

导读:本文主要介绍原生图数据库 NebulaGraph 3 个版本演变过程中的设计思考,存储和计算(查询)在各个版本的功能变化。全文主要围绕下面三点展开:
NebulaGraph v3.0 概况
演(cai)进(guo)与(de)尝(da)试(keng)
展望 4.0
01
NebulaGraph v3.0 概况
1. 年表
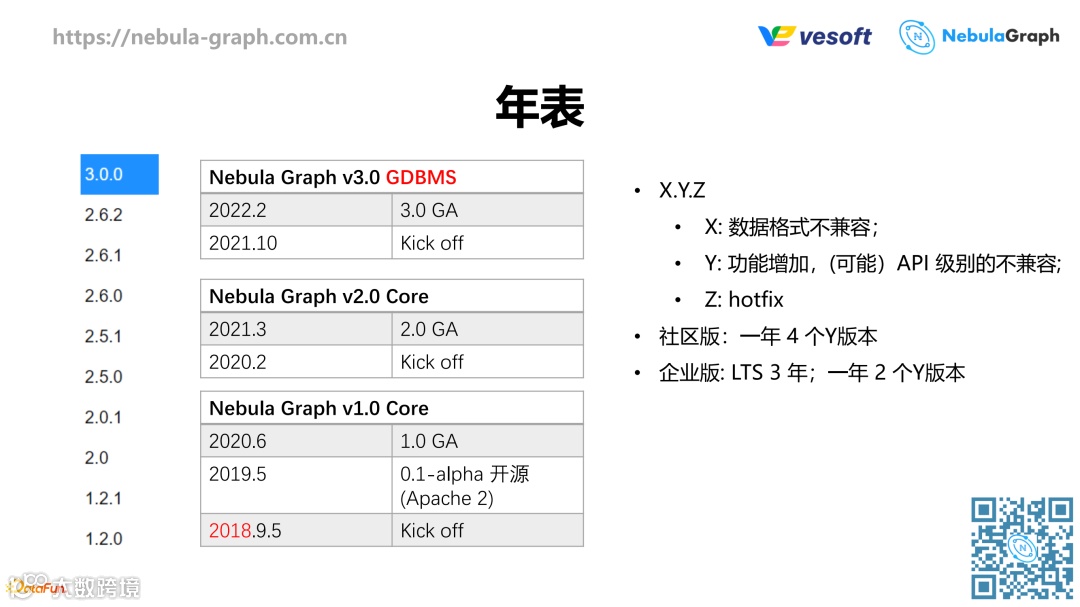
NebulaGraph 的项目是2018年9月份启动的, 分别在2020、2021、2022年发布了三个主要版本,三个版本之间数据格式不兼容,在版本号上有明确的体现。目前社区版本一年发布四个,企业版本一年发布两个,企业版将获得 LTS (Long Term Support)长期支持三年。
2. 项目整体情况

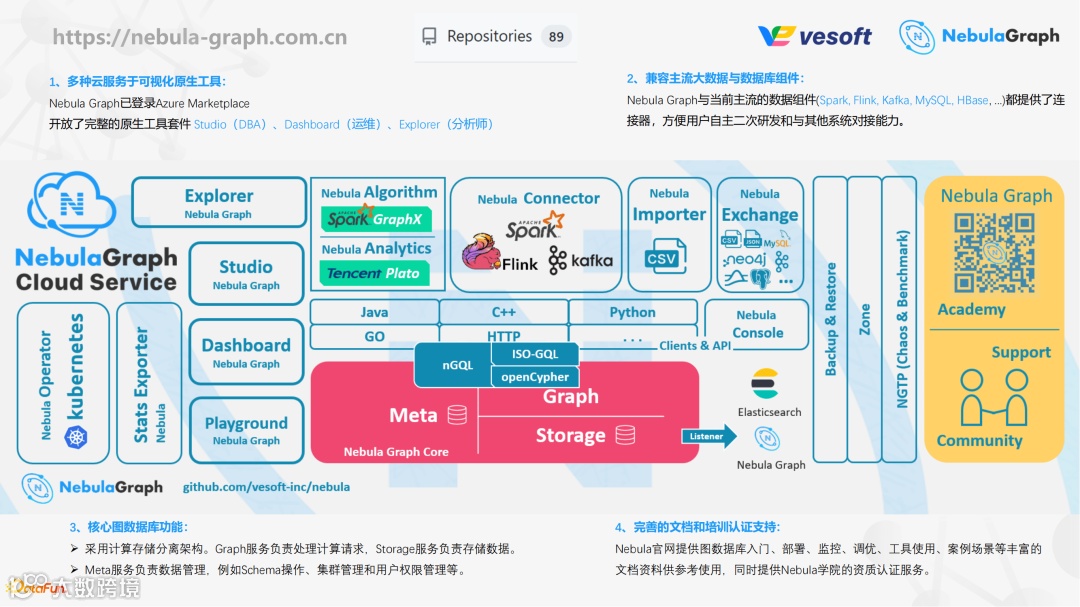
NebulaGraph 在 GitHub 中开源,整个机构下面有大概将近 100 个 repository ,核心仓库 nebula 大约 7,000 多个 star 和 1,000 多个 fork,社区里目前有 2,000 多个开发者,论坛上面有 120 万的 PV 和大约 3 万个帖子。
3. NebulaGraph 产品特性
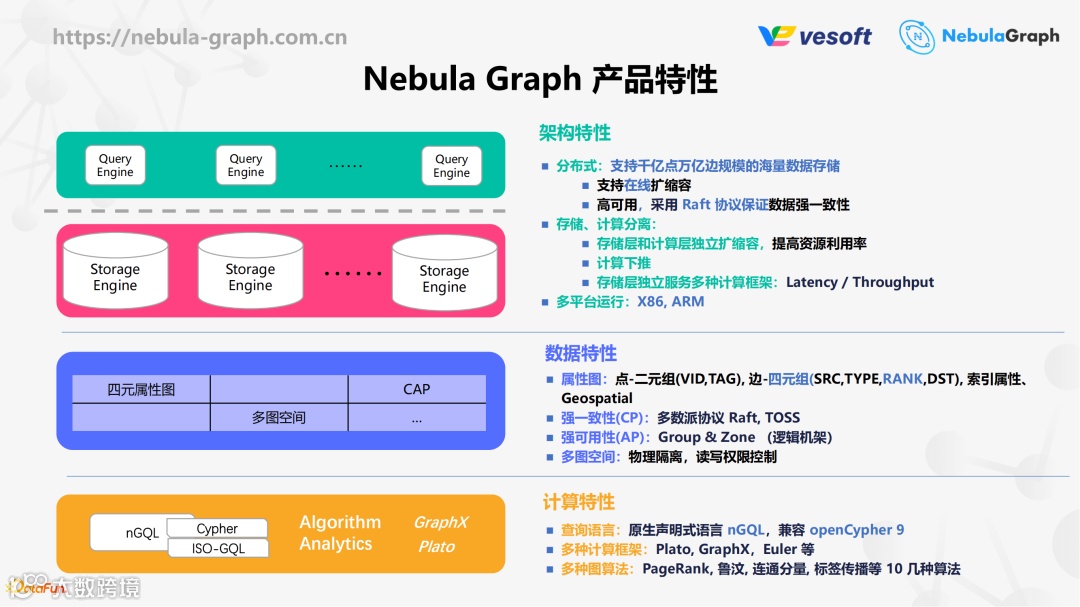
① 架构特性
分布式,目标规模是千亿点万亿边,支持在线扩缩容。存储方面采用 Raft 协议保证多副本一致性,存储节点和计算节点分离,可以独自扩缩容。支持 X86 和 ARM 多平台运行。
② 数据特性
点是二元组(VID, TAG),边是四元组(SRC, TYPE, RANK, DST)。点和边都支持属性索引,支持地理位置坐标。集群通常选择强一致性,跨机房时可优先选择高可用性。支持多图空间、物理隔离,类似 MySQL 的 database。
③ 计算特性
查询语言使用 nGQL(NebulaGraph Query Language),支持大部分 openCypher9 图查询语法。计算方面主要通过对接其他开源计算框架实现图计算。
4. NebulaGraph 介绍及 3.0 版本新增功能
① 元数据引擎

v3.0 版本主要功能之一——提供了慢查询管理。
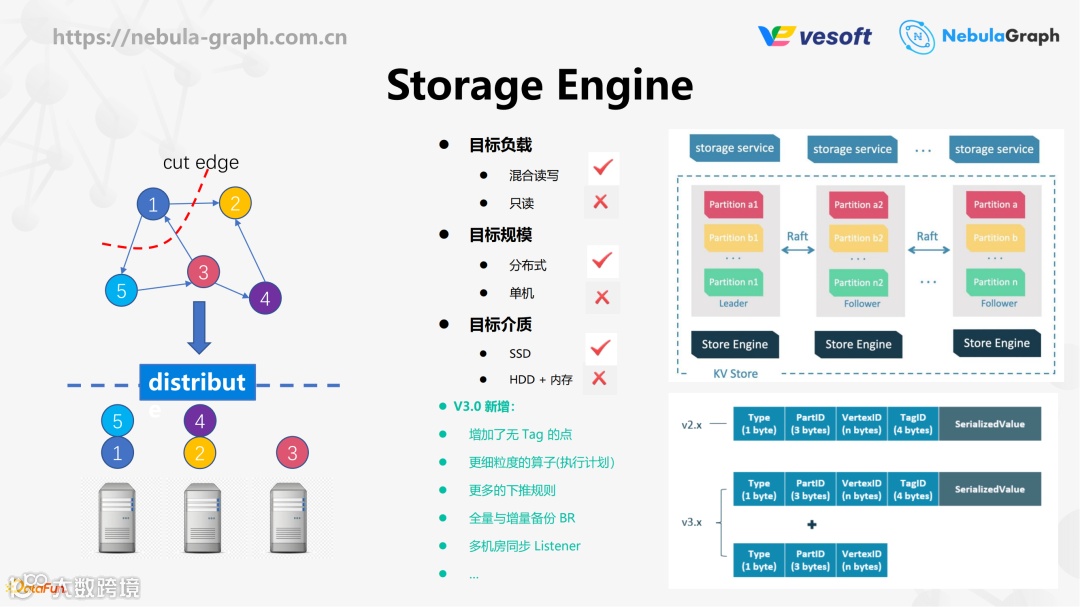
② 存储引擎
③ 计算引擎

算子:统一算子,nGQL 与 openCypher 共享物理算子;实现了更多 RBO 规则和下推方式。
openCypher 兼容(DQL) :实现了全部的 LDBC-SNB ;TCK 5k+。
④ 图计算

整个 NebulaGraph 的图计算通过把 NebulaGraph 内核的数据以一定的方式(以前是通过 CSV, 现在可以通过 API)接入第三方的计算引擎,如 Plato、GraphX、Euler 等来实现。目前需要用脚本和命令行的方式串起来,在 4.0 版本希望能更流畅一点。
⑤ 数据导入

Nebula Exchange 支持的数据源一直在增加,Exchange 和 Importer(单机)可以覆盖大多数导入场景, 导入的速度和复杂度如上图所示。
⑥ 可视化相关

Nebula Studio 是开源的,能满足一些开发团队的可视化管理诉求。

Nebula Explorer 是提供给没有图操作经验的业务人员,通过拖拉拽完成操作,不需要编写任何查询语句。

Nebula Dashboard 是日常运维监控使用的,提供扩缩容、告警等功能。
⑦ LDBC 性能测试
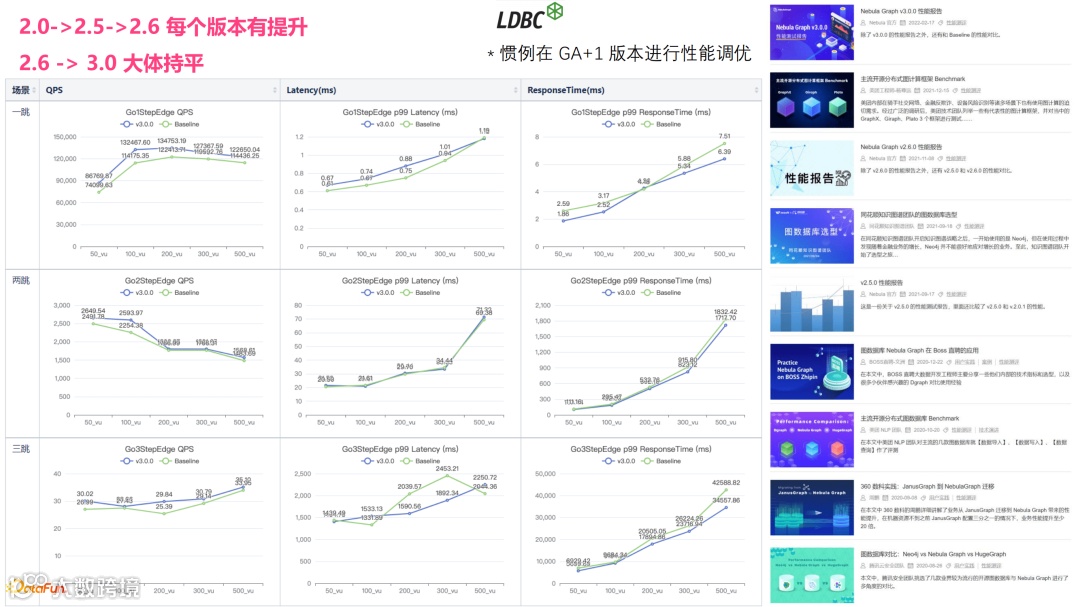
3.0 版本相比 2.6 性能大体持平,预计 3.1 版本会对性能有优化,论坛(https://discuss.nebula-graph.com.cn/)中可以找到很多官方、其他厂商和开发者做的测试。
⑧ NebulaGraph Cloud

目前 NebulaGraph Cloud 在 Azure 平台上线,支持一键部署 NebulaGraph,欢迎大家使用。
02
演(cai)进(guo)与(de)尝(da)试(keng)
1. 图语言
下面是 NebulaGraph 三个版本图语言演进过程中实现的功能和存在的问题。



接下来介绍下 ISO-GQL,它完整的发布应该在 2023 年,但今年底大体应该可以确定下来。

ISO-GQL 的草案完成度已经比较高,但还有几百处细节没有定义完 。

ISO-GQL 公开资料不多:
https://www.gqlstandards.org/
https://www.theoinf.uni-bayreuth.de/pool/documents/Paper2021-25/Paper2021/gql-sqlpgq.pdf
https://pgql-lang.org/
https://github.com/OlofMorra/GQL-parser
https://dl.acm.org/doi/10.1145/3448016.3457561
对 ISO-GQL 感兴趣的同学,推荐到这两个红色链接做进一步阅读。
2. 图结构与图属性
① 背景
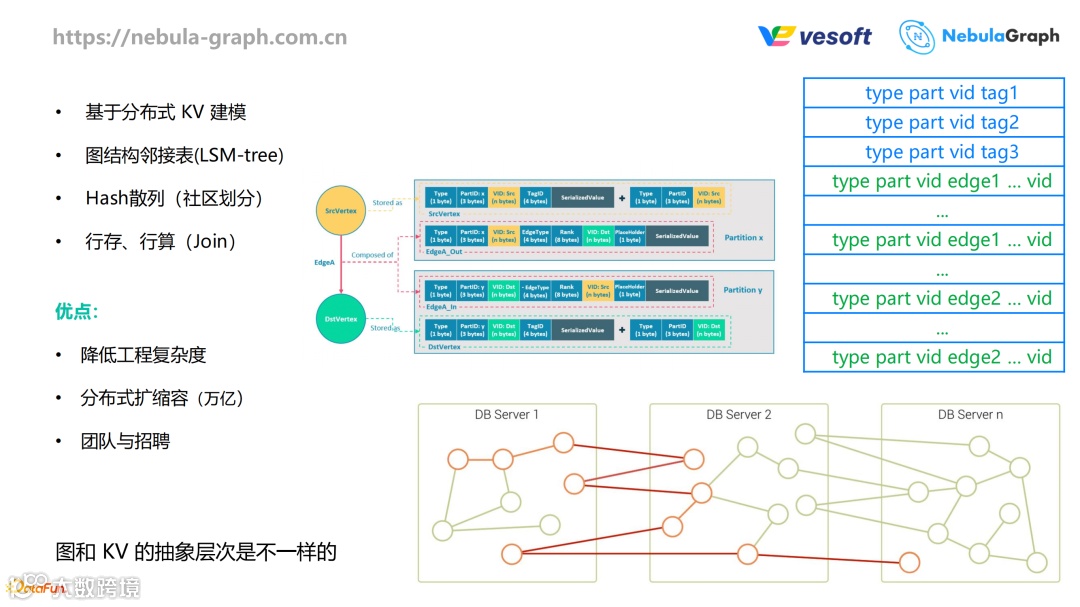
先介绍一下背景,NebulaGraph 的图最底层是依赖于 KV 建模的,对接RocksDB,把点和边建模成不同的 key 和 value。感兴趣的可以前往 GitHub 查看:https://github.com/vesoft-inc/nebula 相关代码实现。
存储方面,点尽量存储在一起,边也尽量存储在一起,然后点和边之间通过 LSM-tree 关联在一起,这样基本上组成了邻接表结构。
目前采用 Hash 散列的方式对数据做分片。Hash 散列后可能会出现整个数据四处分散,分布在不同分片上的情况。如果从数据库的角度来说,这就基本上是一个典型的行存行算式存储引擎。
这样的选择好处也很明显,例如在工程角度,复杂度可以降低很多,特别是要扩容规模的时候不会有太大限制;对于人员招聘和团队招聘来说,对于 KV 系统熟悉的人员是很多的,所以人员招聘也会非常容易。
但是图和 KV 是不同的抽象层次,其实图还是有更丰富的语义的。
② 尝试
NebulaGraph 对“predefined joins”做了一些尝试,对深度的图结构路径也好,子图也好,做了一些加速分析工作。


还有一些 "predefined joins" 工作里面,我们对图结构和图属性做分离处理的尝试。我们采用了好几种方式,测下来都可以有 5-10 倍的性能提升。KV 分离是一个工程上很常见的方法,因为图结构基本放在 key 上面,图属性放在 value 上面。当然图属性还可以切。假如先不管怎么切,把二者分开,然后图结构部分可以用 LSM-tree 或者 B-tree,这个取决于后续的考虑。图结构拆出来,后把图属性拆出来,对于图结构的访问就有很大的便利了。
除了 KV 分离,NebulaGraph 也尝试过非常多类型的缓存。比如通过一个 Listener 把整个存储的图结构放到另外一个 Storage 进程上,这个进程只放图结构;或者是把图结构缓存在计算引擎,缓存方式可能不是邻接表,也可能用矩阵形式;或者是把存储的图结构中点和边的 cache 另外设计。
比如对于点,很多时候像 LSM-tree,它有很大特点就是Empty key,需要专门处理,因为分层过滤的时它可能有一个空的hit,会浪费 Bloom Filter 的计算。对于边来说,基本上是一个 Range 范围,所以会放在两个不同的 Cache 里面;如果是分析场景的话,可能中间再加一层 Shared Memory,这一层 Shared Memory 的 Partition 方式不一定要和底层的 Storage 方式一样。这几种方式可能会导致 Cache 的无效。怎么清空或者做 Cache snapshot,一致性怎么保证,都需要另外设计。
3. 社区、商业与版本迭代
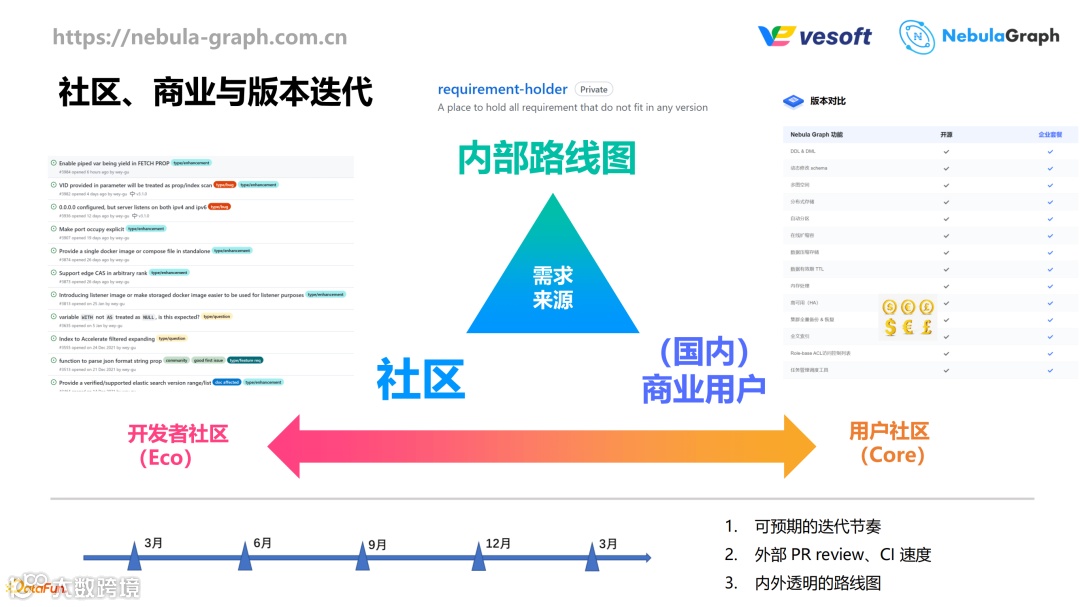
前面两个是关于技术的,第三个话题是关于社区、商业和版本迭代的。因为早前两年我主要的经历都是关于社区方面的,最近一两年我关于内部的路线图和国内的这些商业用户的经历比较多,所以个人体会也比较深。
先说需求。需求有三个方面的来源,一方面是社区,一方面来自于商业用户,特别是国内的商业用户,第三方面来源于内部的路线图。不管是社区,还是商业用户,都不一定非常关注产品长期往哪里走,所以内部还是要有一些长期目标。这三个方面的需求要有权衡。
03
展望 4.0
第三部分介绍未来一年或者两年要做的一件事情,希望内外都能够知道我们在做什么事情,整个社区在做什么事情。
1. ISO-GQL
第一部分是关于 ISO-GQL 的实现。

在今年和明年,特别是今年,一个很重要部分是对 ISO-GQL 的实现。
这个工作量会很大,估计会投入一个半组的人,需要重新设计 KV 格式,整个查询引擎基本上要重写。从 Parser 开始就得重写,虽然架构不会变,但是代码几乎得都得重写。Meta Engine也要重新设计,因为 ISO-GQL 定义的原数据比 NebulaGraph 现有的要复杂得多。
通信协议可能也会重新设计,包括错误码,因为标准已经定义了一系列的错误码,所以这个错误码得和标准接近。错误码和通信协议的改变一定会导致 SDK 和工具的重新适配。
从时间来看,预计第四季度可以先把内核的主要部分完成,适配部分工作量相对小一点,第四季度大概也可以完成,整体上这是很大的一部分工作量。
2. 图计算与图分析

图很吸引人的一点就是它很直观。今年另外两个团队在干两件事,一是对于可视化方面做一些优化和尝试,包括前段时间已经发布的 3D 可视化的预览,以及大图进行可视化展示,包括:鸟瞰、亿级别图的鸟瞰。还有图分析,这个和 Nebula Explorer 接近,它的设计初衷是希望用户可以不用自己去写Cypher,只要通过一些拖拉拽去拼算子,拼出来一个基本的 Cypher,这是可视化部分的工作。
图计算部分,在内核和各种图计算引擎之间会提供更多的 ETL 过程,不管是全量的、带过滤的、随机的 Random Walk 的,或者是用一个语句的方式去把特定要的这部分数据抽出来放到某个执行引擎里面去。当然也会增加更多的执行引擎的支持。
3. 集成测试框架 NGTP

NebulaGraph 原来有一些测试工具,nebula-bench 和 nebula-chaos,是关于各种功能和性能测试的。但不管是外部的开发者贡献PR时想做点回归,还是内部想做点回归或点压测,都非常麻烦,因为它是一个脚本集成,还要投入人力做专项的压测。
所以今年还有一件事情,就是测试开发团队会把这些东西提升起来,尽量自助地一键式地去实现压测。这样对于外部的人来说,可以更好地评估想加的某个新功能会不会对性能有影响,或者会不会 break 某些其他已有的 case。
4. Nebula Cloud Native
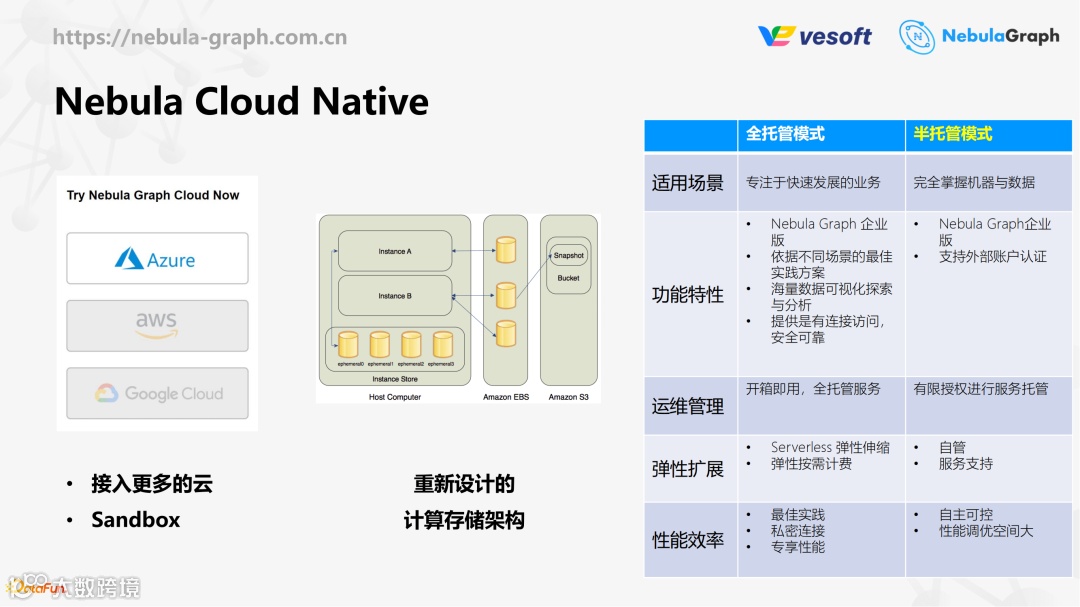
还有一件事是关于云的,也是今年的大方向之一。
因为目前的云是 Azure 上面的云,后续可能会考虑接入 AWS,因为 AWS 用户比较多,但也可能AWS用半托管的方式去接入。第二个会考虑给一个 Sandbox,一个不要钱、大家可以随便玩的 Sandbox,这个可能用单进程的模式来提供。
还有一块可能会做也可能不会做的,就是要不要根据云上面的这些基础服务去重新设计存储的架构。因为目前架在云上面的这套架构就是 NebulaGraph 本身的这三个进程直接架上去的,成本会很高。毕竟存储也是不分层的,因为云上面有 S3、有 EBS,还有很多 Spot instance,这些都没有用上。但这块要不要做还不太确定,因为改动会很大,这和 ISO-GQL 之间哪个优先还在讨论过程中。
半托管模式是可能会做的,开发成本也不会很高。和全托管的不同的地方在于机器本身是用户的,只是提供了一个 private link 或者是某种方式让 NebulaGraph 的运维团队可以上去进行一些调优和支持,这个做的话可能会在二季度放出来。
5. 商业合作伙伴——独行疾,众行远

NebulaGraph是一个开源产品,但是开源产品和商业化之间没有任何冲突,这在国外被反复证明了。商业化方面在国内有同路人计划,希望能够和更多看好这个行业前景的合作伙伴们一起成长,为自己也为客户创造更多价值。参与这个计划可以在身份、技术、商机、市场营销、销售与服务以及战略与资源方面和我们有更多的合作,享受更多服务和支持的保障。
有兴趣的伙伴可以往 Partner@vesoft.com 发邮件,或者联系我个人,我会转给我们对应的同事。希望大家能够在这些方面能够达成更紧密的合作。
6. NebulaGraph 社区活动

今年的社区也是一直会有活动,比较大的活动包括 Nebula Hackathon 黑客马拉松和 NUC 用户大会,当然实际怎么开展会受到疫情的影响。
目前的初步的计划是 NUC 用户大会邀请全行业的,包括行业上下游的大家一起来聚一聚。
第二个是 Hackathon,这是大多数开发者会比较感兴趣的。第一届 Hackathon 有二十几个团队参加,办得还挺好。今年预计还有1-2场Hackathon 活动,也会有一些经费,但应该不会有 100 万美元那么多。
第三个是几乎每一个月会在不同的城市或线上有和各种开发者们的聚会,这一次可能和过去几年不一样,过去几年分享比较多的是关于内核技术,今年会更侧重和各个大厂交流实践案例。
最后一个是每个版本发布时会有一些捉虫活动,欢迎大家一起来参与。
还有一些事是关于国际化的,这在国内的技术圈里面是最近一两年比较热门的话题,也就是中国的技术出海的这件事。NebulaGraph 这件事也会做,但是目前没有太多可以跟大家分享的,但这件事已经开始启动了。
04
精彩问答
在文末分享、点赞、在看,给个 3 连击呗~
分享嘉宾:


🙋♂️ 喜欢本文的话,来个分享、👍 赞、在看
谢谢!