Kapacity 基于蚂蚁内部的超大规模生产业务实践,旨在为用户提供一套具备完善技术风险能力的、智能且开放的云原生容量技术,帮助用户安全稳定地实现极致降本增效,解决容量相关问题。
主代码仓库的 GitHub 地址:
https://github.com/traas-stack/kapacity
— 01 —
Kapacity V0.2 里程碑版本现已正式发布!
Kapacity 致力于通过智能手段解决云原生容量问题。在该新版本中 ,我们引入了蚂蚁自研并在生产环境大规模使用的「基于流量驱动的副本数预测」AI 算法,实现了生产级的预测式弹性伸缩。
同时,Kapacity 也致力于最大化的开源兼容,使其易于扩展的同时降低用户的使用成本。在该新版本中,我们引入了完整的自定义指标弹性伸缩支持,可同时将自定义指标用于响应式和预测式弹性,且其配置与 Prometheus Adapter 完全兼容,你可以将此前用于自定义指标 HPA 的配置直接复用于 Kapacity。
我们在今年 9 月 KubeCon China 2023 上的主题演讲中对 Kapacity 的设计理念、算法原理及整体架构等都进行了详细的介绍,错过现场演讲的同学可以猛戳下方观看视频回放!
新版本重点特性解读
▌基于流量驱动的副本数预测
⦿ 预测式扩缩容的优势
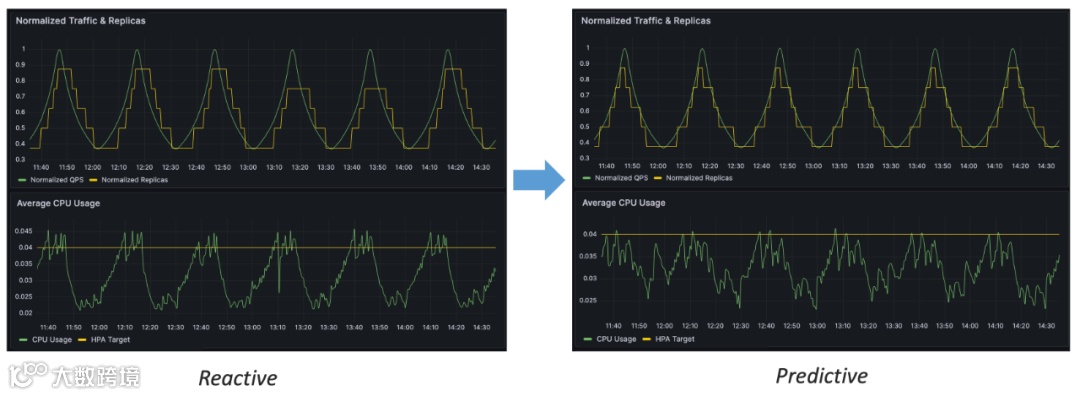
通过上图的对比,我们可以很容易地看出预测式扩缩容相比于响应式(K8s 原生 HPA)的几个优势:
这也是为什么在实际生产实践中,我们更希望优先使用预测式扩缩容。事实上,在蚂蚁内部,我们就大量使用了预测式扩缩容。值得一提的是,我们的预测式扩缩容并非简单的对目标指标进行传统时序预测,而是根据在线应用的特点开创性地设计了一套「基于流量驱动的副本数预测」算法,该算法在各类复杂的生产环境应用中都取得了非常不错的效果。下面就让我们揭开它的神秘面纱,来一探其原理:
⦿ 为什么要使用流量驱动
对于在线应用来说,容量(资源)指标(如 CPU 利用率)与流量是强相关的,即流量变化驱动了容量指标的变化。我们通过预测流量来评估容量,而非直接对容量指标进行预测,会有如下的好处:
⦿ 流量、容量与副本数关联建模
为了将副本数预测问题转化为流量预测问题,我们设计了一个 Linear-Residual Model 来找到流量、容量与副本数三者之间的关联函数,如下图所示:
在该模型中,我们将资源利用率设置为目标指标,因为控制应用的资源水位是我们使用弹性伸缩的最终目的,这也是最符合直觉的。
但不同于 K8s HPA 的响应式折比算法,虽然我们将资源利用率设置为目标指标,但该算法不会仅仅考虑资源利用率这一项指标,而是将历史流量(支持多条)、历史资源利用率、历史副本数都作为输入。这些指标会先通过一个线性模型,该模型能够学习这三者之间的线性关联,并得到上图中的关联函数;随后,它们会与其他信息一起(当前仅包含时间信息)通过一个残差模型,该将其他信息纳入考虑后对关联函数进行修正,能够学习到流量、容量和副本数之间的复杂非线性关联。
这里举一个简单的例子来说明残差模型的主要作用:假设某在线应用在每周日凌晨会执行一个内部定时任务,该任务会带来额外 CPU 资源消耗,但它与该应用处理的外部流量没有关联,这时候仅通过线性模型是无法学习到这一特征的。而引入残差模型后,该模型能够基于时间信息学习到该特征,因而在每周日凌晨的时间,我们给定与其他时间相同的流量和副本数,它所给出的函数会输出更高的 CPU 消耗,符合实际情况。
在目前的 Kapacity 开源算法实现当中,我们使用了 ElasticNet 作为线性模型,LightGBM 作为残差模型,它们都是传统机器学习算法,不强依赖 GPU,相比于深度学习算法具有更低的使用开销,并且也能得到较好的效果。当然,你也可以根据自身的使用需求替换这些模型的具体实现,我们非常欢迎大家提供你认为在某些场景下更优的实现!
在使用该模型得到关联函数之后,我们就能够把副本数预测问题转化为流量预测问题:已知目标资源利用率,只需要输入预测的流量,就能够得到(在预测流量下能够维持目标平均资源利用率的)预测的副本数。
⦿ 流量时序预测
我们设计了一个名为 Swish Net for Time Series Forecasting 的深度学习模型来对流量指标进行时序预测,该模型专为 Kapacity IHPA 的使用场景而优化,它具有下面两个主要特点:
-
轻量:该模型具有较简单的模型结构(如下图所示),这使得其具有较小的模型大小和较低的训练成本。以单条流量预测,12 个历史点预测 12 个未来点(在 10 分钟精度下即为 2 小时长度的预测)为例,其训练得到的模型大小小于 1 MiB;使用 PC 级 CPU 训练的情况下,一个 epoch 也只需要 1 分钟左右,约 1~2 小时就能训练完成。
-
在生产流量时序预测上的表现较好:我们使用生产流量数据集将该模型与其他常见深度学习时序预测模型进行了对比,可以看到该模型在生产流量时序预测任务上的表现优于其他模型,如下表所示:
|
MAE
|
RMSE
|
DeepAR
|
1.734
|
31.315
|
N-BEATS
|
1.851
|
41.681
|
ours
|
1.597
|
28.732 |
⦿ 算法工作流
最后,我们将上述两个模型与相关数据源完整串接起来,就可以得到 Kapacity IHPA 预测式扩缩容算法的完整工作流,如下图所示:
-
蓝色线为离线链路,需要较大量数据 & GPU 或较长的执行时间,但执行频率较低
-
黄色线为在线链路,执行频率相对较高,但只需要中等量数据 & CPU & 较短的执行时间
▌自定义指标支持
使用过 K8s HPA 的同学都知道 Metrics API,它提供了一套 K8s 体系内的通用指标查询接口,以支持各类用户自定义指标。但是,由于它只需要满足 K8s HPA 简单算法(响应式折比)的需求,它只支持查询指标的当前实时值,而不支持查询历史值,此外,它也不支持基于工作负载维度的 Pod 指标聚合查询,因而无法满足 Kapacity 所使用的各类智能算法的数据需求。
因此,Kapacity 对 Metrics API 进行了进一步的抽象和扩展,在最大程度兼容用户使用习惯的同时支持了通用的指标历史查询与工作负载维度聚合查询等高阶查询能力。
对于最常见的 Prometheus 监控后端,Kapacity 内置并扩展了 Prometheus Adapter 的指标解析框架,使用户能够在完全复用此前为 K8s HPA 配置的自定义 Prometheus 指标配置的情况下获得通用的历史指标查询与工作负载维度聚合查询等高阶指标查询能力。
因此,你完全可以像过去配置 K8s HPA 那样为 Kapacity 的预测式 IHPA 配置各类自定义指标。
— 03 —
未来展望
在后续版本中,我们计划持续增强 Kapacity IHPA 的技术风险防控能力,主要包括弹性变更期间的风险识别与自愈等。与此同时,通用的常态化容量风险识别与自愈也正在规划当中。
此外,为了使大家更快速轻松地上手 Kapacity,我们正在准备可视化 Dashboard 操作界面,预计不久之后就会和大家见面,敬请期待。
最后,如果你对 Kapacity 有任何新的想法或功能诉求,非常欢迎加入社区和我们直接交流,一起参与到 Kapacity 未来版本的规划和建设中来!
加入 Kapacity 社区
我们致力于将 Kapacity 项目打造为一个开放包容、有创造力的社区,所有的研发与讨论等工作都会以开源的形式在社区透明进行。欢迎任何形式的参与,包括但不限于提问、代码贡献、技术讨论等。非常期待收到大家的想法和反馈,一起参与到项目的建设中来,打造最先进的云原生容量技术!
https://github.com/traas-stack/kapacity
https://kapacity.netlify.app
欢迎各种 Issue、PR、Discussion,也欢迎直接加入下面的官方交流群,和我们一起探讨交流:






