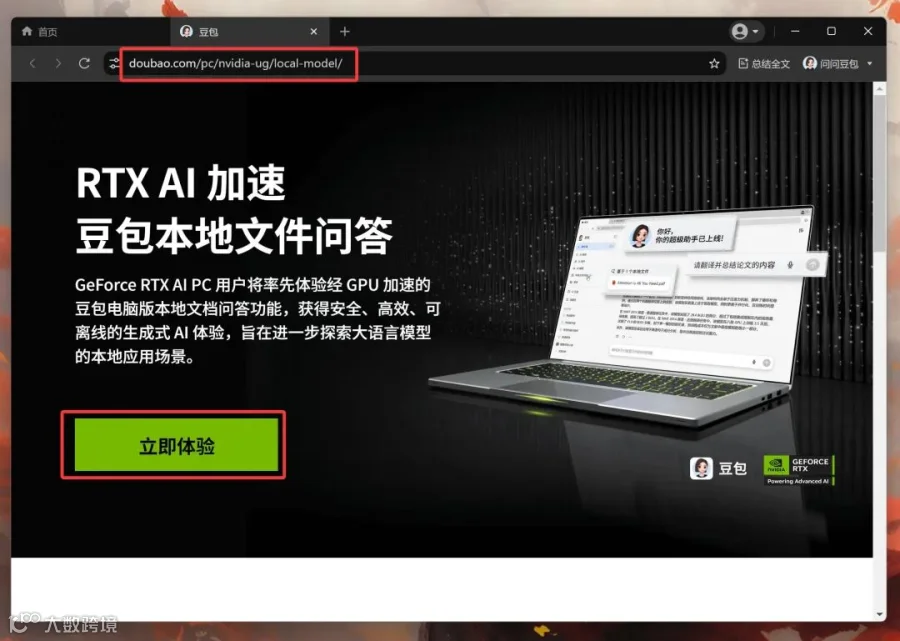
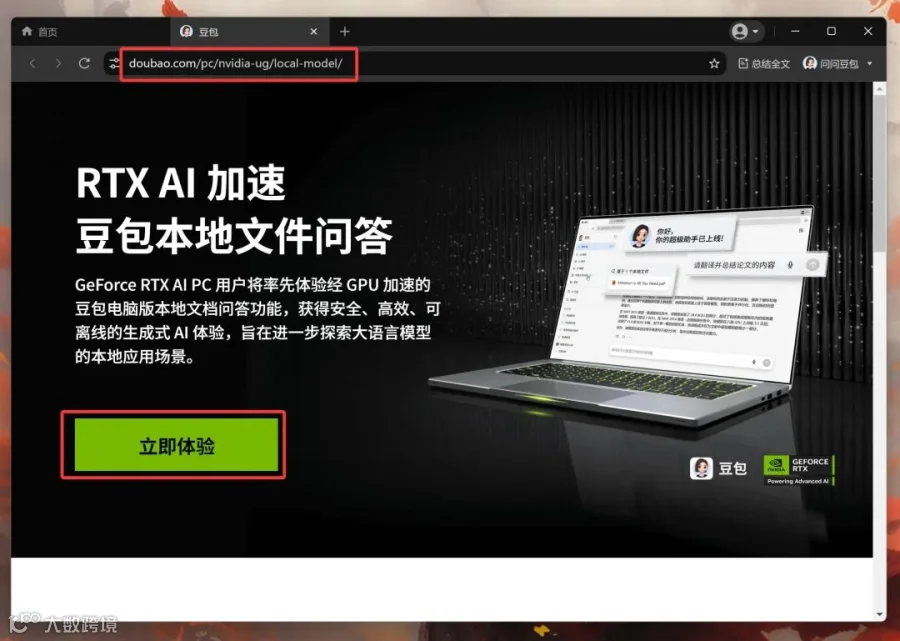
今天在某台电脑升级豆包的时候突然跳出一个提示,说是可以下载模型到本地,然后离线加载自己的知识库,进行检索和问答。
这不就是当年英伟达本地检索Demo的风格么?页面布局和主题风格几乎一模一样。还特地标注了GEFORCE RTX。莫非是豆包用英伟达的本地加速框架搞出了什么黑科技?看宣传视频好像很强的样子。
支持指定本地文件构建专属知识库,并依托本地模型及算力进行 AI 问答。 所有运算及文件处理均在本地闭环完成,无论是上传的文件,还是对话交流的内容,都不会有数据流向云端。 让你在任何时间、任何地点,都能在隐私数据得到严密保护的前提下,安心畅享 AI 带来的便捷,为日常工作学习注入强劲动力。 该功能基于大语言模型推理并由RTX提供加速,可借助 NVIDIA GeForce RTX AI PC 强大算力实现毫秒级响应。
它对本地电脑的显卡有要求也不算高,只要12G显存就可以了。
我瞬间就有点兴趣了,赶紧下载模型搞起来。顺便记录和分享一下过程和结果。
https://www.doubao.com/pc/nvidia-ug/local-model/
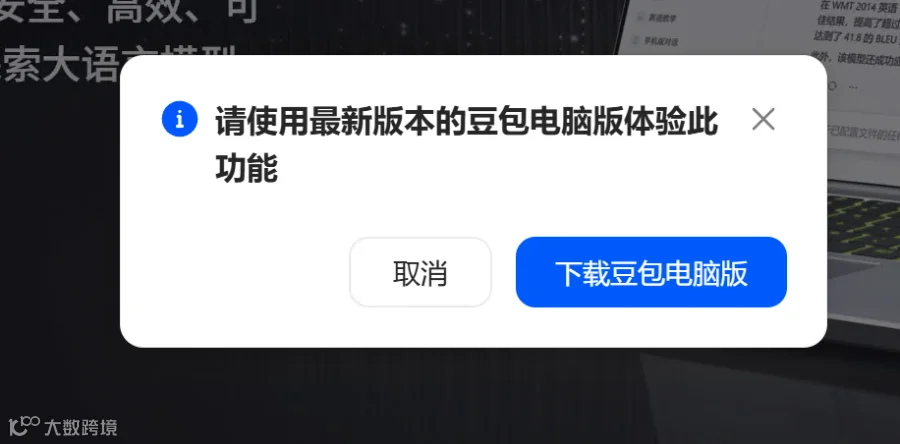
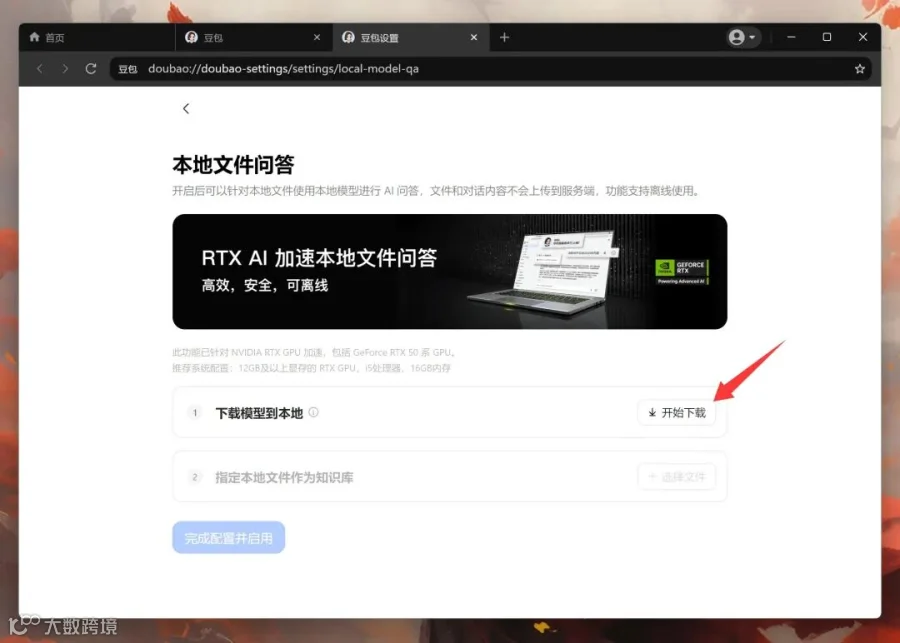
首先,它会要求你下载豆包电脑版。点击下载豆包电脑版。
安装完成之后,用豆包打开上面的网址,然后再次点击立即体验。
推荐系统配置为12GB显存的RTX显卡,i5处理器,16G内存。
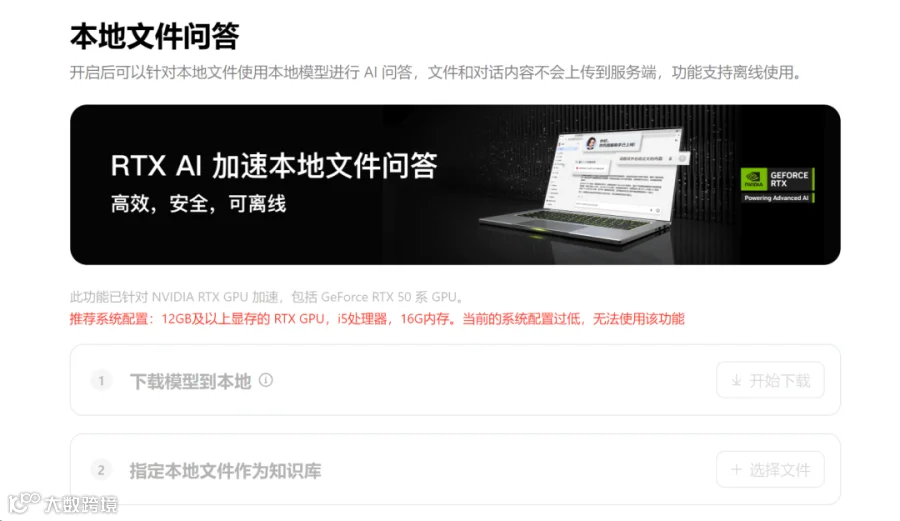
我在安装的时候遇到了一点问题,不确定不是都不普遍存在。
我在12G的3060上运行,提示我配置不够。我这显存12G,i5处理器,32G内存,刚好就在它的基准线之上啊!后来只能换台电脑把流程走完。
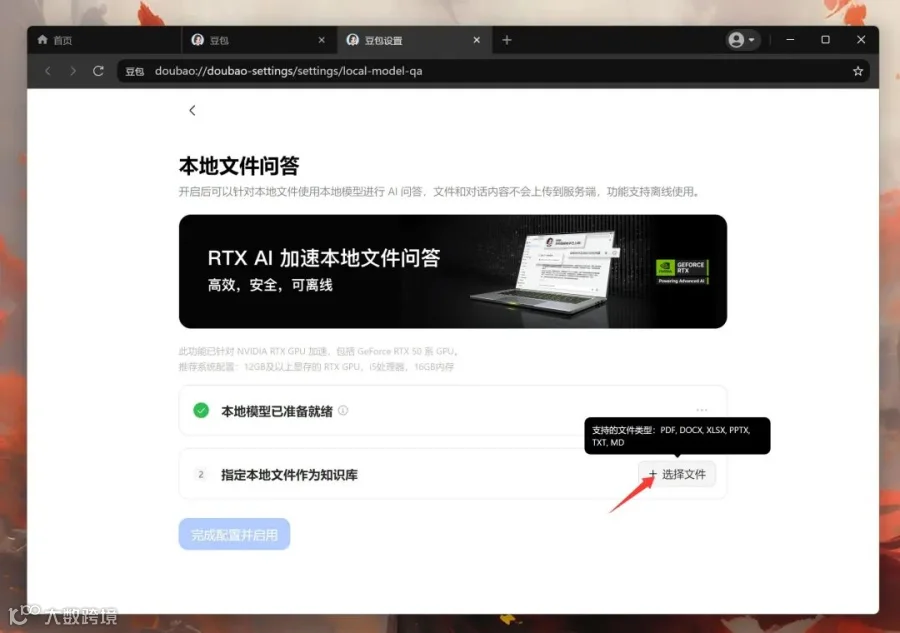
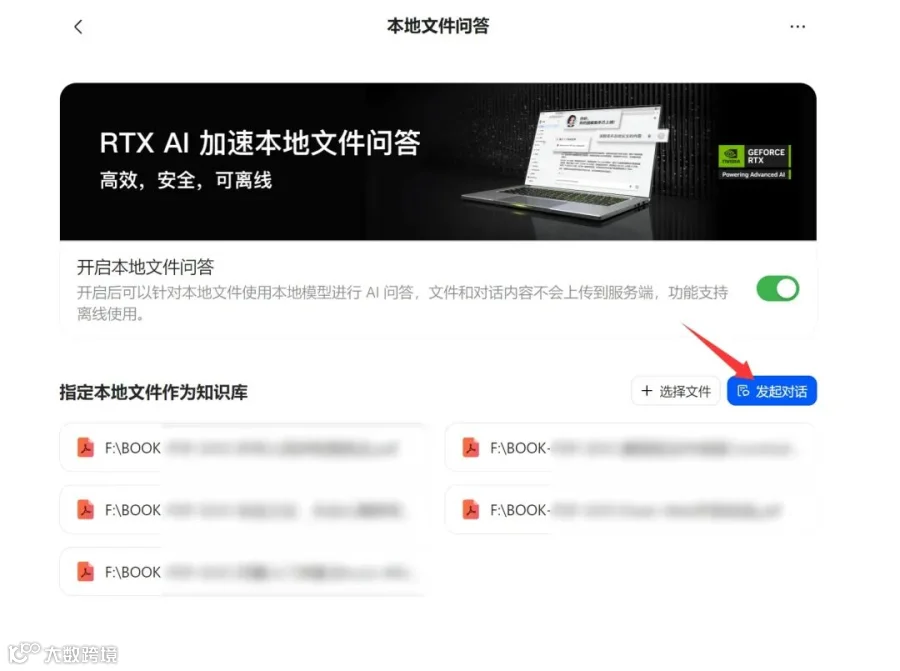
模型下载成功之后,就可以选择文件创建知识库了。所谓创建知识库,就是把你要进行本地检索的文件,全部添加进来。
当选择文件之后,就可以点击发起对话按钮,开始对话和检索内容了。
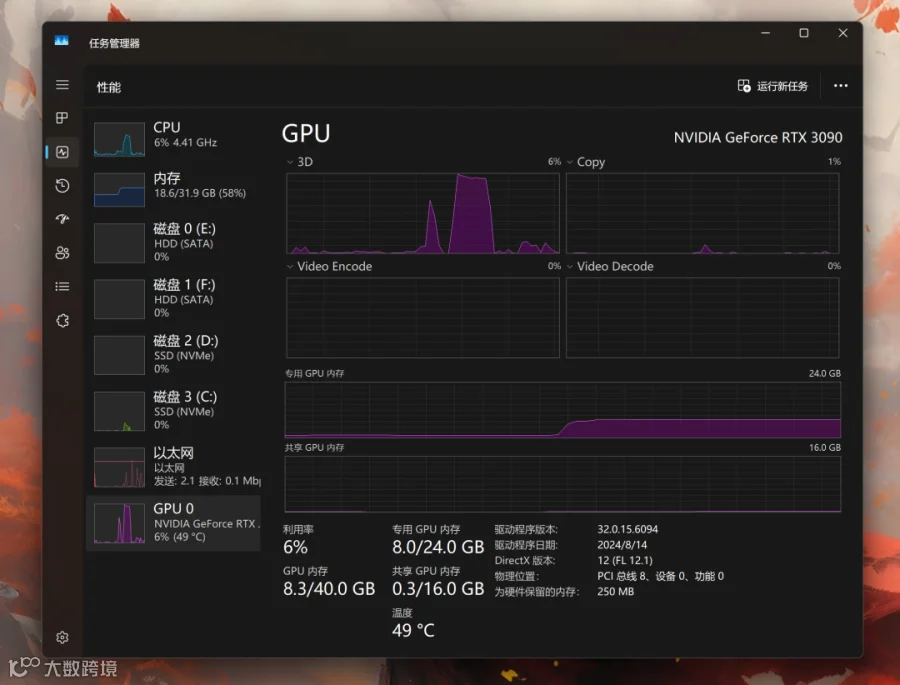
开始对话的时候,会载入本地模型。通过任务管理器,可以看到显存的消耗情况。
显存总消耗为8G左右,这个消耗量并不高,现在中高档N卡,基本就是8G起步了。
二次使用,找不到入口的时候,可以在地址栏输入上面的地址。
我把一些相关Deepfacelab的教程导入了知识库。
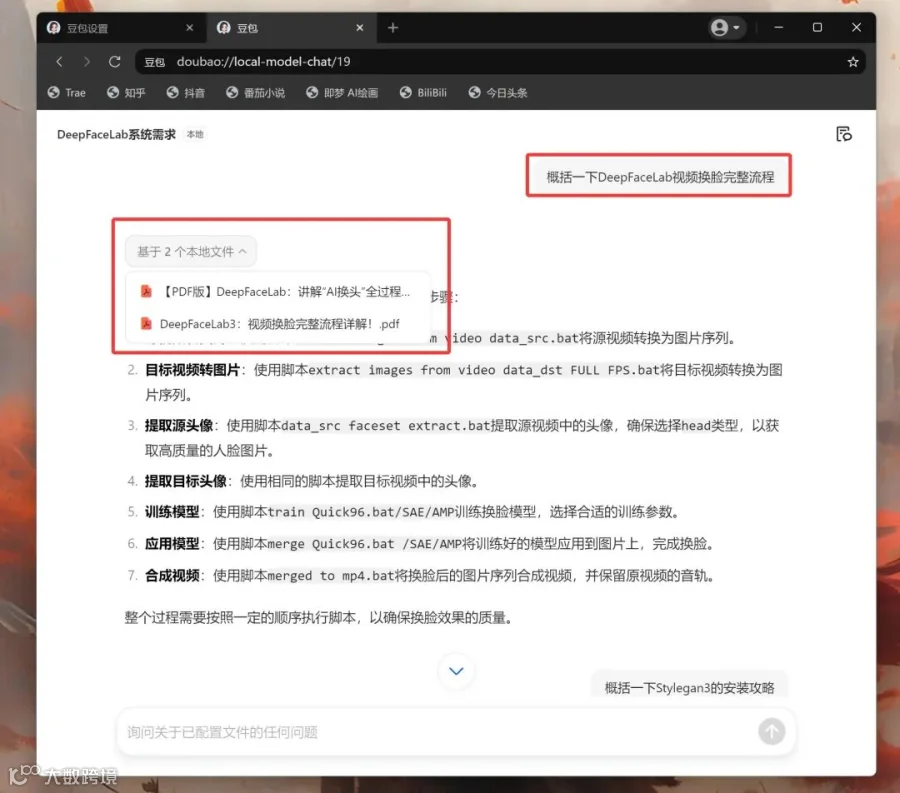
先让他概括一下DeepFaceLab视频换脸的完整流程。
它正确的找到了参考文件,并且正确的列出所有的步骤。这一次的检索质量非常高。
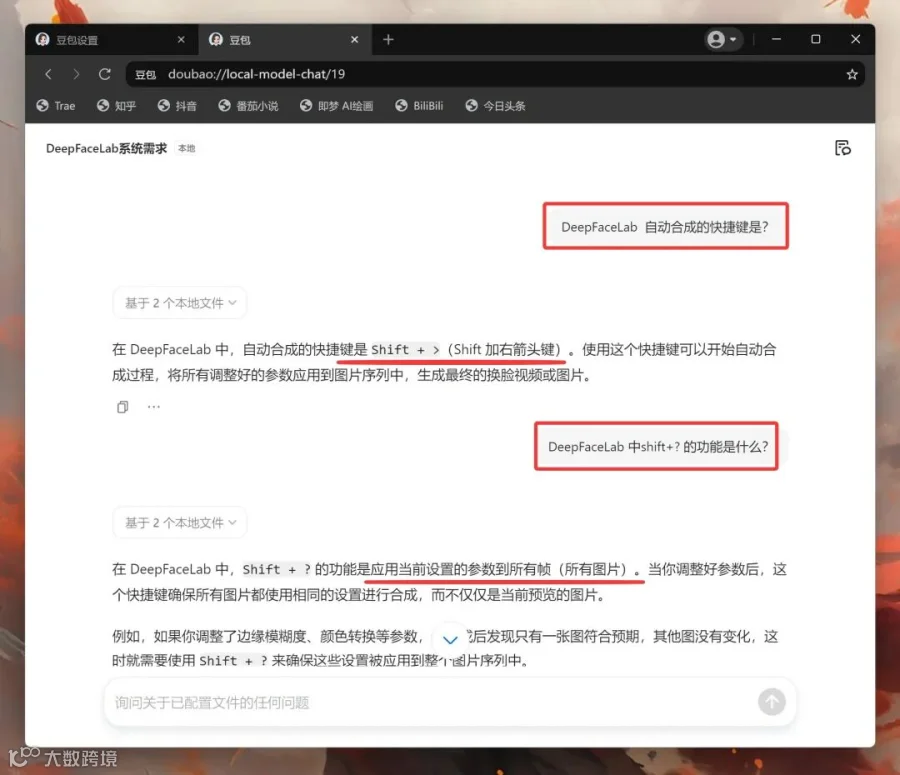
也是正确的找到了文件,并且正确回答了我的问题。快捷键和快捷键的描述是完全正确,一点不差。
其他问题也问了很多,下面举个例子说点不理想的地方。
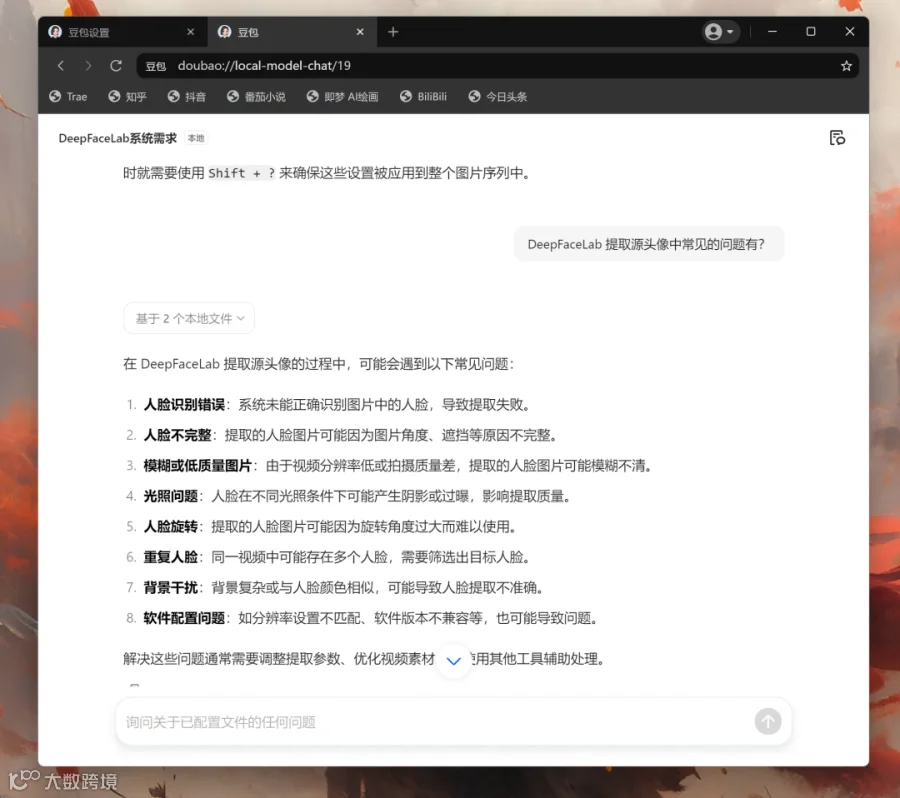
比如我提问了:deepfacelab提取头像中的常见问题?
它很快就给出了答案,这些答案基本正确,也是我在教程中提到过的点。但是它自己做了整理,甚至添油加醋,并不是严格列出那篇文章中的分类。
这也是我在问答中遇到比较多的一个问题。它会自己整理内容,但是整理能力并不是太强,容易引入幻觉。有时候会出现答案和提问匹配度不高,或者不精准的问题。
这个问题的根源可能在于本地模型能力还是略显不足,通过提示信息可以发现,这个本地检索功能的底层模型为GLM4。
GLM4是智谱AI发布的一个多模态模型,发布的时候在中文模型中也算是佼佼者。豆包中使用的应该是开源的9B版本。放在今天来说,能用,但是不强。
本地小尺寸量化模型,能力肯定会弱一些,这个是客观现实。
安全
全流程隐私保护,避免个人相关信息泄露。
高效
响应快至毫秒之间,万字文档轻松梳理、流畅总结。
可离线
断网状态依旧“火力全开”,随时随地本地运行,工作学习不断档。
上面这几点,是豆包自己对这个功能的概括。
基本与实际体验相符
安全这个不需要解释。如果资料比较敏感的情况下,这种纯本地的检索方案,就非常合适。
另外,速度确实非常快,这个检索速度完全达到了可用的程度。
相比之前英伟达的demo,安装配置简单多了,使用也方便了很多,模型对中文的处理能力也增强了很多。
总的来说,如果你想要完全离线检索本地电脑上的大量文档,这是一个不错的方案。无需登录,无需联网,无需付费。安装和试用也相对简单。