
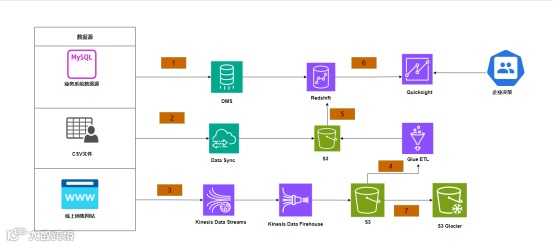
为了支持多种数据来源,包括MySQL数据库、CSV文件和Web日志。数据首先通过不同的服务进行导入和存储:
-
DMS(Database Migration Service):用于将MySQL数据库中的数据迁移到Amazon Redshift,确保数据仓库中的数据始终与源数据库同步,便于后续处理和分析 -
Data Sync:负责将本地或其他数据源(如CSV文件)的数据同步到S3存储桶中,便于后续处理和分析。 Kinesis Data Streams:用于实时处理和传输从Web日志等流数据源捕获的数据,适用于获取实时数据参与数据分析。
数据处理与分析:
在数据成功导入和存储后,架构中包含多个服务来处理和分析数据:
-
Kinesis Data Firehose:将通过Kinesis Data Streams收集的实时数据传输并存储到S3中,以备后续分析和持久化。 -
Glue ETL:使用AWS Glue进行数据的提取、转换和加载(ETL)操作,将存储在S3中的原始数据转换为分析所需的格式,并将处理后的数据存储在Redshift数据仓库中。 QuickSight:通过与Redshift集成,QuickSight提供快速、易用的商业智能(BI)服务,实现对数据进行可视化分析和报表生成。
数据备份与归档:
为确保数据的长期存储和归档,架构中使用了以下组件:
-
S3 Glacier:将存储在S3中的数据备份到S3 Glacier进行长期归档存储,适用于不常访问但需要长期保存的数据。通过设置生命周期策略,数据在一段时间后自动转移到Glacier中以降低存储成本。

操作:使用DMS从MySQL数据库迁移数据到Amazon Redshift,通过Glue ETL从S3中提取、转换和加载数据,并通过QuickSight进行数据分析和可视化。
-
经验:这种跨服务的数据集成使得从数据获取到分析的流程高度自动化,减少了手动干预,提高了数据处理效率。Glue ETL与Redshift结合使用有效地处理了大数据集的分析需求。
-
操作:利用Kinesis Data Streams实时接收和处理Web日志,并通过Kinesis Data Firehose将处理后的数据存储到S3进行进一步分析或归档到S3 Glacier。 经验:Kinesis的数据流处理架构能够应对高并发的实时数据输入,保证数据在高负载下的稳定传输。结合S3 Glacier进行长时间数据存储,确保数据在低成本环境中的安全存档。
-
操作:通过Data Sync自动将本地或外部数据同步到S3,并配置S3生命周期规则自动将数据备份到S3 Glacier。 -
经验:自动化的数据同步和备份机制确保了数据的一致性和持久性,特别是在多源数据集成的场景中。生命周期规则的使用进一步优化了存储成本管理。

1.数据传输和延迟管理:
-
操作:在架构设计中,使用DMS从本地数据库同步到AWS Redshift,但未充分考虑网络延迟和带宽限制,导致数据传输速度慢,数据延迟显著增加。 -
经验:在进行大规模数据迁移时,需要充分评估网络条件,可能需要考虑在低网络负载时安排数据传输或使用压缩技术以减少数据量。此外,还可以考虑使用增量同步机制减少初始数据迁移后的延迟。
2.服务配合与资源管理:
操作:在配置Glue ETL任务和Redshift时,未充分考虑资源的优化配置,导致ETL任务在数据高峰期时与Redshift争夺资源,影响系统整体性能。
-
经验:在使用多个AWS服务时,需要详细规划各个服务的资源需求和相互影响,避免资源争夺。可以考虑在非高峰时段运行ETL任务,或增加Redshift的计算节点以确保高峰期间的性能。
3.日志和监控策略的完整性:
-
操作:在配置Kinesis Data Streams时,未设置完善的日志和监控策略,导致数据丢失时未能及时发现,造成数据丢失。 经验:对于涉及实时数据流处理的架构,必须配置全面的日志记录和监控警报机制,以确保在发生问题时能够及时响应。使用CloudWatch和CloudTrail记录数据流中的每一步操作,以便在出现故障时快速定位问题。
