
Arxiv最新:RL新范式!GoRL如何打破"稳定"与"表达力"的零和博弈?

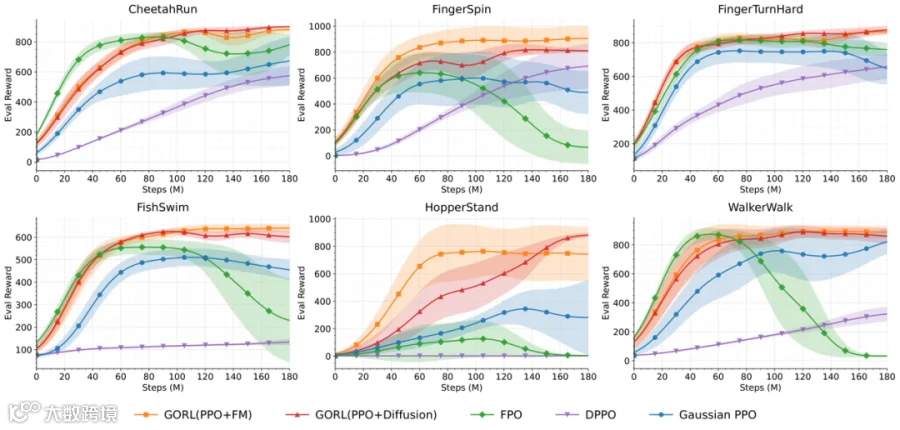
在强化学习(RL)里,我们似乎总是面临一个残酷的二选一:要么选择高斯策略,求稳但表达力有限;要么选择生成式策略(如扩散策略 Diffusion Policy),够强但主要为模仿学习(行为克隆)设计,在线训练极不稳定。这篇论文提出了一种结构性的解耦框架——GoRL。它不强行魔改梯度,而是将“大脑”(策略优化)与“肢体”(动作生成)分离,实现了既稳又强的控制效果。在 HopperStand 等高难度任务上,Gaussian PPO 与 FPO 等基线的平均回报长期停滞在 300 以下,而 GoRL 最终突破 870,优势极其显著。 🚀
🔍 引言:RL控制的“梦想与现实”
在连续控制领域,我们都梦想着 Agent 能像人类一样,拥有处理复杂情况的“多模态”能力——面对障碍物,既能向左闪避,也能向右跳跃,而不是卡在中间不知所措。
然而,现实是骨感的,我们手中的工具往往难以两全:
核心痛点:“表达能力”与“优化稳定性”似乎是一场零和博弈。 现有的端到端方法(如 FPO)试图通过近似梯度来强行训练,但往往牺牲了熵正则化(Entropy Regularization),导致在长视界任务中容易失效。这正是 GoRL 要解决的——它给出了一个无需复杂梯度近似的优雅解法。
🛠️ 方法详解:GoRL的“双核”炼金术
GoRL 的核心逻辑非常直观:既然生成模型的梯度难算,那我们就不直接算它,让生成模型干它擅长的事!
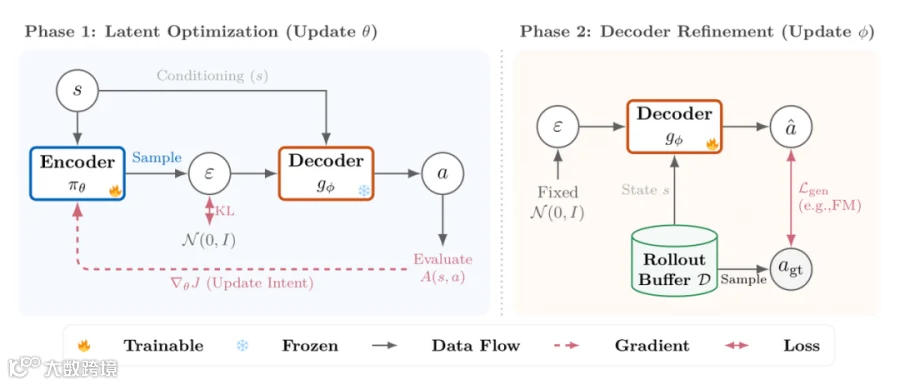
作者将策略拆解为两个部分:Encoder(大脑) 负责决策意图,Decoder(肢体) 负责将意图转化为复杂动作。整个训练过程采用**双时间尺度(Two-Time-Scale)**交替进行。
第一步:潜在空间优化 (Latent Optimization) —— 稳练脑 🧠
第二步:解码器精炼 (Decoder Refinement) —— 强练体 💪
📊 实验成果:性能与多模态的双重胜利
作者在 DMControl Suite 上对比了高斯 PPO 及最新的生成式基线(FPO, DPPO),结果令人印象深刻!🎯
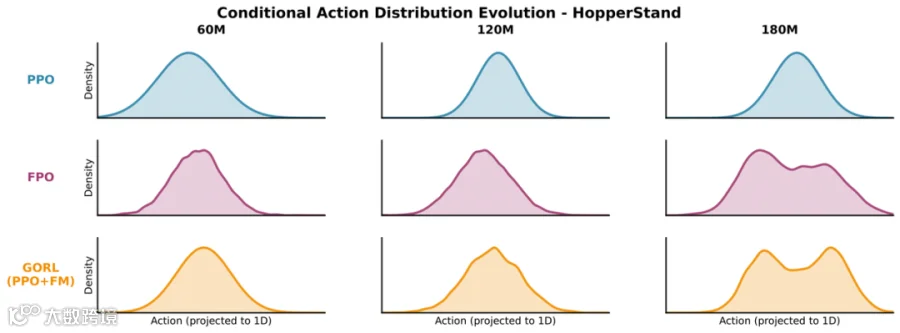
* **PPO**:受限于单峰假设,始终无法分化。 * **GoRL**:随着训练进行,清晰地演化出了**双峰 (Bimodal)** 分布,真正掌握了多模态控制策略。🔬 深度分析:为什么端到端在线优化容易塌陷?
论文观察到,端到端优化的代表性方法 FPO 在 6 个测试任务中的 4 个都出现了中后期性能崩塌(Collapse)。
作者将其归因于:为了绕过梯度计算,FPO 使用了 Surrogate Objective(替代目标),这导致它在在线分布漂移下可能与真实策略梯度失配;同时,Flow Matching 本身缺乏对策略熵的直接控制机制,导致探索能力在训练后期迅速枯竭。相比之下,GoRL 在潜在空间做标准 PPO,天然保留了熵正则化,保证了持续探索的能力。
💎 Q&A
1. GoRL 的适用范围?
答:GoRL 是一个 Algorithm-Agnostic (算法无关) 的框架。你可以自由选择 Diffusion 或 Flow Matching 作为 Decoder(文中均有实现)。在强化学习算法侧,虽然文中以 PPO 为例,但论文讨论了未来向 SAC 等 Off-policy 方法扩展的可能性。适用范围提示:当前主要验证了 On-policy + 低维状态的控制任务。
2. 既然 Encoder 每次都要重置,会不会学得很慢?
答:不会。因为 Decoder(肢体)在不断变强,它能把简单的标准正态分布映射成越来越牛的动作。每次重置 Encoder,相当于让大脑在一个已经很强的身体上重新适应(Behavioral Warm Start),实际上加速了收敛。
3. GoRL 的代价是什么?
答:天下没有免费的午餐。GoRL 需要维护两个网络(Encoder 和 Decoder),且采用交替训练模式,这意味着计算开销和工程复杂度会高于端到端的 MLP 策略。但这换来的是生成式策略在 Online RL 中真正的可用性与高性能。
💡 思路启发
GoRL 的成功给我们提供了一个处理复杂系统的思路:不要试图硬刚数学上极其复杂的梯度路径。
通过引入中间层(Latent Space),将“难优化”的生成部分和“需优化”的决策部分拆开处理,反而能取得意想不到的效果。这对于我们在大模型微调、复杂系统控制等领域的设计都有很好的借鉴意义。
🏅 点评
📚 参考文献
恭喜你!又跟着哆啦b梦读完了一篇前沿论文!
后续作者也会进行分享会,欢迎关注~~~
如果觉得对你有帮助,请积极关注、推荐(点个在看)或者转发哦~ 您的支持是我持续输出的动力!🤝