
一、为什么需要read_csv()?
在数据分析的旅程中,我们经常需要从CSV(Comma Separated Values,逗号分隔值)文件中读取数据。CSV是一种常见的数据存储格式,由于其简单性和通用性,被广泛应用于各种领域。Pandas库中的read_csv()函数为我们提供了一个方便、高效的方式来读取这些数据。
二、read_csv()的基本用法
使用read_csv()函数读取CSV文件的基本语法是:
import pandas as pddata = pd.read_csv('file_path.csv')
其中,file_path.csv是你的CSV文件的路径。
例如,如果你有一个名为data.csv的文件,你可以这样读取它:
data = pd.read_csv('data.csv')print(data)
输出:
StringColumn IntColumn FloatColumn BoolColumn MixedColumn0 A 0 0.311623 False class11 B 1 0.377196 True class22 C 2 0.930861 True class3
三、read_csv()的参数
read_csv()函数有许多参数可以帮助我们更好地处理数据。以下是一些常用的参数:
1.sep 或 delimiter:指定分隔符,默认为,。如果你的CSV文件使用的是其他分隔符,如\t(制表符),你可以这样指定:
data = pd.read_csv('data.csv', sep='\t')2.header:指定表头行。默认为0,表示第一行是表头。如果CSV文件没有表头,你可以设置为None。
data = pd.read_csv('data.csv', header=None)3.index_col:将某一列设置为索引。
index_col:将某一列设置为索引。输出:
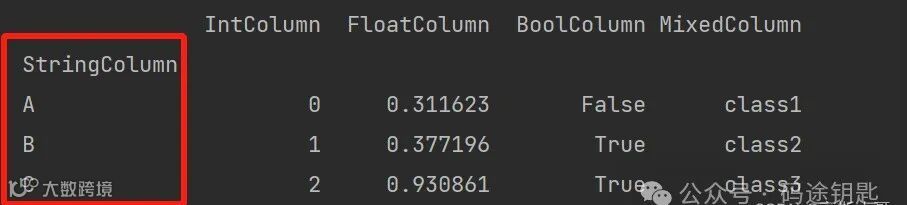
4.usecols:选择读取的列。你可以传入一个列名的列表,或者一个整数列表来表示列的索引。
data = pd.read_csv('data.csv', usecols=['IntColumn', 'FloatColumn'])print(data)
或者
data = pd.read_csv('data.csv', usecols=[1, 2])输出:
IntColumn FloatColumn0 0 0.3116231 1 0.3771962 2 0.930861
data = pd.read_csv('data.csv', na_values=['N/A', 'nan'])6.dtype:指定列的数据类型(谨慎使用,具体情况具体分析,容易报错)。
data = pd.read_csv('data.csv', dtype={'StringColumn': str, 'IntColumn': int})这只是read_csv()函数的一部分参数,还有更多参数可以帮助你更好地处理CSV文件。
四、实际案例应用
假设你有一个名为sales.csv的CSV文件,其中包含以下数据:
date,product,sales2023-01-01,A,1002023-01-02,B,1502023-01-03,A,2002023-01-04,C,250
你可以使用read_csv()函数读取这个文件,并进行一些数据分析。
import pandas as pd# 读取CSV文件data= pd.read_csv('sales.csv')# 查看数据print(data)print("*"*50)# 计算每个产品的总销售额total_sales = data.groupby('product')['sales'].sum()print(total_sales)print("*"*50)# 计算每个日期的销售额daily_sales = data.groupby('date')['sales'].sum()print(daily_sales)
输出:
date product sales0 2023-01-01 A 1001 2023-01-02 B 1502 2023-01-03 A 2003 2023-01-04 C 250**************************************************productA 300B 150C 250Name: sales, dtype: int64**************************************************date2023-01-01 1002023-01-02 1502023-01-03 2002023-01-04 250Name: sales, dtype: int64
这个例子中,我们首先使用read_csv()函数读取了CSV文件。然后,我们使用groupby()函数按产品和日期对数据进行分组,并使用sum()函数计算每个组的销售额。最后,我们打印了结果。
五、总结
read_csv()函数是Pandas库中一个非常重要的函数,它为我们提供了一个方便、高效的方式来读取CSV文件。通过掌握read_csv()函数的基本用法和参数,我们可以轻松地处理各种CSV文件,并进行数据分析和处理。
在本文中,我们详细介绍了read_csv()函数的基本用法。我们还通过一个实际案例演示了如何使用read_csv()函数进行数据分析。希望这篇文章能帮助你更好地理解和使用read_csv()函数,为你的数据分析工作带来便利。


