



本期技术分享人:
平台研发中心 黄映挺
大家有相关问题可发送至分享人邮箱
交流探讨
huangyingting@longshine.com
VsJob来源于mapreduce编程模型的启发,是一个简单的轻量级的分布式编程模型,它被设计用来分布式处理那些可以进行简单任务切片,并且不需要归并操作的作业。例如:在不同数据源之间进行数据的分布式导入导出,大量邮件的群发等应用。在我们的实际业务里,基于VsJob实现了一个分布式数据抽取及索引构建工具,用来从各种数据源(关系型数据库、ODS、文件系统等)里抽取数据,接着针对每份数据(如数据库里的每条记录,或每个Batch的数据)进行独立的索引构建工作(包括分词、词义扩展、索引构建、索引写入等操作)。
VsJob编程模型将一个作业(job)抽象为作业分片、任务(task)处理、作业执行结果处理三个过程,其中“作业”指业务需要完成的完整的计算逻辑,作业需要根据分片逻辑进行切分,针对每一个作业分片的计算逻辑就是一个“任务”。程序员只需要关心以上接口的逻辑实现,不用关心底层复杂的分布式处理过程,VsJob底层框架负责节点通信、数据传输、资源分配、任务调度、容错等处理,从而简化此类作业的的开发难度。


个人观察,一项热门技术到了成熟阶段,除了自身的基础技术在细节方面更加完善外,往往会从多个方向进行延伸发展。分布式计算也不例外,作为分布式计算平台的代表,Hadoop已经趋向完善,而围绕着分布式计算也出现了各类不同的发展方向:
 细节方面的深耕及改进
细节方面的深耕及改进
典型的如Spark、Tez等。这些平台相比Hadoop平台在细节上更完美,例如更灵活地支持Map、Reduce各个环节的任意组合,如Map-Map-Reduce序列,而不像Hadoop只支持呆板的Map-Reduce处理序列;支持内存存储中间计算结果(如Spark的RDD)等。
 高层次的抽象
高层次的抽象
如高层的HQL引擎Hive,Pig等
 底层支撑技术的演化
底层支撑技术的演化
如资源分配管理Yarn、Mesos等。虽然可能没有直接的关系,但确实是hadoop生态丰富以后,底层资源分配管理系统才得到充分的重视和应用,如Hadoop2直接研发Yarn来替代上一代封闭的资源管理系统。
 专业化的处理方向
专业化的处理方向
如面向流计算的Storm;面向实时查询和分析的Druid、Drill、Impala等;面向图计算的pregel、giraph等;面向内存的分布式关系型数据库的voltdb等;面向时间序列或检索需求的influxDB、ElasticSearch等。
 轻量级
轻量级
针对原有的基础功能做减法,通过牺牲部分特性使系统更轻便。这样的系统适用范围更窄,但在这些细分需求领域,系统能提供更轻量级的支撑产品。
轻量级是本文介绍的VsJob框架的方向,它本质上可以看做是一个MapReduce的简化版。轻量级的重要性还有其它示例可以说明:例如一个只需要发布一些WebService的非Web程序,没有必要依赖外部的Servlet引擎如Tomcat、Jetty等,一个轻量级的做法是引入Netty实现一个简单的WebService框架;如果只需要IOC(所谓的依赖注入)能力,没有必要依赖spring(当然spring本身是模块化的,可以选择只依赖所需的模块),可以采用guice等更单纯的框架。
同理为了支持一些简单的不需要归并操作的分布式计算逻辑,只需要Map而不需要Reduce的支持就可以满足需求,因此实现一个只支持Map的框架具有一定的现实意义。

VsJob可以看做是一个MapReduce的简化版本,删减了一些重要但在一些应用场景里却并非必要的特性,主要体现在以下两点:
去掉Reduce处理过程
MapReduce将Job的处理过程抽象为两个步骤: Map(数据拆分处理)和Reduce(数据归并计算)。其中Reduce是一个非常重要的步骤,正是得益于Reduce处理过程,才有可能用MapReduce模型表达很多较复杂的计算逻辑。而MapReduce框架为了简化上层应用的计算,为Reduce实现了各种底层的支持,包括排序(shuffle)、分区(partition)、数据传输等。
然而在现实需求中,也有一部分计算逻辑并不需要归并操作。一个典型的用例如数据抽取。通常我们在处理分布式抽取的时候,可以基于MapReduce框架,但往往只需要用到Map的功能。这里应用的一个代表是sqoop,一个用于在关系型数据库和hdfs等数据源之间进行数据的导入导出的分布式处理工具。因此在这类应用里,Reduce的支持是不必要的。
去掉本地化计算特性
MapReduce一个重要的特点是所谓的计算本地化,即尽量使计算资源(cpu、内存等)和数据资源分布在同一个物理节点(主机)上,从而避免大规模数据在不同节点间传输,减少了对宝贵的带宽资源的冲击。因此在Hadoop实现里MapReduce必须依赖于HDFS分布式文件系统,才能实现计算的本地化。
然而在现实需求中,不是所有的计算需求都能利用到本地计算的优势。例如数据的抽取,其本质就是要将数据在不同节点间进行传输,因此也就无所谓“本地计算”这个特点。
通过以上简化处理,VsJob约束了自己的适用范围:
 VsJob编程模型只能用来表达这类作业:可以进行简单任务切片,并且不需要归并操作的作业。例如:在不同数据源之间进行数据的分布式导入导出,大量邮件的群发等应用。
VsJob编程模型只能用来表达这类作业:可以进行简单任务切片,并且不需要归并操作的作业。例如:在不同数据源之间进行数据的分布式导入导出,大量邮件的群发等应用。
 自身不具备数据存储能力,所有数据处理过程都在内存里进行。
自身不具备数据存储能力,所有数据处理过程都在内存里进行。
通过限制本身的功能和适用范围,VsJob简化了模型和框架实现的复杂度,从而实现轻量的目标:
 开箱即用
开箱即用
不需要复杂的安装部署过程,不需要依赖HDFS 等重量级系统。只需要将业务作业程序作为插件发布到VsJob框架里,启动VsJob进程即完成一个节点的部署。
 简单的编程模型
简单的编程模型
业务开发人员只需要关心作业分片、任务(task)处理、作业执行结果处理等接口的处理逻辑,即完成一个分布式作业。

VsJob编程模型将一个作业(job)抽象为作业分片、任务(task)处理、作业执行结果处理三个过程,其中“作业”指业务需要完成的完整的计算逻辑,作业需要根据分片逻辑进行切分,针对每一个作业分片的计算逻辑就是一个“任务”。程序员只需要关心以上接口的逻辑实现,不用关心底层复杂的分布式处理过程,VsJob底层框架负责节点通信、数据传输、资源分配、任务调度、容错等处理,从而简化此类作业的的开发难度:
 作业(Job)分片
作业(Job)分片
作业是一个完整的业务计算单元,它首先必须是可拆分的。通常是根据作业的输入数据进行分片,例如对于“从MYSQL导出数据”应用,分片的逻辑就是利用Mysql的Limit语句,将一个表的数据分为多个子集(每个子集可以抽象为记录的开始位置、子集的记录数。可以想想分页语句的例子),每个子集就是一个作业分片。
 任务(Task)处理
任务(Task)处理
对应于每个作业分片的计算单元就是任务。因此一个作业的计算逻辑是多个任务的计算逻辑的集合。对于“从MYSQL导出数据”应用,一个任务就是根据自己所分配到的数据子集(记录的开始位置、记录总数),构造sql查询语句,从表里导出数据子集,写入目标数据源。
 作业结束后的处理逻辑
作业结束后的处理逻辑
vsjob会自动监测作业的执行结果。作业需要根据不同的执行结果,实现相应的处理逻辑:如简单地返回“处理失败”或“处理成功”给作业的调用者;也有可能是复杂的操作,如进行失败作业的回滚操作。
以简化过的全文检索应用的索引构建过程作为示例:从mysql数据库的表里抽取数据,并调用索引构建程序为每一条记录构建反向索引,伪代码如下:
1) 定义数据分片的存储对象(Model) 。(这里类似于web开发时常用的分页数据模型)
SqlInputSplit{ private String tableName;//表名 private long from;//分片数据集在表里的起始位置 private long size;//分片数据集的最大的记录数 private String id=null;//分片Id,由框架自动赋于唯一的值 } |
2) 作业分片逻辑
public List< SqlInputSplit > getSplits( int amountOfTasks) { //计算记录总数 amountOfRecords=Count amount of the table records //根据预设的任务总数和表的总记录数,将数据集进行切片 sqlInputSplit =Split dataset by amountOfRecords and amountOfTasks. return sqlInputSplit } |
3) 任务计算逻辑
public TaskExecutedResult execute(TaskContext taskContext){ // 从任务上下文里获取分片的作业切片数据 SqlInputSplit=taskContext.getInputSplit(). //根据切片数据,构造查询sql语句 Sql=makeQuerySql(). //获取实际的数据记录集 ResultSet=queryBySql; //构建反向索引 constructAndWriteRevertIndex //返回任务处理结果:成功、失败等。 return taskExecuteResult. } |
4) 作业结束后的处理逻辑
public void handle(JobResultInfo jobResultInfo, Map<String, Object> appParams) { //从jobResultInfo里获取作业执行结果:成功、失败等。 jobResult=getResult(jobResultInfo).
If(failed) {//如果失败,回滚抽取日志 Rollback job’s log. } else {//如果成功,标记本次job执行的时间,用于下次增量抽取 save executeTime of the current job instance.. } } |

基于以上介绍的vsjob编程模型,我们实现了一个框架进行支撑,主要包括节点通信、数据传输、资源分配、任务调度、容错等。
系统由控制节点(JobTracker)集群和任务节点(TaskProcessor)集群组成。控制节点负责作业的切片与任务的执行调度,作业的并行执行控制,并负责任务运行状态的监控、作业运行状态的监控、失败任务的监测与处理、超时任务的监测与处理、作业执行结果的处理、任务节点监控与故障转移处理等。任务节点负责接收任务执行请求并执行任务,汇报任务运行状态等。
控制节点和任务节点都是无状态的,允许动态扩容和缩容。控制节点负责接收作业的提交,一个作业只能同时被一个控制节点管理。
集群资源的协调、交互、共享通过Zookeeper进行管理,简化了系统的实现。
整个系统尽量保持轻量级,不需要任何第三方系统如Tomcat等。
技术架构见下图:
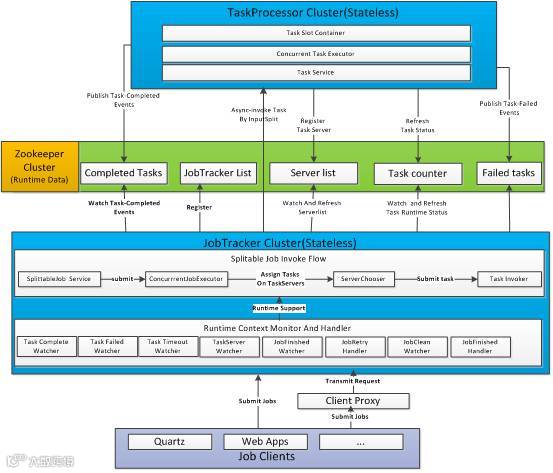
图1:技术架构
VsJob集群里存在两个角色:控制节点和任务节点。控制节点负责发起作业、进行任务调度、判定作业执行结果等,任务节点的作用是调用工作程序(Worker)执行所分配的作业分片,并将任务执行状态通知控制节点。见下图“架构示意图”。
由于控制节点和任务节点的职责差异很明显,因此在我们的实现里采用“主从架构”(其它实现也可以考虑点对点架构,VsJob编程模型本身是架构无关的)。这里“主节点”指控制节点,“从节点”指任务节点。一个集群里可以存在多个控制节点和多个任务节点:
 控制节点集群
控制节点集群
控制节点是状态无关的,支持负载均衡及动态扩容(缩容)。当前我们实现的版本里还没有实现控制节点的Fail-Over,并且作业运行状态是存储于本地内存里,因此一旦某个控制节点当机,则由其发起的所有作业都将丢失(但在其它控制节点发起的作业依然是正常的),使用者将不得不重新发起执行这些作业。后续可以进一步通过控制节点之间的“状态复制”(见图一里“控制节点”之间的虚线连接关系), 解决控制节点的“单点问题”,从而提高控制节点的可用性。
 任务节点集群
任务节点集群
任务节点是状态无关的,支持负载均衡及动态扩容(缩容)。当前我们实现的版本里任务是由每个控制节点独立分发、调度的,并没有利用全局的任务节点的负载信息,因此只实现了简单的负载均衡策略(基于任务id对任务节点取模的方式)。后续可以进一步利用全局的任务节点负载信息,实现更高级的均衡策略。

图2: 架构示意图
作业主要执行流程见下图:
1) 作业由控制节点发起执行,首先调用业务定义的“作业分片程序”,生成多个作业分片
2) 控制节点保存作业分片数据,根据可用的任务节点数量及业务指定的最大并行执行数,持续将作业分片发送给可用的任务节点执行
3) 任务节点调用业务定义的“任务处理程序”来执行作业分片任务
4) 在任务执行结束后,任务节点通过集群状态管理程序,通知控制节点该任务的处理结果状态
5) 控制节点根据已收集到的任务处理状态判断作业是否结束。

图3:主要执行流程
由于一个作业需要分成多个任务,并分配到多个多个任务节点进行处理。而在一个较大的集群环境下,系统需要能够较好地处理机器故障和任务处理异常。
 控制节点故障
控制节点故障
控制节点保存作业的元数据及运行时状态等数据,目前的实现是将这些数据存放在内存,并且控制节点没有备份节点,因此存在单点问题和不可恢复问题。解决方案见在“6.3节后续工作”章节。
 工作节点故障
工作节点故障
控制节点实时监测工作节点的运行状况(目前实现里通过zookeeper的消息通知机制),如果发现一个节点失去响应,则将该节点从工作列表中删除,新的任务将不再分配给该节点。如果控制节点发现新的任务节点加入(或重新加入),则将其加到工作列表,作为可用的任务节点。
 任务处理异常
任务处理异常
任务在运行过程中可能出现异常,系统通过“失败重试”机制,保证失败的任务尽可能地被执行成功,实现方式:支持为每个作业设置“最大失败重试次数”,只有超过这个最大值,任务才被最终认定为失败,否则将被判定为失败的任务分配到其它任务节点执行。
任务处理异常有多种原因,VsJob针对不同原因采用不同的处理规则:
1) 超时任务
一个任务可能由于各种原因,运行时间超过期望值,如系统挂起、计算资源不足、任务节点机器出现故障等,系统允许为每一个作业定义超时时间,当任务运行时间超过设置值,则认为该任务是失败的。
2) 任务节点机器故障
有两种处理方式:一、直接将该机器上运行的所有任务都判定为运行失败;二、暂时不做处理,后续控制节点会将这些任务判定为超时任务,即等同于超时任务进行处理。系统当前采用第二种方式。
3) 任务执行异常
由于业务逻辑等问题,任务执行过程中抛出异常。系统直接标注为失败任务。
4) 任务调用失败
一种可能的原因是由于该任务节点的任务服务暂时不可用。系统直接标注为失败任务。
除了业务程序外,VsJob集群中的通信及数据传输行为发生在控制节点、集群状态管理程序(现阶段的实现里采用Zookeeper)、任务节点:
 任务节点
任务节点
需要接收来自控制节点的分片数据,因此需要提供服务接口。由于作业分片的数据一般不是指任务要操作的数据本身,而是数据集的元数据,数据量一般较小,对通信及数据传输的性能要求不高。因此在我们的实现里,服务基于HTTP Restful,数据格式采用Json。
 任务节点的执行状态等信息通过集群状态管理程序通知控制节点。
任务节点的执行状态等信息通过集群状态管理程序通知控制节点。
由于采用 了Zookeer作为实现,因此通信及数据协议基于Zookeeper内部协议。
 控制节点需要接收外部的作业发起请求。因此需要提供服务接口。
控制节点需要接收外部的作业发起请求。因此需要提供服务接口。
由于接收的数据是作业元数据,数据量一般较小,对通信及数据传输的性能要求不高。因此在我们的实现里,服务基于HTTP Restful,数据格式采用Json。
在我们的实现里,为了减少大量节点运行状态数据(如正在运行的任务数等)的广播带来的性能冲击(主要是对Zookeeper的高并发写入与读取),暂时不获取每个节点的运行数据,控制节点无从知道任务节点集群里每个节点的负载信息。因此这里采用基于任务id对任务节点取模的方式,来决定将作业分片分配到哪个任务节点。
同时允许为每一个作业指定最大并发执行数量,即一个作业同时运行的任务数量,不超过最大值。例如可以在高峰期对一些耗资源作业,指定较小的并发数量,从而更精细地优化资源的使用。
当前实现版本里,任务节点为每一个作业分片分配一个线程作为工作程序(Worker),并通过线程池对线程进行管理。由于线程是重用的,可能带来的一个问题是jvm的垃圾回收会导致任务节点整体性能的波动。
缓解此类问题的方法可以考虑参考Hadoop的处理机制。在Hadoop里的工作线程管理机制是:为每一个独立的作业最少分配一个新的jvm进程,默认是为每一个作业分片新建一个jvm进程,通过允许jvm重用,使一个jvm程序可以运行同一个job下的多个作业分片。这种机制的好处之一是可以避免垃圾回收之类的问题,但对于短任务来说,创建jvm进程带来了一定的开销。
一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。比如数据库里的update操作。
在分布式环境下,当一个节点出现问题时,其它节点无法准确获知问题原因,因为有多种原因会导致节点失去响应:节点之间的网络暂时出现问题;节点主机当机;节点主机暂时挂起等。
基于以上原因,在分布式架构下,要支持任务失败或超时重试,或者任务节点的故障转移,VsJob无法保证同一个任务不被重复执行,甚至同一任务在同一时间有可能在不同的任务节点上同时运行(比如在发生”brain-split”的时候,一个任务节点被控制节点判定为不可用,而实际上任务节点依旧正常运行)。因此VsJob平台本身不解决重复执行带来的计算问题,而由业务程序自行处理。
实际上幂等问题不只存在于分布式系统,对于不同的应用场景,工业界有不同的解决方法。例如对于数据抽取这样的业务场景,写入端如果是索引库,那么索引的写入可以采用InsertOrUpdate模式。
在VsJob的实现里,提供了可调节参数,可以通过牺牲“容错”的特性,保证每个任务只被调用执行一次(不管任务是否执行成功)。即将请求的Job的重试次数(RetryTimes)的值设置为0(即不进行失败重试)。

我们用自主研发的“数据抽取及索引构建框架”作为VsJob的落地应用进行验证。“数据抽取及索引构建框架”支持多种数据源、支持可配置化任务定义等特性,原先只支持单进程多线程并行运行。经过重构、改造,基于VsJob实现了多进程多线程的分布式运行能力。
“数据抽取及索引构建框架”的技术架构参见下图:

图4:“数据抽取及索引构建框架”技术架构
集群测试涉及的因素比较复杂,包括业务程序性能、集群状态管理程序写入及读取性能、控制节点的并行控制性能、任务节点的并行控制性能等。我们暂时未开展全面的测试,目前只基于3台服务器做了基本的线性扩展的测试。测试表明,在少数节点(模拟2个控制节点和4个任务节点的集群)的集群规模里,VsJob具备线性扩展能力。

一个常见的问题是“为什么要重复发明轮子,既然已经有这么多开源工具和框架”。这里从横(类似的框架)纵(类似的业务功能)两个不同的角度,选择相似的主流的开源产品,进行简单比较,说明技术选型的关注点。
1) Hadoop
主流的分布式存储、计算平台,实现了MapReduce编程模型和底层支撑,经过多年的发展,不论是技术细节还是周边配套上,都已经非常完善。而VsJob只是MapReduce的一个功能子集,实现了Map部分。因此Hadoop可以完全覆盖VsJob的功能。如果你的应用环境中已经有Hadoop,那么优先选择Hadoop,毕竟VsJob目前的状态只是自产自销,在一些细节和配套上远不如Hadoop成熟。但如前面所述,Hadoop对于一些简单的分布式计算需求,过于重量级,因此如果你的应用需要一些简单的分布式计算能力,如数据抽取等功能,并且不希望部署笨重的Hadoop系统,那么VsJob也许是一个轻量级的选择。
事实上,既然VsJob只是Hadoop的一个子集,那么通过一些封装(如接口Adapter)机制,可以实现VsJob程序和Hadoop程序的通用性,即使业务程序可以无缝地部署、运行在两个平台上。
2) Flume
著名的分布式日志采集框架/平台。有大量现成可用的插件,几乎涵盖所有常用的数据源如Hadoop、ElasticSearch、Kafka、各类RDS、各类日志系统等。
与VsJob相比,Flume有两个局限性:
 Flume的应用场景侧重于数据的采集、流转,不是一个通用的分布式计算框架
Flume的应用场景侧重于数据的采集、流转,不是一个通用的分布式计算框架
 Flume不支持数据采集任务的动态管理功能。Flume本质上不是一个真正意义上的分布式系统:没有实现动态扩容(缩容);没有一个全局的控制器感知所有的Flume进程的执行结果。
Flume不支持数据采集任务的动态管理功能。Flume本质上不是一个真正意义上的分布式系统:没有实现动态扩容(缩容);没有一个全局的控制器感知所有的Flume进程的执行结果。
因此如果是类似监控之类的应用,分布式是通过固定部署多个Source Agent 进程进行数据采集,每个Agent进程之间是互不相关的关系,例如Source 1是负责采集Tomcat服务器1的日志,Source2是负责采集Tomcat服务器2的日志数据,两者互不干扰,更重要的一点是下游的应用不需要等待Source1和Source2同时执行完成,才能进一步后续的工作,即Source1和Source2可以看做是两个独立的作业,任何一个进程出现问题,对于另一个进程的后续处理都没有任何影响,那么Flume是一个可靠的选择。
对于需要动态、实时管理(增容、缩容) 各个数据抽取进程的应用,如从一张有大量数据的分区表里抽取数据,构建索引,需要同时启动多个进程进行分布式并行抽取,最重要的一点是,这些进程是一体的,被看做是一个完整的作业。即作业中任何一个子任务如果出现问题,则整个作业被认为是失败的,下游需要及时感知一个作业所有的运行进程都结束后,才能认为这个作业是被完整地执行。那么Flume并不合适,一个基于Hadoop或者VsJob平台上构建的真正意义上的分布式数据抽取程序会是更好的选择。
注:红字这些是我认为的重要但往往没有被表达出来的区别,这么说也许有些抽象。这里举另一个类似的例子可以辅助说明:Memcached 或者Redis(早期版本),本质上也不是分布式的,因为无法进行动态自动扩容、缩容,以及数据的动态迁移;它们所谓的分布式其实是依靠客户端进行路由分发实现的。
适用范围前面章节已经说明过,这里进行归纳。
VsJob适用于此类的分布式计算场景:作业可以通过一次性切分产生多个作业分片,并且每个作业分片的运行都是独立的,不存在和其它分片的关联(即不需要归并Reduce操作)。
此外, VsJob会动态将各个作业分片分配到可用的任务节点上执行,并且监测所有的作业分片的运行结果。
在以下场景下,VsJob不适合使用:
 计算时需要跨作业分片,如多表Join、统计等较复杂的计算。这时适合使用MapReduce之类的计算模型。
计算时需要跨作业分片,如多表Join、统计等较复杂的计算。这时适合使用MapReduce之类的计算模型。
由于时间和个人能力等限制,VsJob当前阶段只完成了基础功能,以满足现有需求(分布式数据抽取和索引构建)为主。在工程细节和周边配套功能上存在很多不足,有很大的改进空间:
通过为控制节点的运行时数据提供多份副本,解决控制节点的可用性问题;通过对控制数据的持久化存储,解集群崩溃后运行时作业丢失的问题,提高系统的可靠性。
类似Hadoop的Counter机制。当前只实现简单的Counter Reporter功能。后续考虑添加更系统的各类内置和自定义Counter。
当前实现采用Zookeeper来监测、通知任务的运行状态。而Zookeeper应用于这类“写入多-读取少”的模式,性能不高,最终会影响到集群规模的增长。后续考虑更高效的实现方式如直连主动推送机制。
当前实现控制节点和任务节点都采用本地日志,导致一个完整的作业的日志是存储在不同的主机上,后续考虑使用集中式存储方式,完善各类运行日志的管理。
包括多个方面,如通信协议和数据协议的优化、并发控制的锁的优化、负载均衡策略的优化等。
基于Yarn或Mesos,为每一类Job的运行实例启用资源控制。

MapReduce介绍
VsJob可以说是简化的MapReduce版本,因此这里对MapReduce做一些简单介绍,以辅助理解。
MapReduce是一个优秀的分布式编程模型,它可以说是当前主流分布式计算的代表,启发了很多优秀的分布式计算产品的实现,如Hadoop、Spark、Tez等。
Mapreduce的基本思想是将一个单一Job的处理过程分为两个处理步骤:Map(数据拆分处理)和Reduce(数据归并计算)。通过这两个步骤可以将一个简单的Job计算逻辑表达成分布式模型,并且可以进一步通过组合多个Map和Reduce处理环节,实现对超大规模的数据集的分布式计算。
MapReduce框架实现了通信、容错、资源分配、任务调度等底层处理,简化了业务计算的分布式开发,使开发者只需要关注如何分割数据、如何归并处理等业务计算逻辑。
注:需要对MapReduce编程模型更进一步的了解,可以参考Google的MapReduce原始论文。

