
在当下的商业环境中,数据就是关键资源,网页抓取技术已成为企业获取竞争情报的基础设施。
然而,各种网站都在设法保护自己的数据安全,于是推出了各种防爬虫措施,这让数据采集变得越来越难了!
目标网站常常部署多重反爬虫技术:
IP封禁:检测到同一IP在短时间内发送大量请求时——触发自动封禁机制;
验证码与行为检测:通过图形验证码、滑动验证等方式识别异常访问行为;同时,通过分析访问频率、页面停留时间、鼠标轨迹等判断是否为机器;
设备指纹识别:综合考虑浏览器指纹、Cookie、User-Agent以及硬件信息,进一步提升反爬虫识别精度;
为什么python爬虫要用动态代理IP
先看例子,如果爬取时不用动态代理:
普通人访问一个平台一秒钟一般只能请求一到两次,但是我们在python爬取时一秒可能会发送几十上百次,这对于平台检测来说肯定是不正常的。
在这种情况下,平台就会让为你不是正常用户,很可能被判定为爬虫甚至直接封掉这个IP地址,这跟“露头就秒”没差,获取的数据就会中断。
并且,平台管理员也能通过技术手段查看到我们的真实地址,如果我们访问的是一个较有风险的网站,很可能被盗用信息。
根据这个例子,我们可以很明显的看到不用动态IP时,我们要面临的风险和挑战。
-
动态代理是什么?
动态代理IP就是指每一次的请求,我们都可以根据自身需求切换不同的IP进行访问,模拟各种真实用户访问目标网站。
方便更好理解,可以看下图。
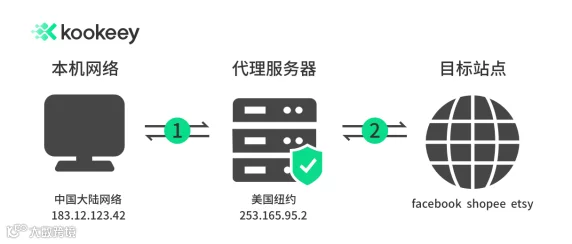
图解:不用代理时我们的访问线路是没有之间的代理步骤,而是直接从本机出发,到达目标点,这时候我们就是没有“马甲”的状态,当你大量爬取时,目标网站就能清晰的看到你的本机IP爬取过程。
而上图就是我们使用代理以后的线路,中间我们会通过一层代理服务器向目标网站访问,这时候目标网站是看不到我们的真实IP的,所以在就有效解决了安全风险,同时,通过多个IP的访问,能更好的爬取大量数据。
-
动态IP基本原理:
(核心在于“换马甲”)
代理池构建:多个可用的代理IP集中管理,定期检测其可用性和响应速度;
IP轮换策略:可以通过自身需求设置代理IP轮换,使每次访问都来自不同的网络地址,降低同一IP而频繁访问的风险;
智能调度:根据目标网站的响应与错误码反馈,调整代理IP的使用频率和切换速度,确保爬虫运行稳定性。
-
动态IP的核心优势:
规避封禁风险:分散请求来源,降低单个IP被封的概率;
真实流量模拟:不断变化的IP地址访问行为跟符合真人,伪装度更强;
高效分布式爬取:结合多线程与分布式架构,支持大规模并发访问效率拉满。
所以说,针对目前的市场需求,需要爬取大量的数据,单一的IP不能满足业务的实现,为了解决这个问题,就有了动态代理IP池。
如果某个IP被封,下一次请求就会自动切换到另一个IP,从而确保爬虫能连续运行。这样做不仅能有效规避封禁风险,还能大大提高数据抓取的成功率和效率。
想让整个爬取过程更加的稳定减少风险,动态的住宅IP时更好的选择,它的IP来真实的家庭宽带,不容易被封锁。
kookeey动态住宅IP,100%真人属性,4700万全球IP池,支持24小时灵活切换IP地址,99.9%连通率,毫秒级响应,不限制并发。
如何使用动态住宅代理IP
1、进入kookeey官网,购买动态代理,生成动态线路(设置好自己所需的IP条件);
2、通过Python配置kookeey代理;
·打开kookeey IP代理平台,复制一下代码(除端口信息),假如端口是http://gate.kookeey.io:15959,账号: kookeey,密码: 12345678 )。
import urllib.request;
proxy = urllib.request.ProxyHandler({'https': 'http://kookeey:12345678 @gate.kookeey.io:15959'})opener = urllib.request.build_opener(proxy)urllib.request.install_opener(opener)content = urllib.request.urlopen('https://lumtest.com/myip.json').read();print(content)
通过这个步骤,每次HTTP请求将自动使用代理IP,确保数据抓取过程更加稳定、风险更低。
掌握了这一技术,爬虫将更加隐蔽、稳定,并能应对大规模数据抓取的挑战。
小壳今天的内容就到这,有什么问题欢迎提问!
