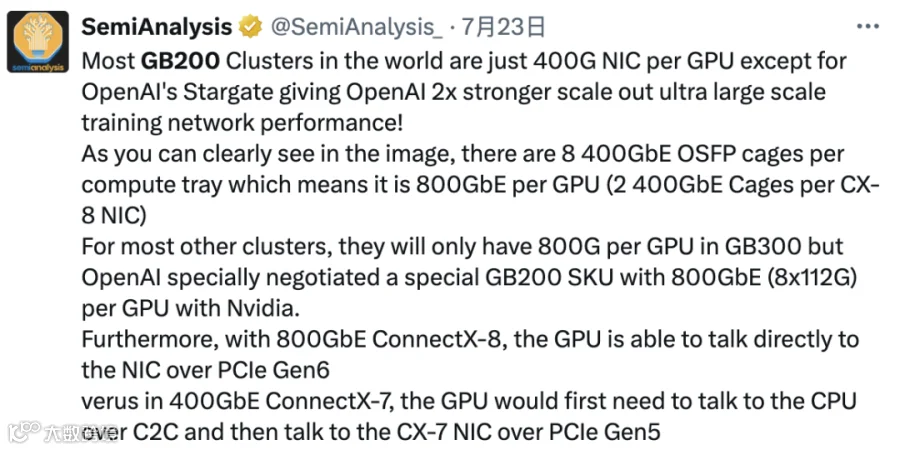
2.5 OpenAI Blackwell GB200
根据 SemiAnalysis 报道,OpenAI 和 NVIDIA 定制了 GB200 的后端网络方案,以便能支持 800Gbps 网络(PS:目前可能也只有 OpenAI 在 GB200 中用上了 800Gbps 网络)。

三、DGX & NVL72
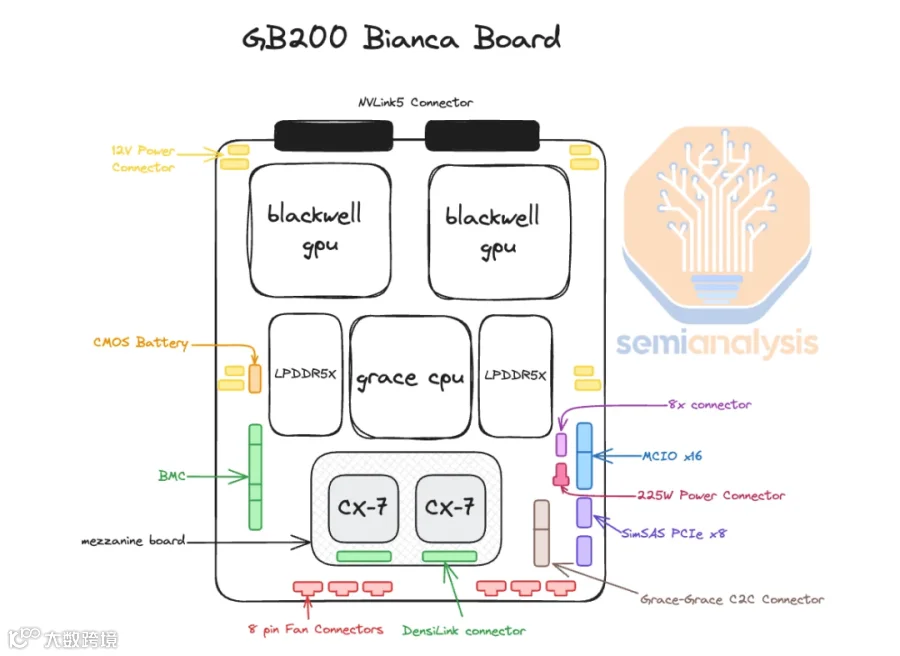
3.1 DGX B200 & DGX B300
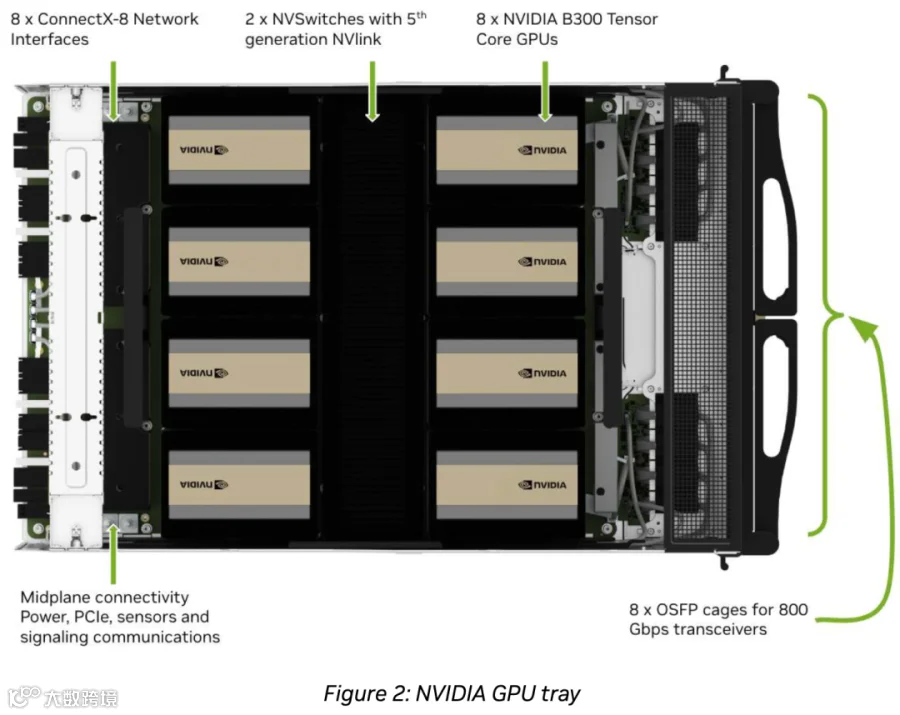
B200 和 B300 通常以 8 个 GPU 组成单个 Node,比如 NVIDIA 的 DGX(或 HGX)系列,如下图所示:
8 个 GPU 通过 NVLink + NVSwitch 实现全互联。
8 个 GPU 对应 8 个网卡(B200 对应 CX7,B300 对应 CX8)。
可以使用风冷,也可以使用液冷。
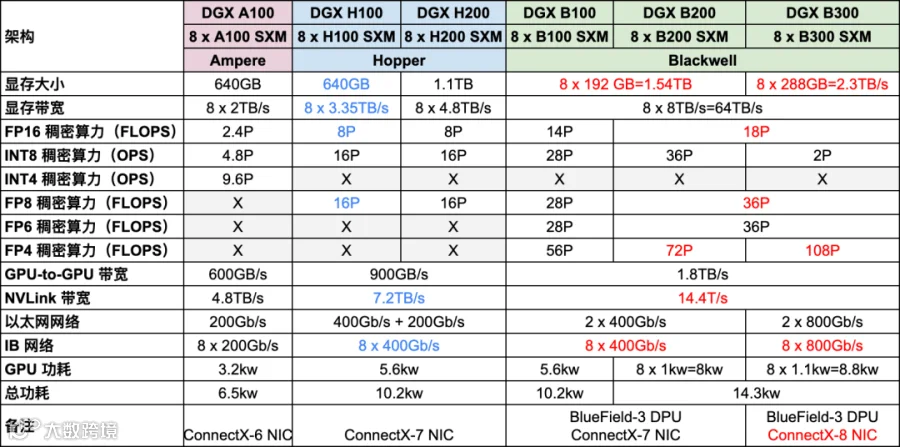
DGX B200 和 DGX B30 相应的具体配置以及与之前 DGX A100 和 DGX H100 对比如下图所示:
3.2 GB200 & GB300 NVL72
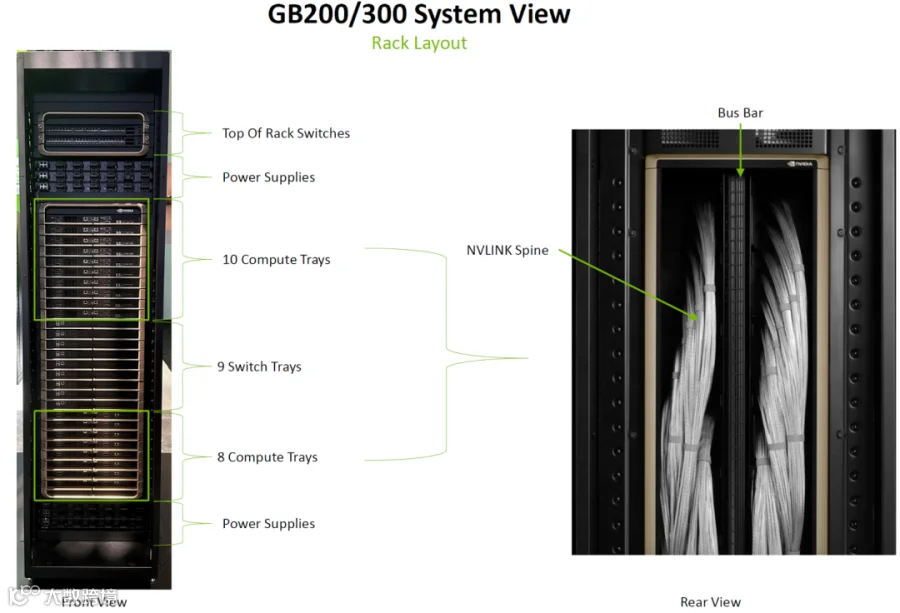
如下图所示,GB200 和 GB300 通常提供整机柜(Rack)的 72 GPU 方案,密度更高:
单 Rack 功耗达到 120kw,需要液冷。
18 个 Compute Tray,每个 Tray 包含 2 个 GB200/GB300(2 个 CPU、4 个 GPU)。
9 个 NVSwitch Tray,每个 Tray 包含 2 个 NVSwitch,每个 NVSwitch 72 个 Port,连接所有 GPU。
GB200 NVL72 提供 72 个 400Gb/s Port(CX-7),GB300 NVL72 提供 72 个 800Gb/s Port(CX-8)。
如下图所示,一个 NVSwitch 有 72 个 NVLink Port,因此一个 NVL72 需要 18 个 NVSwitch 把所有 GPU 全部互联起来。
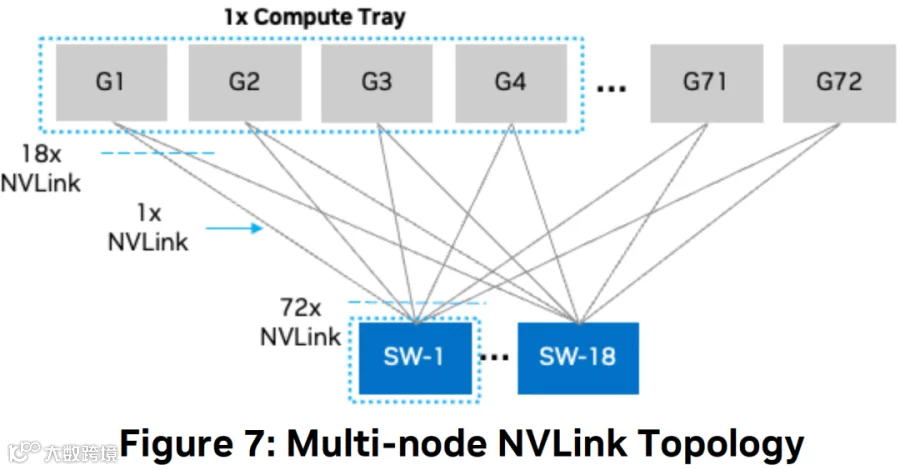
GB200 NVL72 和 GB300 NVL72 的详细配置以及与其他 SuperPod 的对比如下图所示:
四、相关网卡和交换机
4.1 网卡
4.1.1 CX8 SuperNIC
NVIDIA 在 CX-8 SuperNIC 中直接集成了 PCIe Switch,能提供 PCIe Gen6 Port。当前 B300 服务器都采用这种方式,还没有单独使用 PCIe Gen6 Switch 的方案,长期来看可能也是这种方式为主。
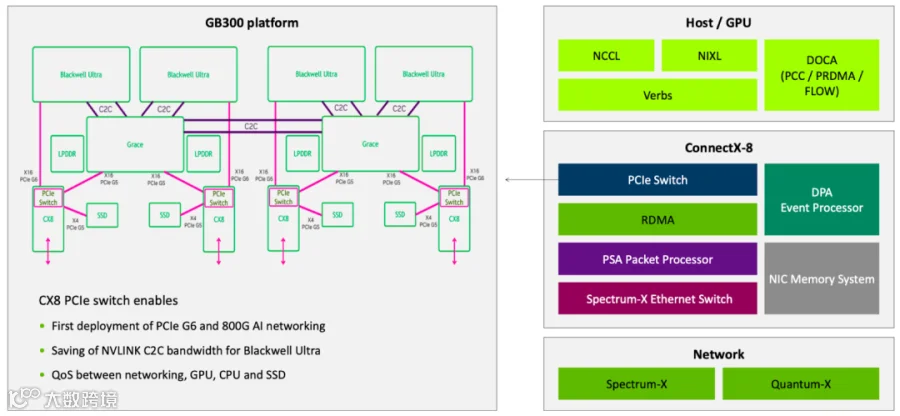
如下图所示,CX-8 SuperNIC 的 IB 模式支持 1 个 800Gb/s Port 或 2 个 400Gb/s Port。而 Ethernet 模式不支持 800 Gb/s Port,只能用 2 个 400Gb/s Port。


4.1.2 CX9 SuperNIC
NVIDIA 的下一代 CX9 SuperNIC 会解决 CX8 不支持 800Gbps 以太网 Port 的问题,也就更容易使用第三方的 800Gbps 以太网交换机。

4.2 网络交换机
4.2.1 QM9700
NVIDIA 上一代 Quantum-2 QM9700/9790 IB 交换机支持 64 个 400 Gbps Port,可提供 400 * 64 * 2 = 51.2 Tbps 的双向聚合带宽。

4.2.2 Spectrum-X800 SN5600 交换机
NVIDIA 最新的以太网交换机 SN5600,支持 64 个 800Gbps Port 或者 128 个 400 Gbps Port。会应用于 B300 集群的参考架构中。
如果使用 800Gb/s Port,SN5600 两层无收敛网络最多 64*64/2=2048 GPU。
如果使用 400Gb/s Port,SN5600 两层无收敛最多 128*128/2=8192 GPU。

4.2.3 Quantum-X800 Q3400 交换机
NVIDIA 也提供了最新的 IB 交换机 Quantum-X800 Q3400:
提供 144 个 800Gb/s 的 Port。
两层无收敛网络最多支持 144*144/2=10368 GPU。

五、NVIDIA Superpod GPU 集群
5.1 B200 SuperPod 参考架构
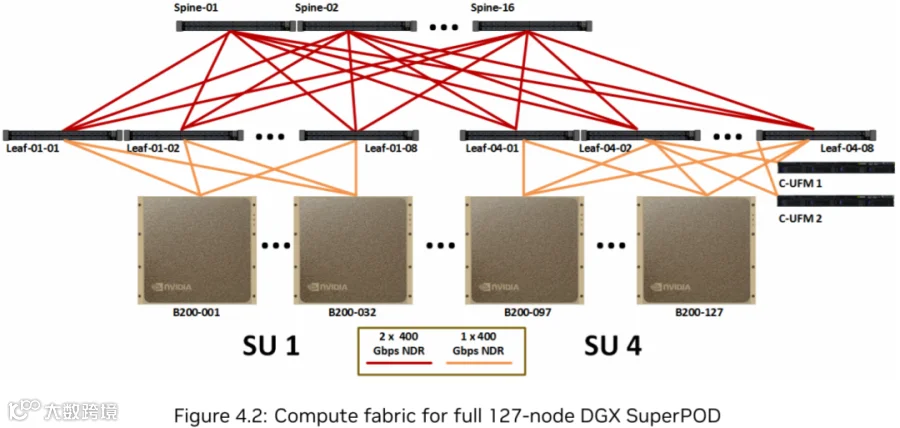
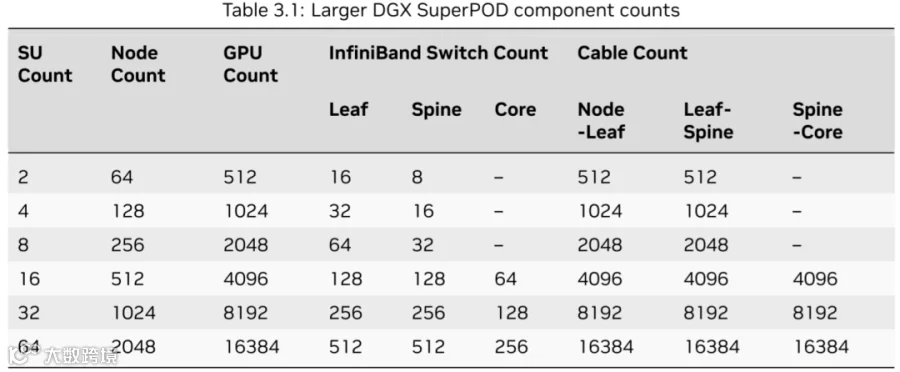
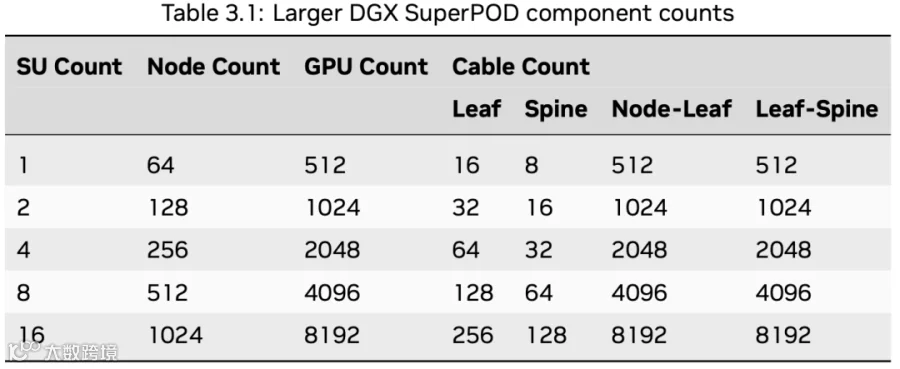
NVIDIA 在 DGX B300 SuperPod 的后端网络(计算网络)方案中采用了 QM9700 IB 交换机,支持 64 个 400 Gbps Port。两层互联方案如下图所示(4 SU,127 Node):
每个 SU 32 个 Node。主要是 Leaf Switch 只有 64 个 400Gbps Port,一半 Port 只能连 32 个 Node(轨道优化)。
由于最后一个 SU 的 Leaf Switch 要连 UFM,因此最后一个 SU 会少一个 Node。
实际上,两层无收敛网络最多连 64*64/2=2048 GPU。(PS:8 SU,实际上还要少 1 个 Node 8 个 GPU)
如下图所示,3 层网络则可以支持更大规模的 GPU 集群,与 H100 方案类似,比如:
64 个 SU,可以支持 2048 个 Node,16384 个 B200 GPU。当然也就需要 256 + 512 + 512=1280 个 QM9700 IB 交换机。
当然,如果可以使用上述的 SN5600 构建 2 层网络集群,最多可以支持 128*128/2 = 8192 B200 GPU。
5.2 B300 SuperPod 参考架构
NVIDIA 在 DGX B300 SuperPod 的后端网络(计算网络)方案中采用了 SN5600 交换机(以太网),最多只支持 64 个 800 Gbps Port,两层无收敛网络架构最多支持 2048 GPU。不过,当前的 CX-8 不支持 800Gbps 的以太网 Port。此外,为了支持更多 GPU,NVIDIA 采用了多平面设计,这里是两个平面(每个 800Gbps NIC 会分为 2 个 400Gbps Port,它们各自构成一个通信平面,后端网络可以看成 2 个平行、独立的 400Gbps 网络)。如下图所示:
一个 B300 Node 包含 8 个 B300 GPU,16 个 400Gbps Port,每 8 个一个平面(蓝色是一个平面,绿色是一个平面)。
每个 SU 包含 64 个 B300 Node,共 512 个 B300 GPU,连到 Leaf Switch。
SN5600 可以分为 128 个 400Gb/s Port,连接 64 个 Node。
每个 SU 会有 16 个 Leaf Switch。每个平面 8 个,对应 8*128=1024 个 400Gbps Port,一半连 GPU 网卡,一半连 Spine Switch 。
多个 SU 通过 Spine Switch 连接,16 个 SU 可以支持 8192 B300 GPU。
每个平面包含 8*16=128 个 Leaf Switch,需要 64 个 Spine Switch。
两个平面 64*2=128 个 Spine Switch。
这里的 Leaf 和 Spine Switch 都是上述的 SN5600 Switch。
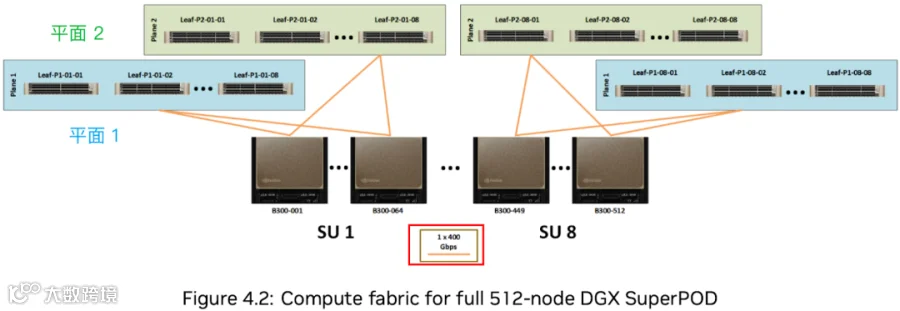
如下图所示,包括了不同 SU 对应的 Node 数量(GPU 数量)、Leaf Switch 和 Spine Switch 数量。
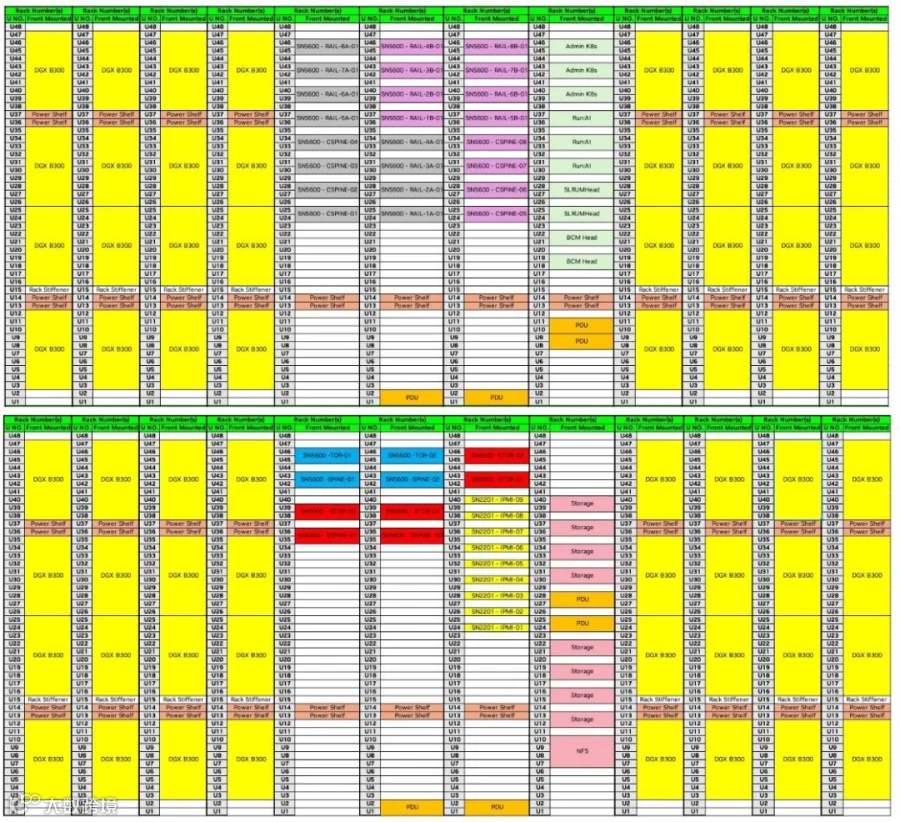
上述一个 SU 组成如下图所示:
8 个 GPU Rack,每个 Rack 包含 4 个 DGX B300 Node,共 32 B300 GPU,功耗达到 50kw。
其他几个 Rack 放置交换机,存储节点等。
5.3 GB200 SuperPod 参考架构
NVIDIA 的 GB200 SuperPod 参考架构中后端网络同样采用的是 QM9700 IB 交换机,最多支持 64 个 400 Gbps Port。因此相应的互联规模也有很大的局限性。
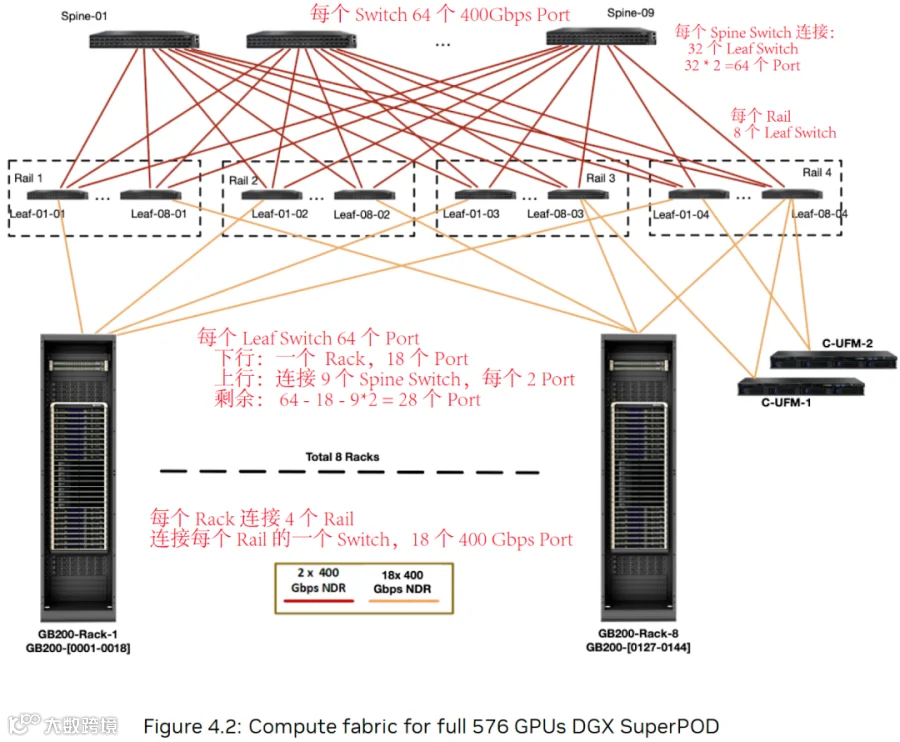
如下图所示,2 层网络只能支持 576 GPU(PS:这里存在很多 Port 浪费):
共 32 个 Leaf Switch,每 8 个一组为一个 Rail。Rail 中的每个 Leaf Switch 都连接一个 Rack。
每个 Rack 中的 18 个 400 Gbps Port 连接一个 Leaf Switch,共 72 个 Port,会连接 4 个 Rail。
Leaf Switch 中大量 Port 会浪费,下行 18 个 Port,为了无收敛,上行也是 18 个 Port(每个 Spine 连 2 个),浪费 28 个 Port。
9 个 Spine Switch 正好对应 64*9=576 个 GPU,无收敛(PS:相应的理论上只需要 18 个 Leaf Switch,实际上用了 32 个)。
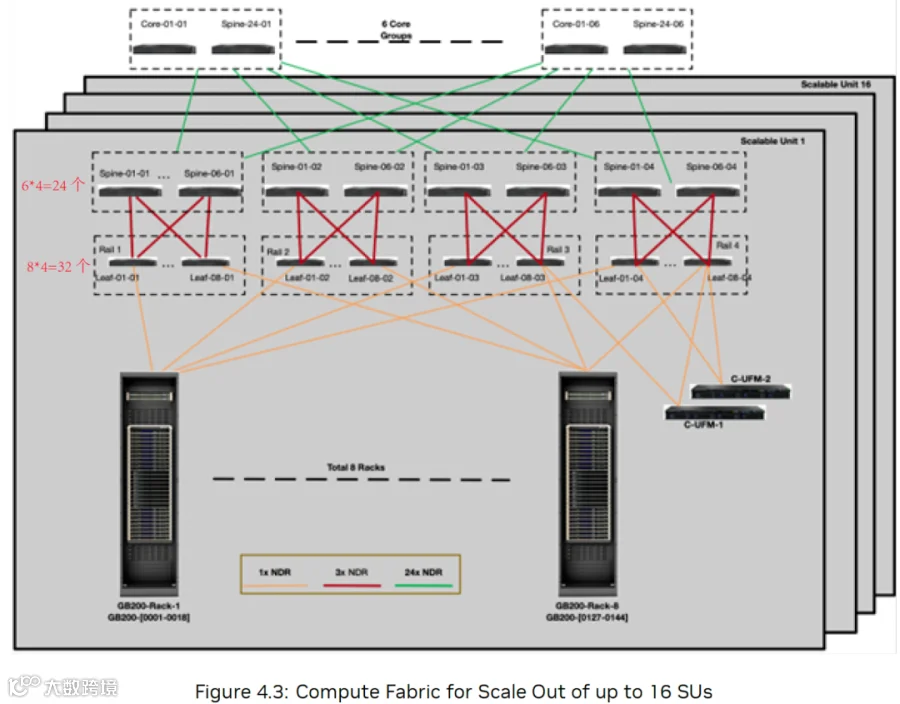
为了支持更大规模,只能采用 3 层网络架构:
每个 SU 8 个 GPU Rack,576 GPU:
还是 32 个 Leaf Switch,与 GPU Rack 的连接方式也不变。
24 个 Spine Switch,每个 Rail 里 6 个 Spine Switch 连接一个 Rail 里的 8 个 Leaf Switch。所以,Spine Switch 下行 Port 会有 8*18/6=24 个 Port 连接 Leaf Switch。
6 个 Core Group,每个 Core Group 中的 Core Switch 与 SU 数量呈正比(1 个 SU 对应 3 个 Switch),这里以 16 个 SU 为例:
共 24 * 16 = 384 个 Spine Switch,每个 Spine Switch 有 24 个上行 Port,所以有 24 * 384=9216 个上行 Port。
每个 Core Group 包含 24 个 Core Switch。共 6*24=144 个 Core Switch,对应 144*64=9216 个 Port,也就是 9216 个 GPU。
每个 Spine Switch 的 24 个上行 Port 对应一个 Core Group,这里每 Group 24 个 Core Switch,所以相当于一个 Spine Switch 的 24 个 Port 连接一个 Group 中的 24 个 Core Switch。每个 Rail 里 6 个 Spine Switch,对应 6 个 Group。
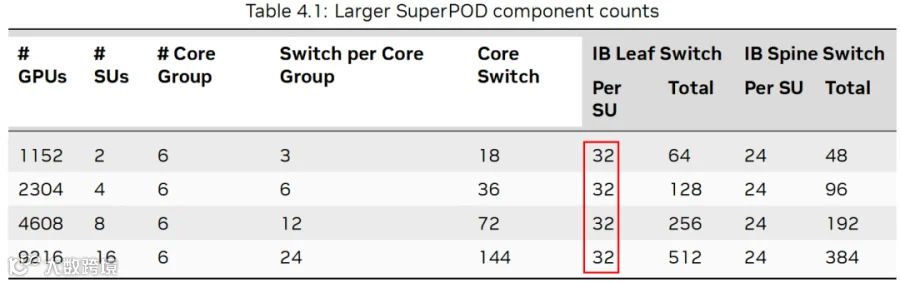
如下图所示,9216 GPU 的集群需要 144+512+384=1040 个 QM9700 Switch(共 1040*64=66560 个 400 Gbps Port )。
5.3 GB200 SuperPod 参考架构
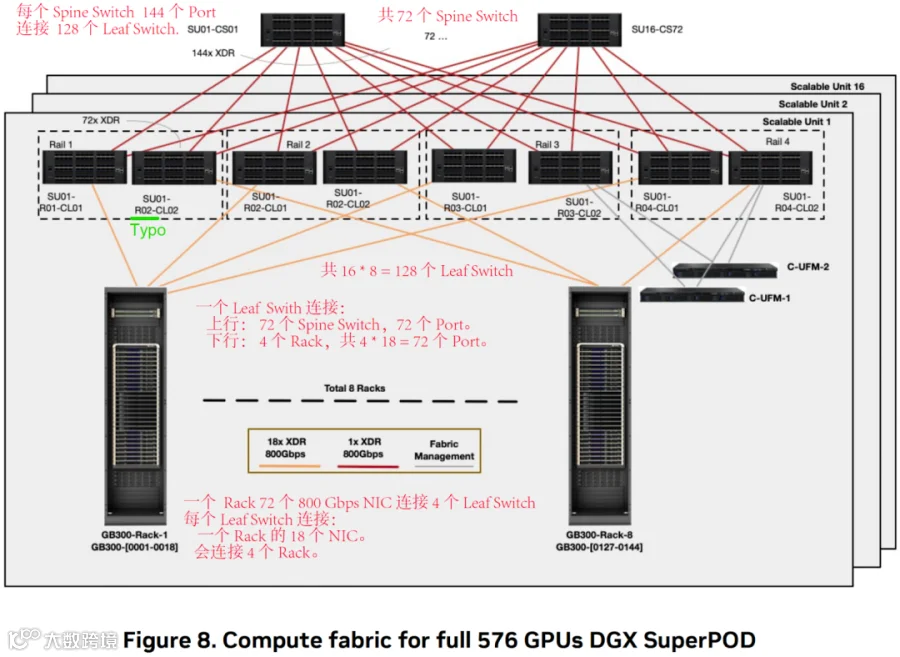
NVIDIA 也最新发布了 GB300 SuperPod 集群的参考架构,其后端网络采用最新的 Quantum-X800 Q3400 交换机组成 IB 网络,其包含 144 个 800 Gbps Port,相应的拓扑要简单的多:
每个 SU 包含:
8 个 NVL72 Rack = 576 GPU。
8 个 Leaf Switch,每个 Leaf Switch 144 个 800 Gbps Port。
一个 Leaf Switch 连接 4 个 Rack,占用 4 x 18 = 72 个 800 Gbps Port。
每两个 Leaf Switch 一组,构成一个 Rail,每组都会连接 8 个 Rack。
SuperPod 包括最多 16 个 SU:
72*8*16=9216 GPU。
对应 8 * 16(SU) = 128 个 Leaf Switch。
每个 Spine Switch 都会连接 128 个 Leaf Switch。
Leaf Switch 上行还剩 72 个 Port,72 个 Spine Switch 即可。
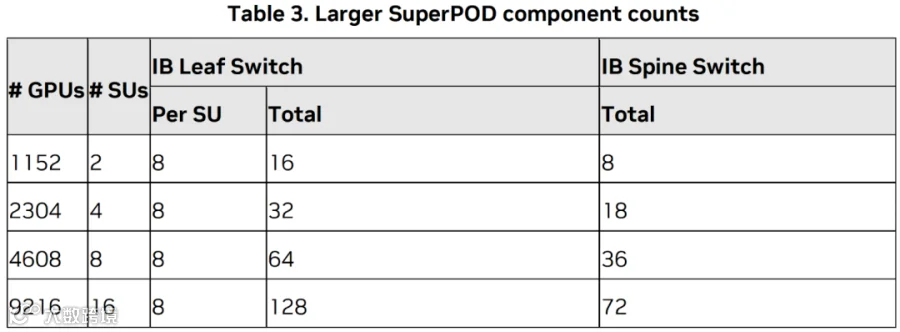
如下表所示为相应的 GPU 规模及对应的 SU 以及 Switch 个数,可以看出:
9216 GPU 只需要 128+72=200 个 Q3400(共 200*128=25600 个 800 Gbps Port)。
而 GB200 方案中,9216 GPU 需要 1040 个 QM9700(共 1040*64=66560 个 400 Gbps Port )。
六、参考链接
相关资料来自 NVIDIA 的官方文档,可以去 NVIDIA 官网查找。