
这篇文章将介绍图数据库 Nebula Graph 的查询语言 nGQL 和 SQL 的区别。不过我们不会深入探讨这两种语言,而是将这两种语言做对比,以帮助您从 SQL 过渡到 nGQL。
SQL (Structured Query Language) 是具有数据操纵和数据定义等多种功能的数据库语言,这种语言是一种特定目的编程语言,用于管理关系数据库管理系统(RDBMS),或在关系流数据管理系统(RDSMS)中进行流处理。
nGQL 是一种类 SQL 的声明型的文本查询语言,相比于 SQL, nGQL 为可扩展、支持图遍历、模式匹配、分布式事务(开发中)的图数据库查询语言。
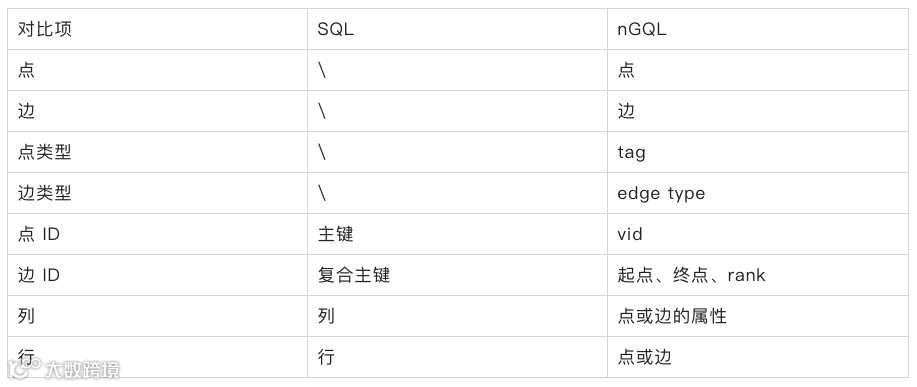
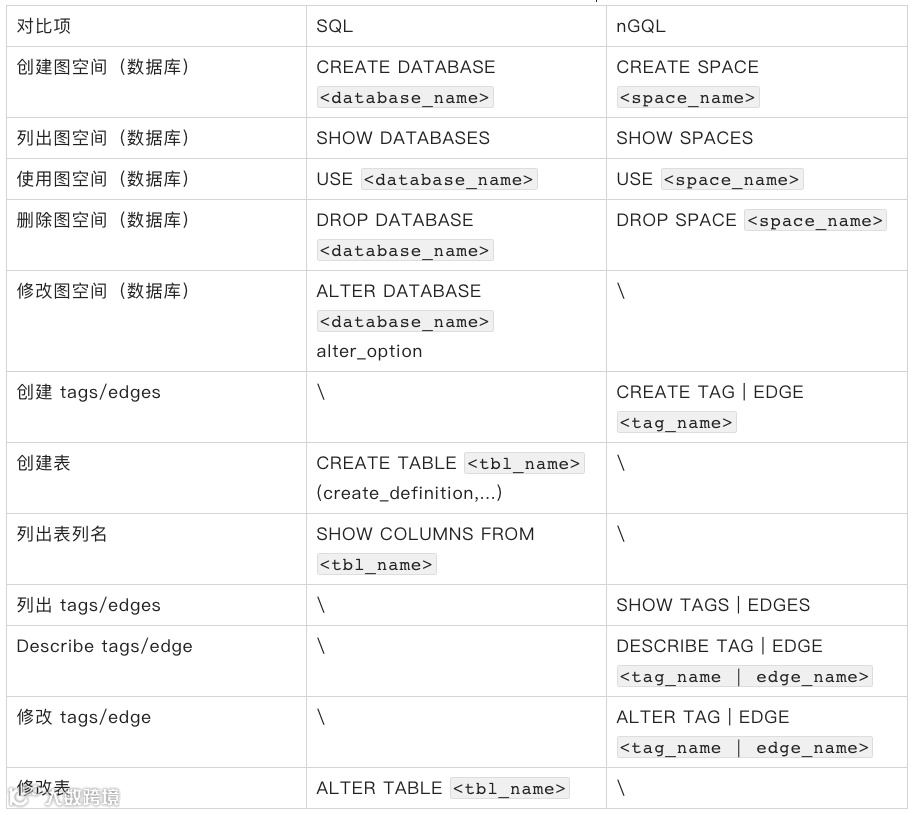
数据定义语言(DDL)用于创建或修改数据库的结构,也就是 schema。
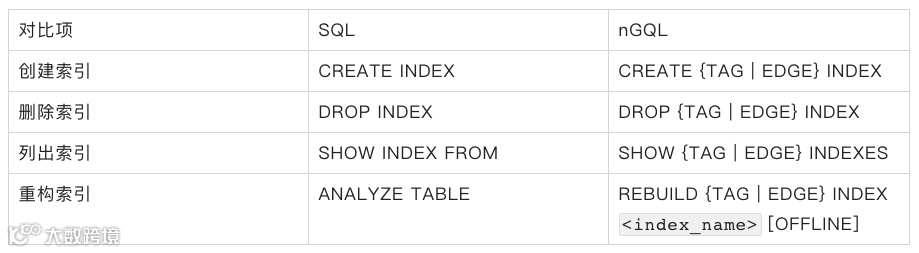
索引
数据操作语言(DML)用于操作数据库中的数据。

数据查询语言(DQL)语句用于执行数据查询。本节说明如何使用 SQL 语句和 nGQL 语句查询数据。


数据控制语言(DCL)包含诸如 GRANT 和 REVOKE 之类的命令,这些命令主要用来处理数据库系统的权限、其他控件。

查询语句基于以下数据模型:


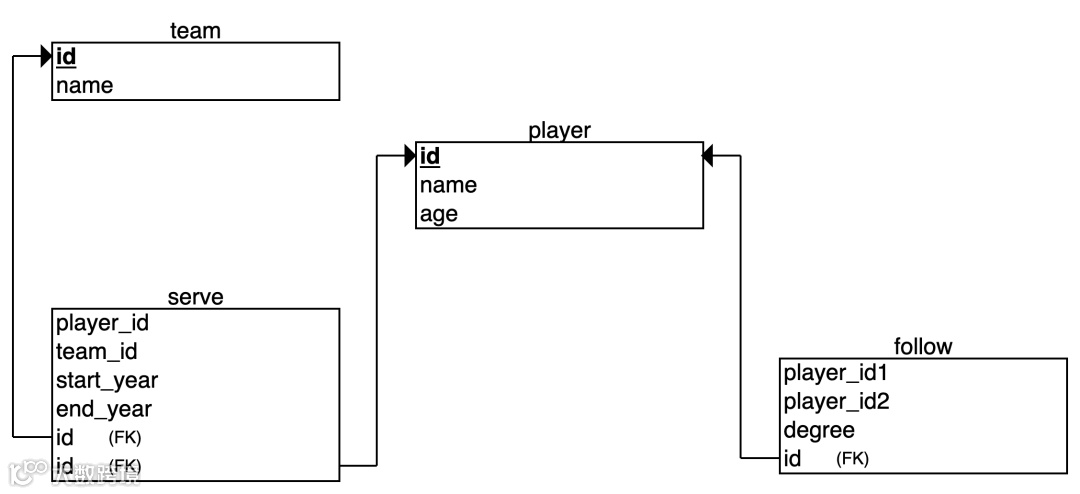

本文将使用 NBA 数据集。该数据集包含两种类型的点,也就是两个标签,即 player 和 team ;两种类型的边,分别是 serve 和 follow 。
在关系型数据管理系统中(RDBMS)中,我们用表来表示点以及与点相关的边(连接表)。因此,我们创建了以下表格:player 、 team 、 serve 和 follow 。在 Nebula Graph 中,基本数据单位是顶点和边。两者都可以拥有属性,相当于 RDBMS 中的属性。
在 Nebula Graph 中,点之间的关系由边表示。每条边都有一种类型,在 NBA 数据集中,我们使用边类型 serve 和 follow 来区分两种类型的边。
 然后插入数据。
然后插入数据。

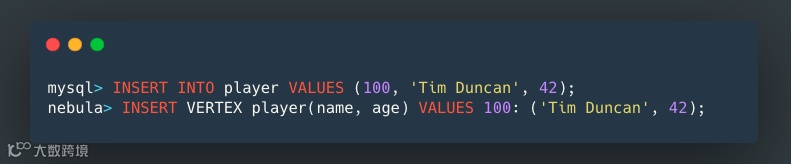
在 Nebula Graph 中插入数据与上述类似。首先,我们需要定义好数据结构,也就是创建好 schema。然后可以选择手动或使用 Nebula Graph Studio (Nebula Graph 的可视化工具)导入数据。这里我们手动添加数据。
在下方的 INSERT 插入语句中,我们向图空间 NBA 插入了球员数据(这和在 MySQL 中插入数据类似)。

考虑到篇幅限制,此处我们将跳过插入球队和边的重复步骤。
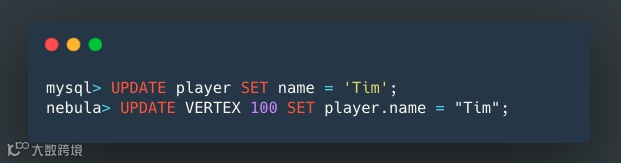
本节介绍如何使用 SQL 和 nGQL 语句创建(C)、读取(R)、更新(U)和删除(D)数据。
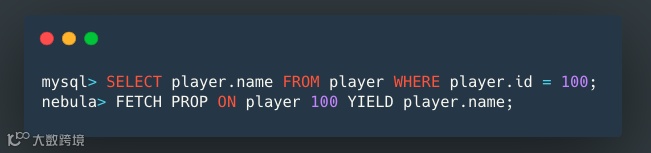
查找 ID 为 100 的球员并返回其 name 属性:

返回年龄超过 36 岁的球员。

使用 nGQL 查询有些不同,因为您必须在过滤属性之前创建索引。更多信息请参见索引文档。

本节提供一些示例查询供您参考。
在表 player 中查询 ID 为 100 的球员并返回其 name 属性。

接下来使用 Nebula Graph 查找 ID 为 100 的球员并返回其 name 属性。
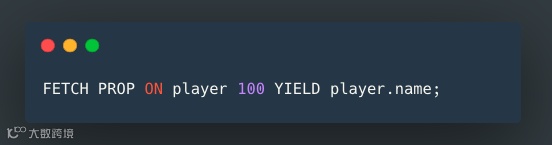
Nebula Graph 使用 FETCH 关键字获取特定点或边的属性。本例中,属性即为点 100 的名称。nGQL 中的 YIELD 关键字相当于 SQL 中的 SELECT 。
查找球员 Tim Duncan 并返回他效力的所有球队。

使用如下 nGQL 语句完成相同操作:

这里需要注意一下,在 nGQL 中的等于操作采用的是 C 语言风格的 == ,而不是SQL风格的 = 。
以下查询略复杂,现在我们来查询球员 Tim Duncan 的队友。
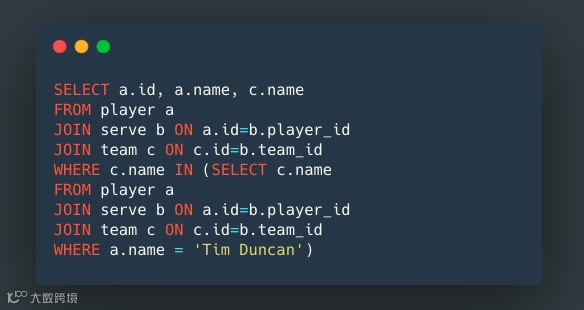
nGQL 则使用管道将前一个子句的结果作为下一个子句的输入。

Nebula Graph Studio 用户指南
Nebula Graph GitHub 仓库
Nebula Graph 快速入门文档

Hi,Hi ,大家好,我是 Amber,Nebula Graph 的文档工程师,希望上述内容可以给大家带来些许启发。限于水平,如有不当之处还请斧正,在此感谢^^
喜欢这篇文章?来来来,给我们的 GitHub:https://github.com/vesoft-inc/nebula 点个 star 表鼓励啦~~ 🙇♂️🙇♀️ [手动跪谢]
交流图数据库技术?交个朋友,Nebula Graph 官方小助手微信:NebulaGraphbot 拉你进交流群~~
