
MetaAI 刚刚开源了 Llama2 模型,不仅开源了预训练模型,而且还开源了利用对话数据微调后的 Llama2-Chat 模型。随着 Llama2 系列模型的发布,Meta 也在开源世界越走越远。
Llama2 简介
Llama 2 是预训练和微调的生成文本模型的集合, 其规模从 7 亿到 70 亿个参数不等。

Meta 还发布了微调的LLM, 称为 Llama-2-Chat,针对对话用例进行了优化。在我们测试的大多数基准测试中, Llama-2-Chat 模型的性能优于开源聊天模型,并且在我们对有用性和安全性的人工评估中, 与一些流行的闭源模型(如 ChatGPT 和 PaLM)相当。
开源模型目前有7B、13B、70B三种尺寸, 预训练阶段使用了2万亿Token, SFT阶段使用了超过10w数据, 人类偏好数据超过100w。

- https://huggingface.co/meta-llama
Llama2 性能
在 Meta 的论文中,首先就放了和包括 OpenAI 的 ChatGPT 3,Google PaLM 的 PK 图, 可谓是火药味十足。


上下文
上下文长度:Llama 2 的上下文窗口从 2048 个标记扩展到 4096 个字符。越长上下文窗口使模型能够处理更多信息, 这对于支持聊天应用程序中较长的历史记录、 各种摘要任务以及理解较长的文档。多个评测结果表示较长的上下文模型在各种通用任务上保持了强大的性能。

Grouped-Query Attention 分组查询注意力
关于 Llama 2 中的分组查询注意力,大家感兴趣直接去看 Meta 的论文即可,我就不瞎解释了。
给大家看下在新架构下的性能。

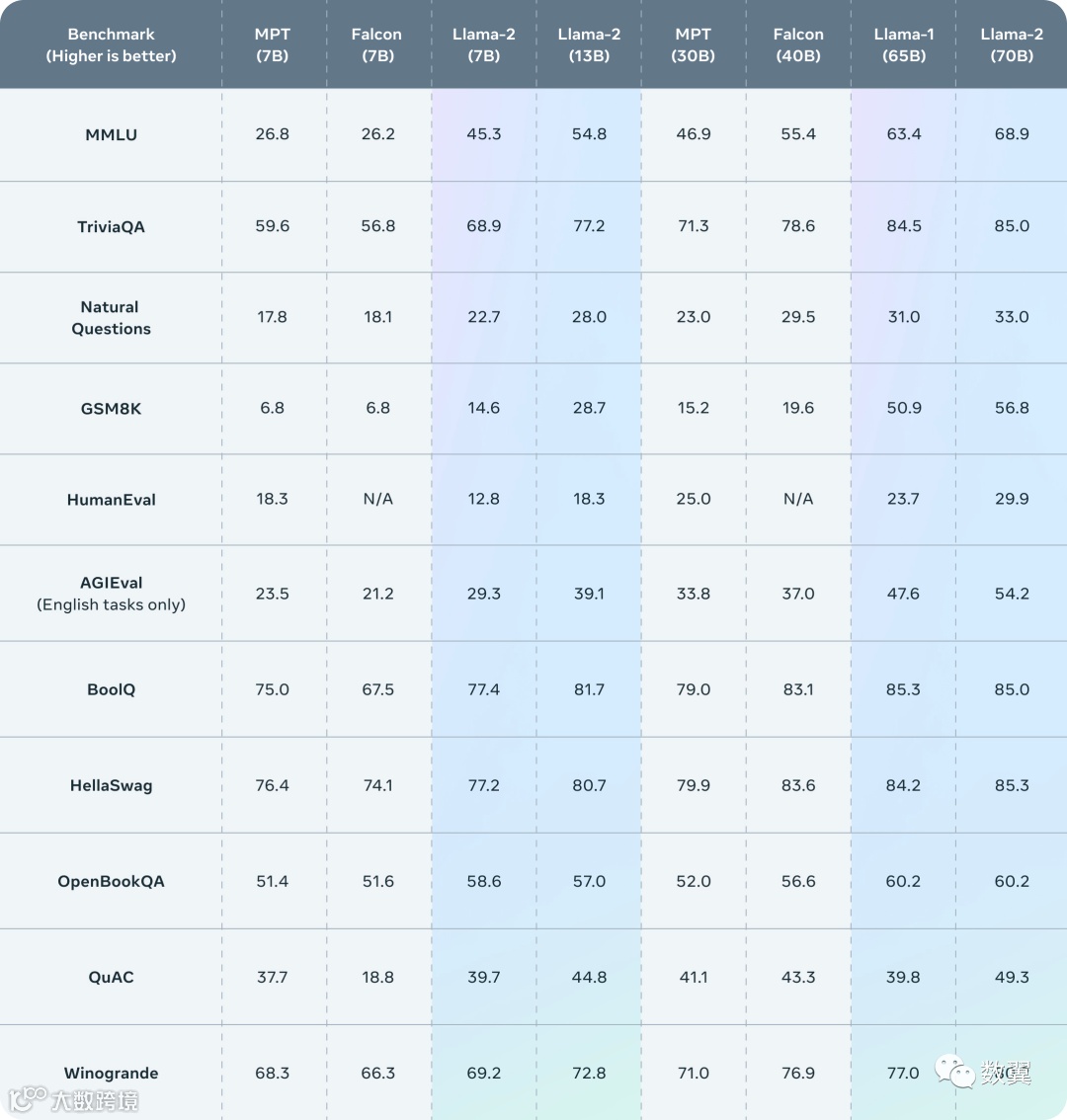
Llama 2 的评估结果
Llama 2 在许多外部基准测试中都优于其他开源语言模型。
这是官网的评估结果:
下面是论文中的:

Llama 2-Chat
Meta 还专门微调了一个对话模型。

商用
Llama 2 有友好的商业许可证,也就是你小打小闹都可以随意商用。
中文支持
虽然 Llama 2 的训练数据只有不足 1% 的中文数据,但是可以肯定的是中文世界的 Llama 2 马上就会跟上。
不是经常有人开玩笑说,Llama 2 一开源,国内立马就会有无数企业自主研发并且赶超 ChatGPT。
如何使用
HuggingFace
在 HuggingFace 上申请:
https://huggingface.co/meta-llama/Llama-2-70b-chat-hf
 HuggingFace 上申请 Llama 2
HuggingFace 上申请 Llama 2
可以先试用一下在线的应用(在模型页可以照到很多):
比如:https://huggingface.co/spaces/ysharma/Explore_llamav2_with_TGI
小测试了一下:
 在线使用 Llama 2
在线使用 Llama 2
Meta
当然我们也可以在 Meta 自家网站上下载,当然前提是先申请。
我也申请了,
• https://ai.meta.com/resources/models-and-libraries/llama-downloads/
 Llama 2 申请表单
Llama 2 申请表单
而且很快就得到回复,明天下载运行看看:

其他云厂商
当然 Meta 也和 微软、AWS 等厂商密切合作,你也可以在他们的云服务商部署 Llama 2 模型。
关于 Meta 的开源之路
最近, Meta 在开源 AI 领域的足迹不断扩大,HuggingFace 上有超过 600 个模型,例如 我们之前介绍过的 MusicGen、Galacica、Wav2Vec 等。
这点,Meta 倒是比微软、谷歌做的都好,但是同样的 Meta 的底子不厚,开源这条路还真的挺适合他。
 Llama 2 模型下载申请通过邮件
Llama 2 模型下载申请通过邮件
参考:
• https://ai.meta.com/llama/
• https://huggingface.co/meta-llama
• https://huggingface.co/blog/llama2
• https://huggingface.co/facebook
• https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
• https://github.com/huggingface/transformers/
• https://ai.meta.com/resources/models-and-libraries/llama-downloads/
• https://github.com/facebookresearch/llama/blob/main/README.md
--- END ---