
云栖大会
阿里高调宣布
第四代神龙架构问世
不能错过的阿里网络小视频

其中关键技术
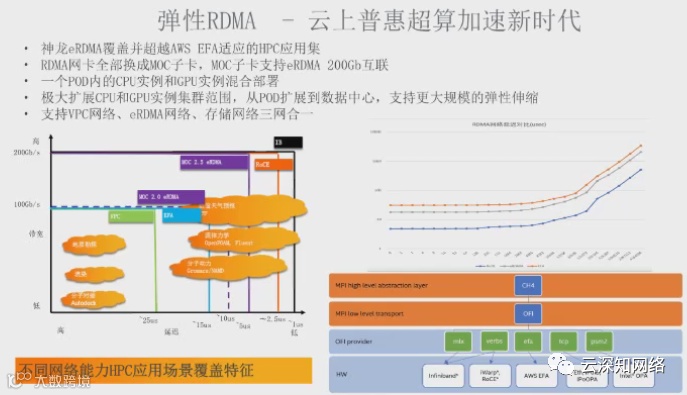
弹性RDMA更是表现神勇
覆盖并超越AWS EFA适应的HPC
RDMA网卡换成MOC就是不想给商用机会啊
DPU创业,智能网卡最新排名想给老板们上一课
到底AWS
EFA能打不能打
RDMA是不是必要条件
难得Annapurna大神们出马解读
为什么SRD可以在云上支撑HPC业务

高性能计算(HPC),指高速处理数据并执行复杂计算的能力。一般用于气象预测、系统仿真、图像渲染等场景。最早HPC的解决方案是超级计算机,后来出现了使用普通服务器构建的高性能计算的集群。
随着公共云的兴起,绝大部分计算的任务都可以在云上运行,但HPC因为其特殊的要求,一直没能真正像普通计算任务一样在公共云上部署,主要的限制就是网络,HPC要求一个低延时、低抖动的网络,而公共云的网络是构建在TCP/IP的基础上,无法满足其要求。
AWS作为公共云一哥,承载着将一切线下计算资源搬到云上的历史使命,觉得这个不能忍,于是在2019年推出了EFA(Elasitc Fabric Adapter)接口以及配套的高性能网络协议SRD(Scalable Reliable Datagram),宣称可以在云上支撑HPC业务的大规模部署。
2020年他们在IEEE的论文讲述了SRD协议的实现原理。本文主要基于这篇文章,以及AWS的官网的相关介绍,解读为什么SRD可以在云上支撑HPC业务。

HPC对网络的要求
HPC集群可以认为是一个由多台主机,通过网络连接构建一个用于完成同一个大型计算任务的整体,不同的节点间需要有大量、频繁的数据交互。

也就意味着,连接HPC不同主机的网络需要能够支撑不同主机之间快速、稳定的传输数据。
所以传统的TCP协议不行,TCP协议是设计来用于在Internet上传输数据使用的,性能本就不是优先考虑项。而且TCP在主机内收发包需要经过用户态和内核态的切换、大量的内存Copy等,更加大了时延以及对系统资源的消耗。
目前主流的解决方案是使用RDMA协议,在主机侧Bypass Kernel直接读写远端的内存数据,时延相对于TCP低很多。但RDMA的重传机制导致在丢包的情况下,重传的代价很大,所以RDMA通常要求底层是无丢包网络。目前主流的无丢包的网络协议有InfiniBand、ROCE。
AWS认为这俩都不行,ROCE依赖PFC机制,容易造成线头(Head-of-line)阻塞、拥塞扩散以及PFC死锁,在网络规模变大的时候,这些问题都还解决不了。而IB是专用网络,与Ethernet不兼容,需要独立部署一张网络,扩展性不好,而且设备成本很贵。

AWS的洞见
既然现在主流的解决方案都不行,那么AWS凭什么认为自己可以解决这个问题呢?
因为他们在尝试解决这个问题的时候,有了一个新的洞见——时延并不是最关键的指标。
如下图,网络有三个指标:
时延 —— 取决于单个包来回一次的时间
消息速率 —— 取决于单程时延以及消息发送的并发度
吞吐量 —— 取决上述两个指标,以及业务自己的处理能力

从最终效果来看,业务应该关注的是吞吐,因为吞吐决定了单位时间能处理的总业务量。
那么时延增加,必然会带来吞吐下降么?并不会。
网上有一个经典的比喻,一群人去一台ATM取钱:
正常情况,假设每个人取一次钱耗时1分钟,那么一台ATM机一天可以支撑1440-1个人取钱。也就是说时延是1分钟,吞吐是1439。
现在我们来增加下时延,让每个在取钱之前要花5分钟先填一个调查问卷(假设有5支笔,大家可以同时填),那么时延变增加了5倍,但一台ATM一天仍然可以支持1440-6=1434个人取钱,吞吐几乎没变。
AWS认为当前的基于IP+路由的网络就挺好,扩展性好、稳定性高、支持多路径故障收敛速度快,这么多年这张网络支撑了他们如此之多的业务稳定运行,如果有可能他们不想放弃这张网。

(这多路径的图看着如此眼熟,跟我当年写的拓扑计算的工具画的图简直一毛一样,仔细一看出处,还真就是俺当年的作品,可见这些年传统网络真的没啥变化 )
)
之前IB和ROCE都是在跟时延死磕,那么如果时延不是最关键的指标,是否有可能在当前的IP网络的基础上通过协议的创新构建HPC的解决方案?
于是,他们提出了SRD协议。

SRD的原理
SRD部署在Nitro卡里,以SR-IOV的方式向上层Host暴露一个PCIe的网卡设备,虚拟机可以直接使用。
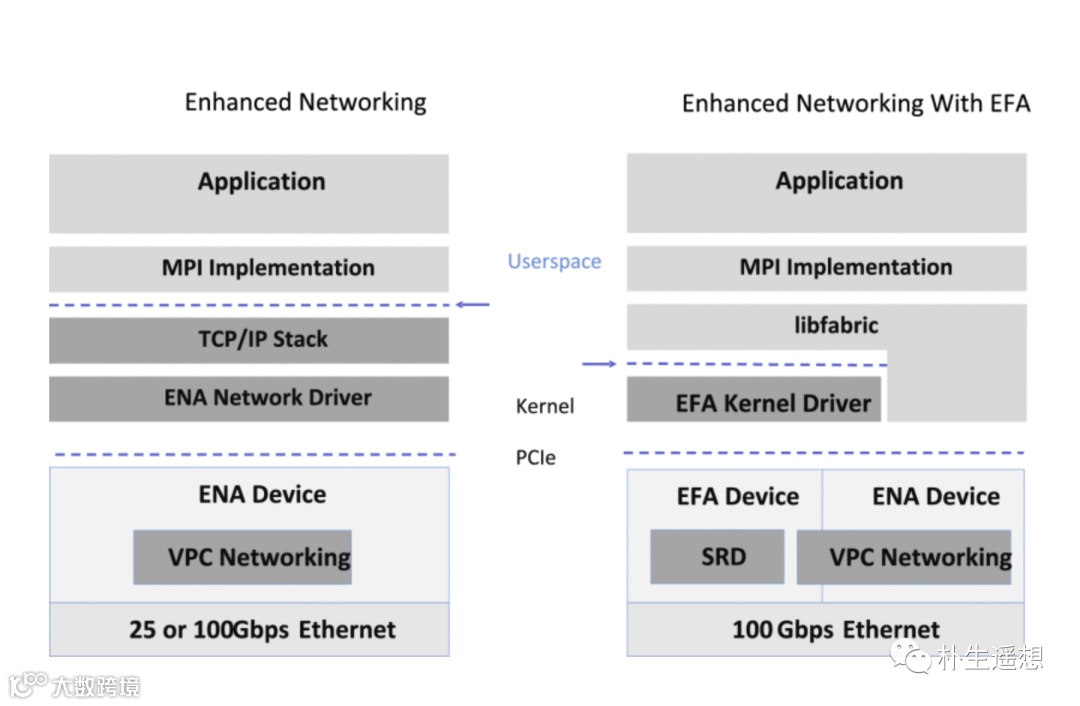
为了优化网络的性能,SRD主要做了几个事:
多路负载均衡
-
基于包粒度HASH,而不是基于流,即使只有一条流的情况,也可以将报文均匀分布到不同的路径上 -
首先SRD在发送端通过控制报文的封装来控制报文经过的ECMP路径
-
监控每条路径上的报文的RTT值,用于发现次优路径,让报文不从次优路径转发,避免拥塞或丢包 -
当网络有故障的时候,SRD可以快速从新的路径发送重传包,而不用等网络完全收敛(后者时间更长)
通过上述负载分担的机制,SRD可以做到即使有背景流量的情况下,也可以让报文均匀的分布在所有的路径上。避免了如TCP、ROCE等协议里会出现的大象流、HASH不均匀等情况导致的流量拥塞。
这里面有几个疑问还需要进一步研究:
-
HASH是逐包,还是基于其他粒度,比如基于MPI里的Message粒度 -
在传统的以太网上如何控制路径?
-
如果是采取类似Segment Routing的能力,对网络的改造比较大,太重 -
或者是提前算好所有的可能路径,然后通过控制四层报文封装的方式来控制路径?
-
如何感知网络故障,发现报文超过RTT没有回包,直接重发报文?
乱序发包
放弃基于流的HASH,必然会导致报文的乱序,前端发包乱序,后端收包必然要有人收拾残局,对报文进行缓存和重排序。Nitro卡的内存资源有限,所以SRD选择把这个重排序的工作放到Host里的用户态协议栈里进行,也就是前图中的Libfabric。
包重排序这个事,如果是TCP来做,代价会很大,因为一个包丢了,后面的包就会一直卡着,直到这个包重新收到,才能将报文正常上送。
但在HPC场景下是有优化空间的。因为HPC使用的是MPI协议(Message Passing Interface -- OSI里的5层协议),这个协议是基于消息粒度来传递信息的。
比如同时有3个消息在传递,消息1里的包乱序了,并不会影响消息3的传递。所以SRD在Libfabric里解析了MPI协议层的Message字段,并且基于消息的粒度来缓存。因为消息的长度是可控的,只要将消息长度设置在合理的值,那么缓存消息的资源,以及缓存带来的延时都会在一个相对可控的范围内。

拥塞控制
即使是把报文均匀的分布到了每一条路径,也不能保证一定没有拥塞。因为会存在多打一(Incast)的问题。所以SRD改进了拥塞控制算法,在类似BBR基础上增加了对多路径的考虑。SRD根据最近一段时间报文的RTT值,会对每个连接(per-connection)进行一个带宽预测,当下面两种情况出现的时候,就认为发生了拥塞:
-
主要路径的RTT值都有所增加 -
某些连接的带宽预测值大于实际发送值
这时候SRD会判断,如果是单条路径发生的拥塞,则通过报文重路由的方式来解决。如果是整体拥塞,那么就通过基于连接的限速来解决。

SRD的效果
在AWS上用相同的机器,对比SRD和TCP的FCT(Flow Complete Time),在多打一的情况下,SRD接近理论值抖动小,TCP抖动比较厉害,长尾时延达到理论值的3-20倍。
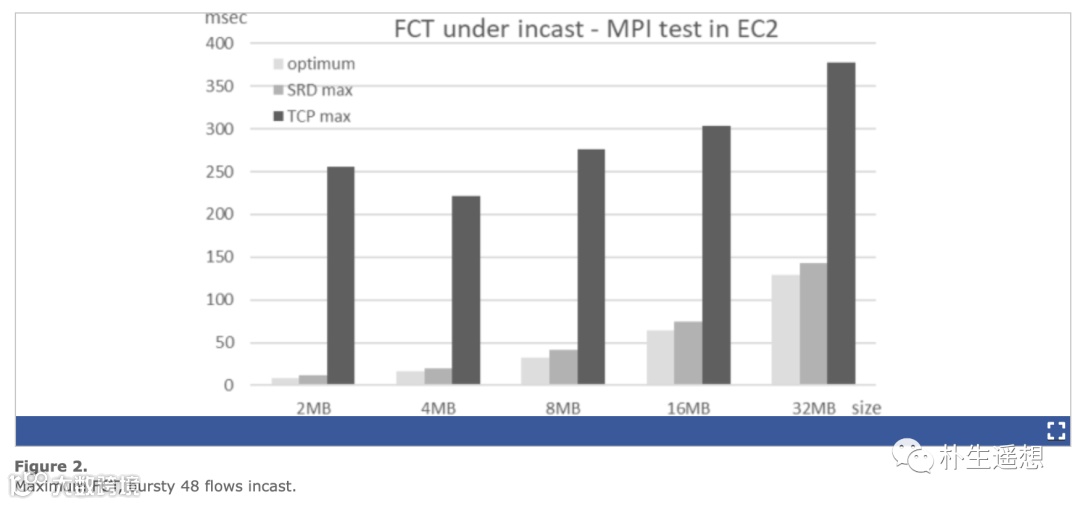
吞吐量上,多打一的情况下SRD基本接近理论值,但TCP不同的流之间差异比较大,抖动非常厉害


总结
SRD通过重新定义传输层协议,通过控制报文路径+乱序发包的方式,优化链路负载的均匀程度,并充分结合链路RTT指标来优化拥塞控制算法,在一定程度放松时延要求的前提下,实现吞吐最大化,满足了HPC应用的要求。
这里面还有一些问题没有搞的太清楚,需要进一步研究。
-
AWS的论文里只描述了与TCP的对比,SRD与ROCE/IB的对比如何(在不同的规模下) -
是否所有的HPC业务(包括AI的业务)都只关注吞吐,有没有时延敏感类的业务一定要求低时延的,为什么,业务框架有没有改进空间?
不过总的来说,AWS本着帮用户解决问题的思路,在老的问题上有了新的洞见,打破了传统方法的思路的束缚,一定程度上解决了问题。这种解决问题的方法和态度非常值得学习。
感兴趣的同学可以点个赞和在看后,在公众号后台回复“AWS SRD”获取论文。
相关阅读: