
点击下方名片,获取你的下一个灵感实例。
在自动驾驶的决策系统中,若大型视觉语言模型(LVLM)将"停止标识"错误描述为"限速标志";在医疗影像分析中,把"良性结节"误判为"恶性肿瘤"——这些看似微小的"幻觉",可能引发致命后果。当前基于不确定性的幻觉检测方法常陷入困境:高不确定性样本未必是幻觉,低不确定性样本反而可能藏有错误。来自ACM MM 2025的最新研究《Visual Perception Uncertainty Learning for Hallucination Detection in Large Vision-Language Models》提出的VisPUL框架,通过视觉感知与不确定性学习的深度融合,为这一难题提供了突破性解决方案。
论文信息
题目:Visual Perception Uncertainty Learning for Hallucination Detection in Large Vision-Language Models
视觉感知不确定性学习用于大视觉语言模型中的幻觉检测
作者:Runze Zhao, Fuqing Zhu, Jizhong Han, Songlin Hu
幻觉检测的核心困境:不确定性≠幻觉
LVLM的幻觉现象如同隐形的"认知陷阱"。研究者通过实验发现,约30%的高不确定性样本实际是正确输出,而15%的低不确定性样本却存在严重幻觉。如图1所示,当模型描述蛋糕装饰时,虽然对"芒果/橙子/草莓"的口味判断存在高不确定性,但"生奶油和柑橘类水果装饰"的核心描述完全正确——仅依赖文本不确定性的检测方法会在此类样本上失效。

现有检测方法分为两类:依赖外部工具的方法受限于工具能力边界,而纯文本不确定性方法又难以摆脱上述困境。VisPUL的创新在于:让检测模型同时"看见"图像和"理解"文本,通过跨模态一致性判断打破单一信息源的局限。
VisPUL框架:三模块构建多模态检测闭环
VisPUL的整体架构如图2所示,通过视觉语义提取、文本-视觉差异表示、不确定性学习三个核心模块,实现从"单模态猜测"到"多模态验证"的范式转变。

模块1:视觉语义提取——给每个词找到视觉锚点
模型首先从LVLM的输出中提取每个标记的概率分布,筛选出概率最高的前k个候选词(如"curl""spread""stretch")。通过注意力机制计算这些词与图像特征的关联强度,最终聚合形成与视觉高度相关的语义表示。例如在描述猫的姿势时,"curl"(蜷缩)与图像中猫伸展的姿态关联度低,而"stretch"(伸展)则获得更高注意力权重,为后续差异判断奠定基础。
模块2:文本-视觉差异表示——量化跨模态一致性
将文本响应与视觉语义转换到同一向量空间后,通过简单的向量减法计算差异值。关键创新在于:用不确定性熵值对差异进行加权——高不确定性的词(如颜色描述中的"红/橙/粉")的差异值会被赋予更高权重,使模型更关注那些"模棱两可又可能出错"的表述。
模块3:不确定性学习——上下文感知的最终判断
采用Transformer编码器捕捉标记间的上下文关系,通过池化和MLP实现二元分类。这种设计能有效识别"整体一致但局部矛盾"的复杂幻觉,例如"天空中有一轮圆月,星星格外明亮"这类时间逻辑冲突的描述。
实验验证:在两大数据集上全面领先
研究者在M-HalDetect(开放式描述任务)和POPE(对象幻觉检测)数据集上进行了严格验证,结果显示VisPUL在不同LVLM基座上均表现卓越:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|

消融实验(表2、表3)进一步证明各模块的必要性:去除视觉语义提取会导致1.5%-2.5%的性能下降,验证了视觉信息的核心价值;去除熵加权机制后,LLaVA-1.5模型性能下降1.9%,说明不确定性与跨模态差异的互补性。

超参数分析:简单设置实现最优性能
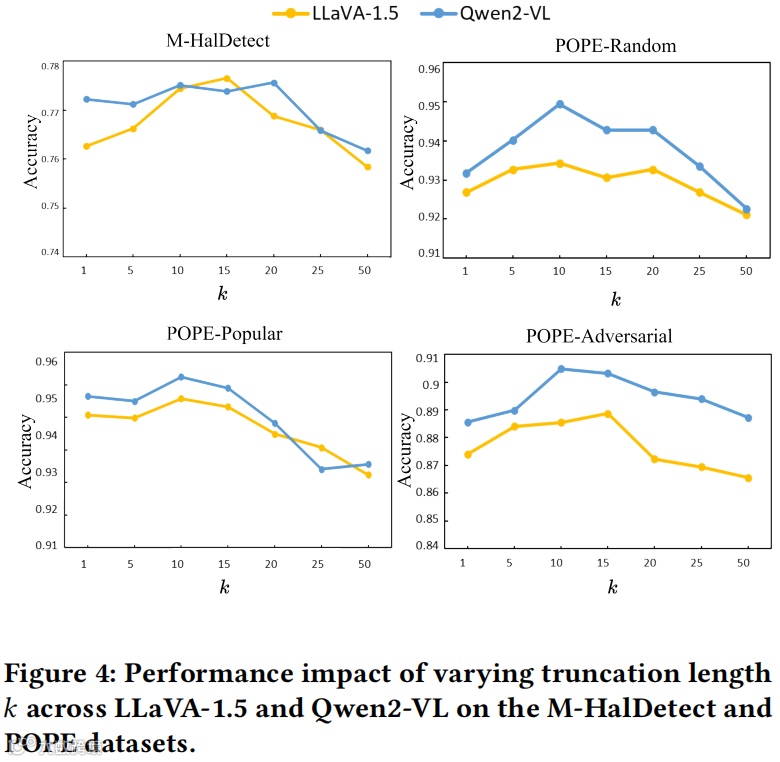
研究发现超参数k(候选词数量)和N(编码器深度)对性能影响显著:
-
当k=10时模型性能稳定:过小则信息不足,过大则引入噪声(图4) -
编码器深度N=1时已达最优:更深层会导致过拟合(图5、6)

定性案例(图3)直观展示了VisPUL的优势:面对颜色多样的鸟类图像,传统方法因高不确定性误判,而VisPUL通过视觉-文本一致性判断得出正确结论。

未来展望:从白盒到黑盒的跨越
VisPUL目前依赖开源LVLM的内部信息,未来可通过"代理模型"近似黑盒模型的输出分布,降低对模型可访问性的依赖。同时探索无监督学习方案,减少对标注数据的依赖,推动幻觉检测技术在实际场景中的规模化应用。
这一研究不仅为LVLM的可靠性提升提供了新范式,更揭示了一个核心原则:在多模态智能中,只有让模型同时"看见"和"理解",才能真正接近人类级别的认知可靠性。
