
为什么短视频平台“总能刷到你喜欢的内容”?
为什么搜索引擎能理解你“并不精确”的问题?
为什么AI能判断两段文字、两张图片、两个人“像不像”?
相似度计算。
在大数据和人工智能时代,相似度是一项基础且关键的能力。搜索、推荐、风控、舆情分析,以及AIGC、RAG、智能问答系统等,背后都依赖“相似度算法”。
本文将系统解析:
- 相似度计算的本质
- 常见方法与核心算法
- Python中的实用工具包
- 现实应用场景
- 为何“未来一切系统都是相似度系统”
一、什么是相似度计算?为何如此重要?
1. 相似度的核心:衡量“有多像”
两个对象“有多像”?
对象可以是:
- 词语(如“苹果”与“水果”)
- 文本(新闻、评论、合同)
- 图像(人脸识别)
- 用户画像(兴趣匹配)
- 商品(推荐依据)
- 代码(抄袭检测)
相似度通常以数值表示:
- 0:完全不相似
- 1:高度相似或相同
2. 为何现代系统依赖相似度?
现实问题极少“完全匹配”。例如:
- 用户搜索:“成都下雨吗”
- 网页标题:“成都市未来三天天气预报”
仅靠关键词匹配难以识别关联。相似度赋予机器“模糊理解”能力,提升系统智能化水平。
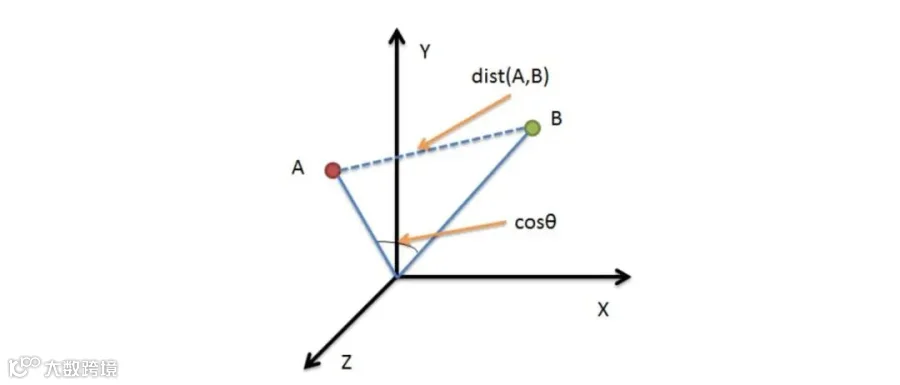
二、相似度的数学基础:距离与角度
1. 距离越近,越相似
- 欧氏距离
- 曼哈顿距离
- 编辑距离
适用于数值型数据、字符串比较。
2. 方向一致,越相似
- 余弦相似度
- 向量夹角
广泛用于文本、语义向量(Embedding)等高维数据。
三、常用相似度算法详解
1. 字符串相似度(适合入门)
1.1 编辑距离(Levenshtein Distance)
定义:将字符串A转换为B所需的最少操作(增、删、改)次数。
示例:kitten → sitting,距离为3。
特点:可识别拼写错误,适用于短文本。
应用:搜索纠错、输入校验、模糊匹配。
1.2 Jaccard 相似度
公式:相似度 = 交集 / 并集
示例:集合A={AI, 大模型, 推荐},B={AI, 搜索},Jaccard=1/4=0.25。
特点:简单直观,适用于标签、关键词集合匹配。
2. 文本相似度(互联网主流)
2.1 TF-IDF + 余弦相似度
原理:通过词频构建文本向量,用余弦值衡量相似性。
优点:可解释性强,实现简单,适合中小规模场景。
缺点:无法理解语义,“苹果”与“水果”被视为无关词汇。
2.2 BM25
TF-IDF的优化版本,考虑文档长度与词频饱和度。
应用:Elasticsearch、Lucene等搜索引擎默认算法。
3. 向量相似度(AI时代核心)
3.1 余弦相似度(Cosine Similarity)
公式:cos(θ) = A·B / (|A| × |B|)
重要性:文本、图像、音频、代码均可转化为向量(Embedding),成为RAG、推荐系统、语义搜索的基础。
3.2 欧氏距离与曼哈顿距离
- 欧氏距离:直线距离
- 曼哈顿距离:网格路径距离
用途:聚类分析、特征空间建模。
4. 语义相似度(大模型驱动)
4.1 Sentence Embedding
利用BERT、Sentence-BERT等模型将句子转为向量。
示例:“我想买手机”与“有没有性价比高的智能机?”向量接近。
优势:理解语义、支持多语言、抗同义词干扰。
4.2 Cross Encoder
同时输入两段文本,输出精细相似度评分。
特点:精度高,计算开销大,常用于候选集重排序。
四、Python常用相似度工具包
1. 基础工具
difflib(内置)
- 字符串相似度计算
- 轻量、无需安装
2. NLP工具
scikit-learn
- 支持TF-IDF、余弦相似度、聚类
- 适合教学与原型开发
gensim
- 提供Word2Vec、Doc2Vec、LDA
- 适用于文本向量化任务
3. 深度学习与语义处理
sentence-transformers
- 一键生成句向量
- 支持中文与多种预训练模型
- RAG项目首选工具
transformers(Hugging Face)
- 集成BERT、RoBERTa等主流模型
- 支持自定义微调
4. 向量数据库(大规模检索必备)
面对百万级以上数据,需高效向量检索:
- FAISS
- Milvus
- Weaviate
- PGVector
- MatrixOne
用于向量存储与相似度搜索,支撑高并发实时查询。
五、相似度算法的十大应用场景
5.1 搜索引擎
- 关键词与语义匹配
- 意图识别
5.2 推荐系统(核心)
- 用户兴趣相似度
- 内容协同过滤
5.3 AIGC & RAG
- 文档切片检索
- Prompt召回
- 知识增强问答
5.4 去重与反作弊
- 内容抄袭检测
- 广告水军识别
5.5 智能客服
- 相似问题匹配
- FAQ自动回复
5.6 舆情分析
- 话题聚类
- 事件追踪
5.7 风控与反欺诈
- 异常行为模式识别
- 用户行为相似性分析
5.8 人脸与图像识别
- 人脸向量比对
- 图像内容检索
5.9 代码相似度
- 代码抄袭检测
- 智能代码推荐
5.10 医疗与法律
- 病例相似性分析
- 判例智能检索
六、如何选择合适的相似度算法?
没有最好的算法,只有最合适的算法
| 场景 | 推荐算法 |
| 拼写纠错 | 编辑距离 |
| 标签匹配 | Jaccard |
| 文章相似 | TF-IDF |
| 语义理解 | Sentence Embedding |
| 大规模检索 | 向量数据库 |
| 高精度比对 | Cross Encoder |
七、未来趋势:相似度无处不在
一切皆向量,一切皆相似度
- 搜索从“找词”转向“懂意”
- 推荐由规则驱动变为语义驱动
- 系统逐步具备“理解用户”的能力
在AI Agent、RAG及大模型应用中,相似度已成为系统智能的底层支撑。
八、普通人为什么需要了解相似度?
- 每日接触的推荐内容非随机生成
- 信息流、搜索结果均受相似度机制影响
- 所见世界正被相似度逻辑塑造
理解相似度,就是理解当代信息社会的运行逻辑。