

张通社 zhangtongshe.com

沐曦股份登陆科创板。
出品 | 张通社
首图 | 网络
12月17日,张通社团队获悉,沐曦集成电路(上海)股份有限公司(简称:沐曦股份,股票代码:688802)在上海证券交易所科创板上市。这是继摩尔线程12月5日登陆科创板后,国产GPU行业迎来的第二位重量级选手。
在国产芯片以“爆发式涨幅”撬动市场情绪的背景下,沐曦于2025年12月上旬完成网上申购与网下配售工作,成为资本与产业双向关注的热点对象。
招股书显示,沐曦发行价104.66 元/ 股,共发行4010万股,募资约41.97亿元。截至发稿前,沐曦股价达到813元/股,市值破3200亿元。

沐曦成立于2020年,总部在上海张江,并在北京、南京、成都、杭州、深圳、武汉、长沙等地设有研发中心或分支。核心成员平均拥有近20年高性能 GPU 产品端到端研发经验,曾主导过十多款世界主流高性能 GPU 产品研发及量产,包括 GPU 架构定义、GPU IP 设计、GPU SoC 设计及 GPU 系统解决方案的量产交付全流程。
公司定位为“全栈 GPU 芯片及系统解决方案提供商”,覆盖GPU架构设计、IP、SoC设计、软件栈与系统级交付,目标市场包括 AI 训练与推理、云计算、数据中心、自动驾驶、图形渲染与数字孪生等。公司披露其核心团队成员具有多年高性能 GPU 产品端到端研发与量产经验(5nm/7nm 等工艺流片与量产经验),并宣称已形成一定的软件与生态配套能力。
从沐曦披露的产品节奏与技术路线来看,自成立之初,沐曦就强调“全栈”策略:以“通用 GPU 架构”为核心,逐步扩展到 AI 训练、推理与数据中心级计算,形成一条相对清晰的技术演进主线。现已推出三大系列产品:
1)曦思®N系列:用于智算推理,面向云端应用的智算推理产品,采用高带宽内存,提供强大的算力和领先的视频编解码能力,可广泛应用于智慧城市、公有云计算、智能视频处理、云游戏等场景。
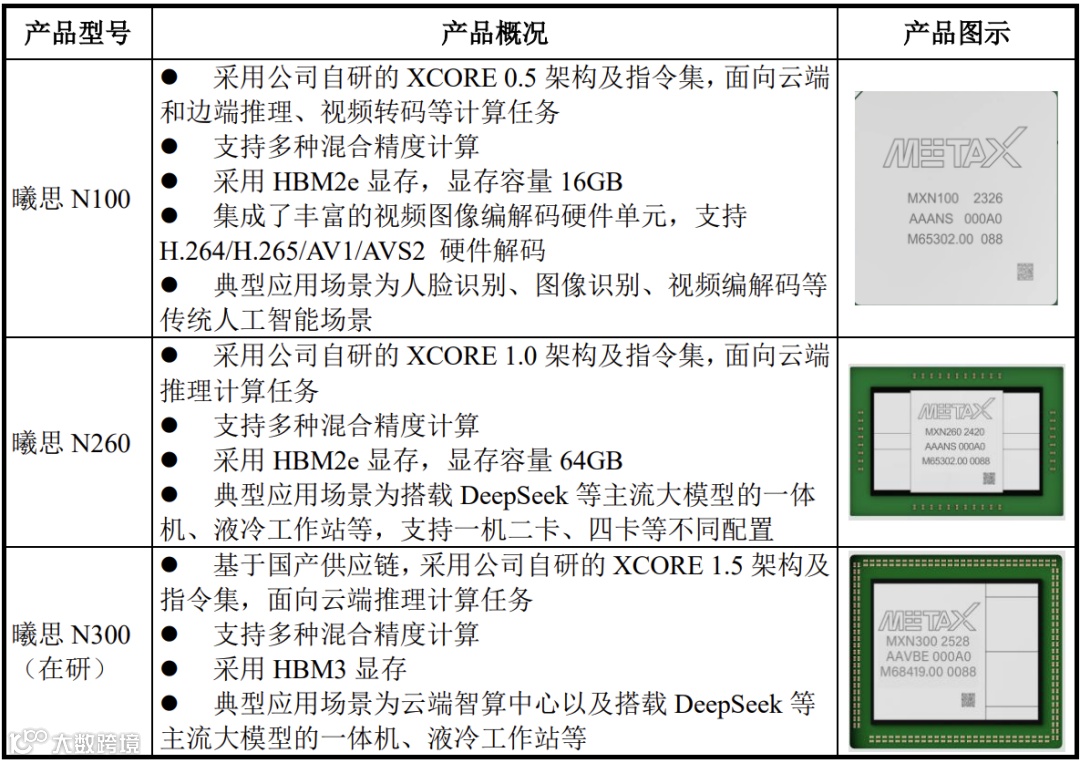
其中曦思N100产品是沐曦2022年推出的首款产品,是面向云端和边端多种传统AI应用场景的智算推理GPU,提供强大的推理算力和视频编解码能力。
曦思N系列的后续产品如曦思N260、曦思N300(在研)均主要面向生成式人工智能下的云端人工智能推理场景,拥有强大的多精度混合算力,配以大容量显存和新一代高速 I/O 接口,支持主流深度学习开发框架,可为内容生成式应用和大语言模型等智能应用提供端到端的加速服务。
2)曦云®C系列:用于训推一体和通用计算,针对云端计算场景,为人工智能训练和推理、通用计算提供算力底座,具备高性能、高自主可控、高扩展性。

曦云C系列产品具有强大的多精度混合算力、高带宽和大容量存储,结合其自研的MetaXLink高速互连技术,能够满足大规模计算集群扩展需求、支持千亿参数以上的 AI 大模型训练,可以大幅增加集群算力、缩短大模型计算时间。


2023年,沐曦推出了首款训推一体GPU芯片曦云C500,并在此基础上陆续推出了曦云C550、曦云C588;该系列基于国产供应链的产品曦云C600已回片并点亮。
3)曦彩®G系列:适用于图形渲染。产品涵盖了计算(包括训练、推理、通用计算)和渲染的全场景,沐曦采用自研的 XCORE 2.0 架构及指令集,内置性能强大的 GPU IP和硬件单元,具备卓越的图形处理能力,可广泛应用于云渲染、游戏、数字孪生、影视动画制作、专业制图等场景。
沐曦曦彩G系列采用了自研的自定义图像增强指令集,包含大量几何引擎、光栅化单元、像素处理单元、纹理单元和光线追踪单元等,支持Vulkan、DirectX、OpenGL 等图形库和 Unreal、Unity 等渲染引擎。
同时,沐曦基于“自主创新与开放兼容”双轨并行策略,为全系列GPU芯片构建了统一的运算平台及基础系统软件——MXMACA软件栈。
MXMACA软件栈基于沐曦自研指令集以及GPU并行计算引擎,集成了主流算法框架、运算库、通信库、操作系统、编程语言、调试和运维管理工具等,为GPU产品提供了一套统一、完整且高效的全栈式软件工具链,涵盖应用开发、功能调试和性能调优等核心环节。
MXMACA软件栈按照抽象层次由高到低,可分为四个层级:
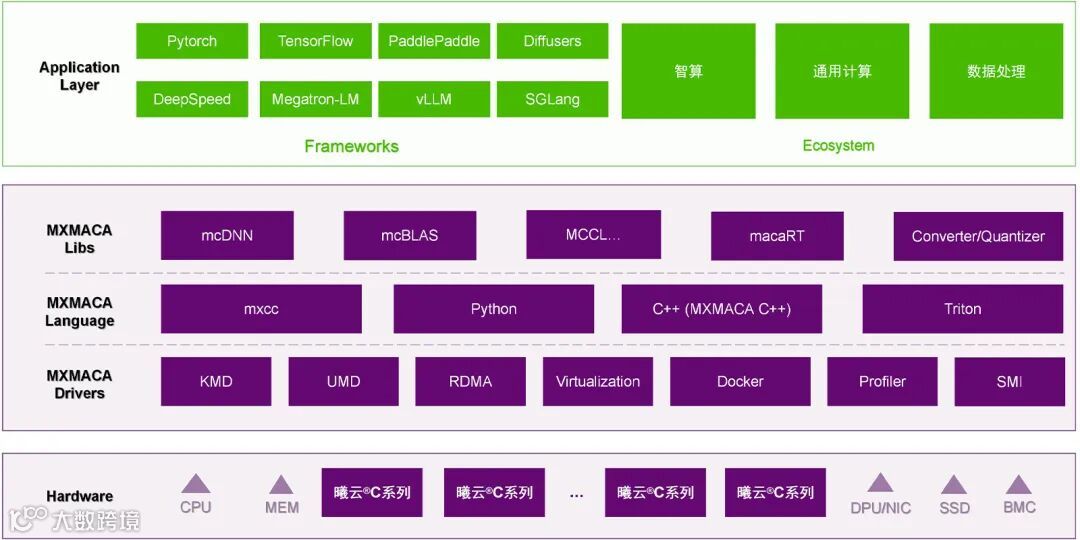
1)算法应用层,包括各类 AI 框架、AI 网络模型、AI应用等;
2)数学库及通信库层,包括用于支持应用层的自研软件库和适配、迁移到 MXMACA 平台的第三方软件库等;
3)编程语言层,包括底层编程语言和高级编程语言支持,以及相关编译器和语言转换工具;
4)软件驱动层,包括用于支持内核模式驱动、内存访问、虚拟化和容器、性能分析、代码调试等功能的各种驱动程序和工具。
沐曦坚持推动MXMACA软件栈开源共享,不断打造国产版GPU开放编程接口标准,推动解决跨GPU平台的应用兼容难题。
2020年
• 9月 沐曦集成电路(上海)股份有限公司注册成立。
• 10月 天使轮融资,由和利资本、泰达科投联合领投。
2021年
• 1月 Pre-A轮融资,由红杉中国、真格基金联合领投。
• 2月 re-A+轮融资,由经纬中国、光速中国联合领投。
• 6月 轮融资,由国调基金、中网投联合领投。
2022年
• 1月 曦思N100(智算推理GPU)交付流片。
• 7月 Pre-B轮融资,由混沌投资、央视融媒体产业投资基金联合领投。
• 8月 曦思N100回片并完成测试。
• 12月 曦云C500(通用计算GPU)交付流片。
2023年
• 6月 曦云C500回片仅5小时完成芯片功能测试。
• 7月 B轮融资,由浦东创投、广发信德联合领投。
• 12月 曦云C500量产出货;上海首个千卡算力集群落地;中国香港首个千卡算力集群落地。
2024年
• 4月 实现国内首家稳定运行的光互连算力集群。
• 6月 完成某研究院 128B参数大模型千卡集群全量训练。
• 8月 首个三千卡OAM算力集群落地北京。
• 10月 基于国产先进工艺的新一代通用GPU曦云C600流片。
• 12月 完成C轮融资,由中信金石、中金资本联合领投;正式完成股份制改革。
2025年
• 6月 科创板IPO成功获得上交所受理。
• 7月 基于国产先进工艺的新一代高性能通用GPU曦云C600成功发布。
• 10月 科创板IPO成功通过上交所审核。
• 12月 公司科创板上市(IPO)。
沐曦股份核心创始团队具有显著的 “AMD 背景”,几乎整个核心研发体系和管理层都来自该国际 GPU 巨头,在全球 GPU 设计与工程化方面具有深厚经验。
沐曦集成电路(上海)股份有限公司核心人员由总经理陈维良、首席技术官彭莉、首席技术官杨建等人构成。
公司创始人兼 CEO 陈维良在 GPU 领域具有超过二十年的深耕经验。,他1995年进入电子科技大学微电子专业,2002年获得清华大学微电子学硕士学位。
陈维良担任AMD上海研发中心的高级总监与全球 GPU 设计负责人,主导并完成15款高性能GPU产品的流片与量产,对 GPU 架构、芯片设计、系统级集成等环节有深入实践经验。2020年9月,陈维良创立沐曦集成电路。
此前,陈维良曾担任泰鼎多媒体的高级工程师、远弘科技的GPU设计经理、亚鼎视频的GPU设计经理。在沐曦招股书中披露,陈维良通过直接持股及控股平台合计控制沐曦股份约 22.9% 股权。
沐曦股份首席技术官彭莉,加入沐曦之前,在 AMD 拥有超过十年的工作经历,专注于 GPU 或相关高速计算架构研发。在 AMD 任职期间,她曾获得“企业院士”等内部技术荣誉称号,反映其在架构设计、性能优化及复杂系统工程中的资深技术实力。
沐曦股份首席技术官杨建,加入沐曦之前,有11年AMD工作履历,长期参与高性能 GPU 和相关系统的研发工作,也曾短暂工作于华为和海思科技。

【免责声明】本文所涉及内容仅为信息分享和事件讨论,不构成投资建议。