
-
图数据库市场的现状 -
图数据库的优势 -
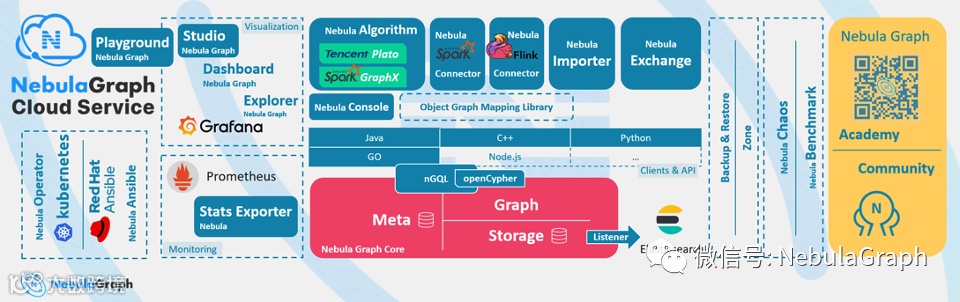
以 Nebula Graph 为例 -
开源社区






--PostgreSQL
WITH RECURSIVE post_all (psa_threadid
, psa_thread_creatorid, psa_messageid
, psa_creationdate, psa_messagetype
) AS (
SELECT m_messageid AS psa_threadid
, m_creatorid AS psa_thread_creatorid
, m_messageid AS psa_messageid
, m_creationdate, 'Post'
FROM message
WHERE 1=1 AND m_c_replyof IS NULL -- post, not comment
AND m_creationdate BETWEEN :startDate AND :endDate
UNION ALL
SELECT psa.psa_threadid AS psa_threadid
, psa.psa_thread_creatorid AS psa_thread_creatorid
, m_messageid, m_creationdate, 'Comment'
FROM message p, post_all psa
WHERE 1=1 AND p.m_c_replyof = psa.psa_messageid
AND m_creationdate BETWEEN :startDate AND :endDate
)
SELECT p.p_personid AS "person.id"
, p.p_firstname AS "person.firstName"
, p.p_lastname AS "person.lastName"
, count(DISTINCT psa.psa_threadid) AS threadCount
END) AS messageCount
, count(DISTINCT psa.psa_messageid) AS messageCount
FROM person p left join post_all psa on (
1=1 AND p.p_personid = psa.psa_thread_creatorid
AND psa_creationdate BETWEEN :startDate AND :endDate
)
GROUP BY p.p_personid, p.p_firstname, p.p_lastname
ORDER BY messageCount DESC, p.p_personid
LIMIT 100;--Cypher
MATCH (person:Person)<-[:HAS_CREATOR]-(post:Post)<-[:REPLY_OF*0..]-(reply:Message)
WHERE post.creationDate >= $startDate AND post.creationDate <= $endDate
AND reply.creationDate >= $startDate AND reply.creationDate <= $endDate
person. RETURN
id, person.firstName, person.lastName, count(DISTINCT post) AS threadCount,
count(DISTINCT reply) AS messageCount
ORDER BY
messageCount DESC, person.id ASC
LIMIT 100



GO N TO M STEPS FROM $ids OVER $edge_type WHERE $filters | FETCH PROP




-
Q:图数据库和多模数据库是冲突的吗?二者的关系是什么? -
A:相比来说多模数据库(multi-model),图数据库最大的特点是在于它的全关联,如何实现多跳查询。对应到数据库设计的话,就是考虑底层要做成一个什么样的数据格式,数据和计算怎么放在一起,这个和 multi-model 本身是不冲突的。为了提升性能,各个多模数据库处理方法并不一样:采用不同的存储引擎,或者是同一套存储引擎,数据结构可能会做成不同的样子。 -
Q:图查询设计的出发点是什么?为什么不考虑一开始基于 Gremlin 开发? -
A:对于数据分析的同学,Gremlin 并不是一个低门槛语言,有些不友好。当时 Gremlin 的设计实现要求每个算子发出来之后必进行执行出来结果,举个例子,我现在要做一个 .out 和 .in,我必须得先执行 .out 再进行 .in,这样就不能进行一个全局优化。而 18 年的时候,openCypher 并不完善,小问题有些,表达力不行需要 APOC 进行补充,而 APOC 法律协议并不像 openCypher 那么确定,所以基于此,我们自研了 nGQL。在 19 年开始,GQL(查询语言标准化)运动开始了,GQL、Cypher 和 openCypher 关系比较明显,所以演变成了现在的 nGQL。

期待和你的周日见面~同网易游戏、众安保险、携程金融探讨各种 Nebula 可行性。
