
本文转自:Spark技术日报
1. 数据确实不稳定,例如晚上的时候访问流量特别大
2. 在处理的时候例如GC的时候耽误时间会产生delay延迟
基本思想:根据上一次计算的Job的一些信息评估来决定下一个Job数据接收的速度。
如何限制Spark接收数据的速度?
Spark Streaming在接收数据的时候必须把当前的数据接收完毕才能接收下一条数据。
源码解析
RateController:
RateController是监听器,继承自StreamingListener.
/**
* A StreamingListener that receives batch completion updates, and maintains
* an estimate of the speed at which this stream should ingest messages,
* given an estimate computation from a `RateEstimator`
*/
private[streaming] abstract class RateController(val streamUID: Int, rateEstimator: RateEstimator)
extends StreamingListener with Serializable {
问题来了,RateContoller什么时候被调用的呢?
BackPressure是根据上一次计算的Job信息来评估下一个Job数据接收的速度。因此肯定是在JobScheduler中被调用的。
// attach rate controllers of input streams to receive batch completion updates
for {
inputDStream <- ssc.graph.getInputStreams
rateController <- inputDStream.rateController
} ssc.addStreamingListener(rateController)
/** Add a [[org.apache.spark.streaming.scheduler.StreamingListener]] object for
* receiving system events related to streaming.
*/
def addStreamingListener(streamingListener: StreamingListener) {
scheduler.listenerBus.addListener(streamingListener)
}
}
/** Asynchronously passes StreamingListenerEvents to registered StreamingListeners. */
private[spark] class StreamingListenerBus
extends AsynchronousListenerBus[StreamingListener, StreamingListenerEvent]("StreamingListenerBus")
with Logging {
private val logDroppedEvent = new AtomicBoolean(false)
override def onPostEvent(listener: StreamingListener, event: StreamingListenerEvent): Unit = {
event match {
case receiverStarted: StreamingListenerReceiverStarted =>
listener.onReceiverStarted(receiverStarted)
case receiverError: StreamingListenerReceiverError =>
listener.onReceiverError(receiverError)
case receiverStopped: StreamingListenerReceiverStopped =>
listener.onReceiverStopped(receiverStopped)
case batchSubmitted: StreamingListenerBatchSubmitted =>
listener.onBatchSubmitted(batchSubmitted)
case batchStarted: StreamingListenerBatchStarted =>
listener.onBatchStarted(batchStarted)
case batchCompleted: StreamingListenerBatchCompleted =>
listener.onBatchCompleted(batchCompleted)

override def onBatchCompleted(batchCompleted: StreamingListenerBatchCompleted) {
val elements = batchCompleted.batchInfo.streamIdToInputInfo
for {
processingEnd <- batchCompleted.batchInfo.processingEndTime
workDelay <- batchCompleted.batchInfo.processingDelay
waitDelay <- batchCompleted.batchInfo.schedulingDelay
elems <- elements.get(streamUID).map(_.numRecords)
} computeAndPublish(processingEnd, elems, workDelay, waitDelay)
}
/**
* Compute the new rate limit and publish it asynchronously.
*/
private def computeAndPublish(time: Long, elems: Long, workDelay: Long, waitDelay: Long): Unit =
Future[Unit] {
//评估新的更加合适Rate速度。
val newRate = rateEstimator.compute(time, elems, workDelay, waitDelay)
newRate.foreach { s =>
rateLimit.set(s.toLong)
publish(getLatestRate())
}
}
/**
* A RateController that sends the new rate to receivers, via the receiver tracker.
*/
private[streaming] class ReceiverRateController(id: Int, estimator: RateEstimator)
extends RateController(id, estimator) {
override def publish(rate: Long): Unit =
//因为会有很多RateController所以会有具体Id
ssc.scheduler.receiverTracker.sendRateUpdate(id, rate)
}
此时的endpoint是ReceiverTrackerEndpoint。
/** Update a receiver's maximum ingestion rate */
def sendRateUpdate(streamUID: Int, newRate: Long): Unit = synchronized {
if (isTrackerStarted) {
endpoint.send(UpdateReceiverRateLimit(streamUID, newRate))
}
}
case UpdateReceiverRateLimit(streamUID, newRate) =>
//根据receiverTrackingInfos获取info信息,然后根据endpoint获取通信句柄。
//此时endpoint是ReceiverSupervisor的endpoint通信实体。
for (info <- receiverTrackingInfos.get(streamUID); eP <- info.endpoint) {
eP.send(UpdateRateLimit(newRate))
}
/** RpcEndpointRef for receiving messages from the ReceiverTracker in the driver */
private val endpoint = env.rpcEnv.setupEndpoint(
"Receiver-" + streamId + "-" + System.currentTimeMillis(), new ThreadSafeRpcEndpoint {
override val rpcEnv: RpcEnv = env.rpcEnv
override def receive: PartialFunction[Any, Unit] = {
case StopReceiver =>
logInfo("Received stop signal")
ReceiverSupervisorImpl.this.stop("Stopped by driver", None)
case CleanupOldBlocks(threshTime) =>
logDebug("Received delete old batch signal")
cleanupOldBlocks(threshTime)
case UpdateRateLimit(eps) =>
logInfo(s"Received a new rate limit: $eps.")
registeredBlockGenerators.foreach { bg =>
bg.updateRate(eps)
}
}
})
/**
* Set the rate limit to `newRate`. The new rate will not exceed the maximum rate configured by
//这里有最大限制,因为你的集群处理规模是有限的。
//Spark Streaming可能运行在YARN之上,因为多个计算框架都在运行的话,资源就//更有限了。
* {{{spark.streaming.receiver.maxRate}}}, even if `newRate` is higher than that.
*
* @param newRate A new rate in events per second. It has no effect if it's 0 or negative.
*/
private[receiver] def updateRate(newRate: Long): Unit =
if (newRate > 0) {
if (maxRateLimit > 0) {
rateLimiter.setRate(newRate.min(maxRateLimit))
} else {
rateLimiter.setRate(newRate)
}
}
总体流程图如下:
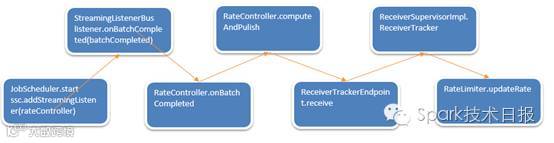
总结:
每次上一个Batch Duration的Job执行完成之后,都会返回JobCompleted等信息,基于这些信息产生一个新的Rate,然后将新的Rate通过远程通信交给了Executor中,而Executor也会根据Rate重新设置Rate大小