
上篇文章我们介绍了蚂蚁集团专家介绍RDMA技术系列专题的文章
1、RDMA技术概述
2、RDMA收发机制
本期我们继续介绍RDMA技术专题三,RDMA SGL机制。

对通信技术感兴趣的朋友欢迎关注公众:通信行业搬砖工


01、前言
在使用RDMA操作之前,我们需要了解一些RDMA API中的一些需要的值。其中在ibv_send_wr我们需要一个sg_list的数组,sg_list是用来存放ibv_sge元素,那么什么是SGL以及什么是sge呢?对于一个使用RDMA进行开发的程序员来说,我们需要了解这一系列细节。
//结构体ibv_send_wr描述struct ibv_send_wr {uint64_t wr_id;struct ibv_send_wr *next;struct ibv_sge *sg_list;int num_sge;enum ibv_wr_opcode opcode;unsigned int send_flags;/* When opcode is *_WITH_IMM: Immediate data in network byte order.* When opcode is *_INV: Stores the rkey to invalidate*/union {__be32 imm_data;uint32_t invalidate_rkey;};union {struct {uint64_t remote_addr;uint32_t rkey;} rdma;struct {uint64_t remote_addr;uint64_t compare_add;uint64_t swap;uint32_t rkey;} atomic;struct {struct ibv_ah *ah;uint32_t remote_qpn;uint32_t remote_qkey;} ud;} wr;union {struct {uint32_t remote_srqn;} xrc;} qp_type;union {struct {struct ibv_mw *mw;uint32_t rkey;struct ibv_mw_bind_info bind_info;} bind_mw;struct {void *hdr;uint16_t hdr_sz;uint16_t mss;} tso;};};
02、SEG介绍
在NVMe over PCIe中,I/O命令支持SGL(Scatter Gather List 分散聚合表)和PRP(Physical Region Page 物理(内存)区域页), 而管理命令只支持PRP;而在NVMe over Fabrics中,无论是管理命令还是I/O命令都只支持SGL。

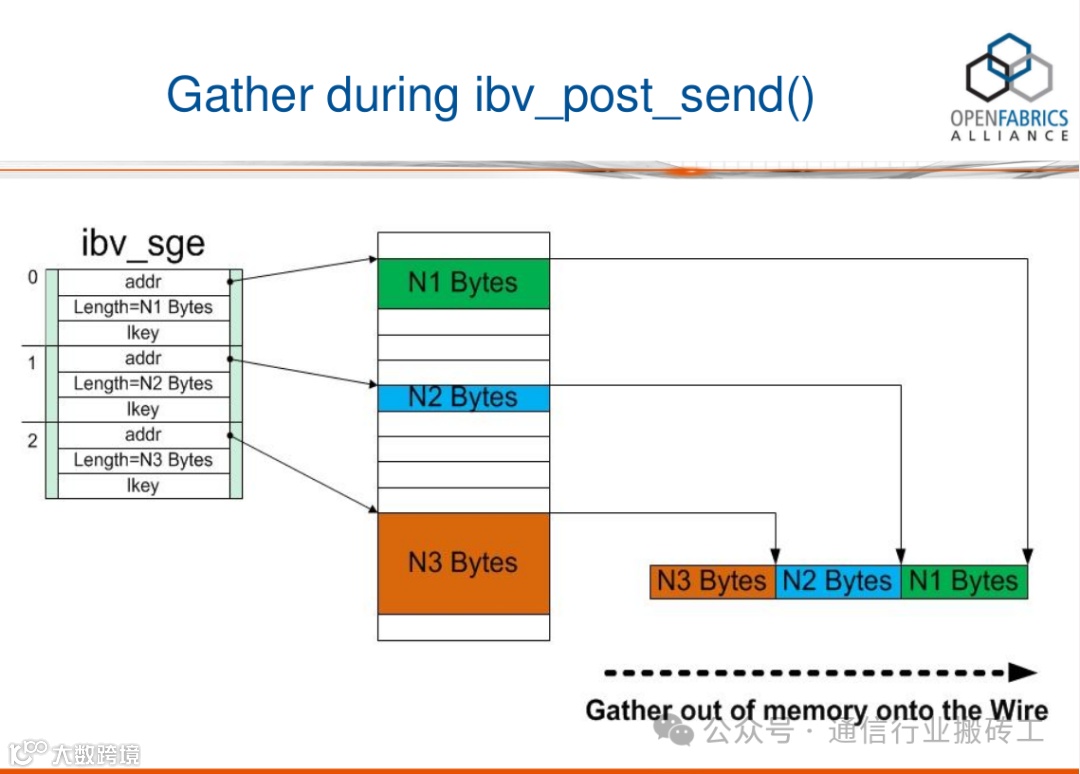
RDMA编程中,SGL(Scatter/Gather List)是最基本的数据组织形式。SGL是一个数组,该数组中的元素被称之为SGE(Scatter/Gather Element),每一个SGE就是一个Data Segment(数据段)。RDMA支持Scatter/Gather操作,具体来讲就是RDMA可以支持一个连续的Buffer空间,进行Scatter分散到多个目的主机的不连续的Buffer空间。Gather指的就是多个不连续的Buffer空间,可以Gather到目的主机的一段连续的Buffer空间。
下面我们就来看一下ibv_sge的定义:
struct ibv_sge {uint64_t addr;uint32_t length;uint32_t lkey;};
1、addr: 数据段所在的虚拟内存的起始地址 (Virtual Address of the Data Segment (i.e. Buffer))
2、length: 数据段长度(Length of the Data Segment)
3、lkey: 该数据段对应的L_Key (Key of the local Memory Region)
03、ivc_post_send接口介绍
ibv_post_send() - post a list of work requests (WRs) to a send queue 将一个WR列表放置到发送队列中 ibv_post_recv() - post a list of work requests (WRs) to a receive queue 将一个WR列表放置到接收队列中
下面以ibv_post_send()为例,说明SGL是如何被放置到RDMA硬件的线缆(Wire)上的。
ibv_post_send()的函数原型
#include <infiniband/verbs.h>
int ibv_post_send(struct ibv_qp *qp,
struct ibv_send_wr *wr,
struct ibv_send_wr **bad_wr);
ibv_post_send()将以send_wr开头的工作请求(WR)的列表发布到Queue Pair的Send Queue。它会在第一次失败时停止处理此列表中的WR(可以在发布请求时立即检测到),并通过bad_wr返回此失败的WR。
参数wr是一个ibv_send_wr结构,如中所定义。
struct ibv_send_wr {uint64_t wr_id; /* User defined WR ID */struct ibv_send_wr *next; /* Pointer to next WR in list, NULL if last WR */struct ibv_sge *sg_list; /* Pointer to the s/g array */int num_sge; /* Size of the s/g array */enum ibv_wr_opcode opcode; /* Operation type */int send_flags; /* Flags of the WR properties */uint32_t imm_data; /* Immediate data (in network byte order) */union {struct {uint64_t remote_addr; /* Start address of remote memory buffer */uint32_t rkey; /* Key of the remote Memory Region */} rdma;struct {uint64_t remote_addr; /* Start address of remote memory buffer */uint64_t compare_add; /* Compare operand */uint64_t swap; /* Swap operand */uint32_t rkey; /* Key of the remote Memory Region */} atomic;struct {struct ibv_ah *ah; /* Address handle (AH) for the remote node address */uint32_t remote_qpn; /* QP number of the destination QP */uint32_t remote_qkey; /* Q_Key number of the destination QP */} ud;} wr;};
在调用ibv_post_send()之前,必须填充好数据结构wr。wr是一个链表,每一个结点包含了一个sg_list(i.e. SGL: 由一个或多个SGE构成的数组), sg_list的长度为num_sge。
04、RDMA提交WR流程介绍
下面图解一下SGL和WR链表的对应关系,并说明一个SGL (struct ibv_sge *sg_list)里包含的多个数据段是如何被RDMA硬件聚合成一个连续的数据段的。



附录 OFED Verbs
随着硬件技术和深度神经网络的发展,目前形成了以“CPU+GPU”

作者简介
作者围城,云计算行业从业人员,蚂蚁集团研发专家,
研究方向:Kubernetes云原生 & 计算引擎
知乎主页:https://www.zhihu.com/people/mastertTJ
文章链接:https://zhuanlan.zhihu.com/p/55142568
github:https://github.com/Tjcug
编辑:通信行业搬砖工
更多互联网技术与咨询分享,欢迎关注我们的公众号

欢迎扫码关注公众号

(正文完)
支付宝搜索:工号842549480
转载与投稿
文章转载需注明:文章来源围城,并且附上链接
文章错误之处,欢迎指导斧正,各位大拿留言交流,探讨技术。

| 温馨提示 |
人到中年
年龄成为悬在头顶的达摩克利斯之剑!
学习VPP软件架构压压惊
欢迎分享、收藏、点赞、转发、留言交流。

点个在看你最好看