

本文字数:15137;估计阅读时间:38 分钟
作者:ClickHouse Team

Meetup活动
ClickHouse 西安第一届 Meetup 火热报名中,详见文末海报!

又到每月更新的时间了,本月的新版本已经发布!
发布概要
ClickHouse 25.11 版本带来了 24 项新功能 🦃、27 项性能优化 ⌚,以及 97 个 Bug 修复 🍄。
本次发布新增了 ACME(Let's Encrypt)集成、小型 GROUP BY 的并行合并、投影作为辅助索引等多项实用功能!

热烈欢迎所有在 25.11 版本中首次贡献的开发者!ClickHouse 社区的不断壮大令人感动,我们始终心怀感激,感谢所有为 ClickHouse 的流行和发展做出贡献的人。
以下是本次新增的贡献者名单:
AbdAlRahman Gad、Aleksei Shadrunov、Alex Bakharew、Alex Shchetkov、Animesh、Animesh Bilthare、Antony Southworth、Cheuk Fung Keith(Chuck)Chow、Danylo Osipchuk、David K、John Zila、Josh、Julian Virguez、Kaviraj Kanagaraj、Ken LaPorte、Leo Qu、Lin Zhong、Manuel、Mohammad Lareb Zafar、Nihal Z. Miaji、NilSper、Nils Sperling、Saksham10-11、Saurav Tiwary、Sergey Lokhmatikov、Shreyas Ganesh、Spencer Torres、Tanin Na Nakorn、Taras Polishchuk、Todd Dawson、Zacharias Knudsen、Zicong Qu、luxczhang、r-a-sattarov、tiwarysaurav、tombo、wake-up-neo、zicongqu

贡献者:Konstantin Bogdanov、Sergey Lokhmatikov
ClickHouse 25.11 版本引入了自动申请和使用 TLS 证书的功能。这些证书可通过 ClickHouse Keeper 在整个集群中共享,并支持与 Let's Encrypt、ZeroSSL 等多个证书颁发机构集成。
以下是一个配置示例:
# /etc/clickhouse-server/config.d/ssl.yamlhttp_port: 80acme:email: feedback.comterms_of_service_agreed: true# zookeeper_path: '/clickhouse/acme' # by defaultdomains:- domain: play.clickhouse.com

贡献者:Jianfei Hu
“我们优化 ClickHouse,然后继续优化 ClickHouse,还是不满足,于是再继续优化!”——ClickHouse 创始人 Alexey Milovidov 在最近的版本发布研讨会上如是说。
GROUP BY 一直是 ClickHouse 中最重要的关系操作符之一。它具备最丰富的专用实现方式、最多样化的算法选择,并持续进行性能优化。
继上个版本中对使用简单 count() 聚合的 GROUP BY 操作进行了内存和 CPU 使用率的优化后,本次更新再次带来性能提升:在处理小范围的 8 位和 16 位整数键时,GROUP BY 操作将变得更加高效。我们通过对某个专用聚合结构的合并步骤进行并行化实现了这一优化。
(这一优化主要适用于某些特定场景的查询,但在 ClickHouse,我们始终致力于通过各种方式让查询变得更快,不论性能提升是全面性的还是针对性的。)
在介绍一个具体示例之前,我们先来简单看看这个优化背后的原理。
GROUP BY 当前是如何并行执行的
正如我们在之前的版本发布中所介绍的那样,ClickHouse 会在所有 CPU 核心上对 GROUP BY 操作进行高度并行化处理:
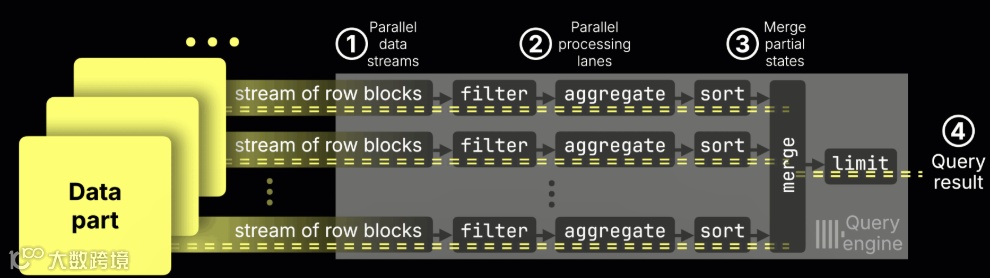
① 数据以块为单位流入引擎,
② 每个 CPU 核心处理自身负责的数据范围(包括过滤、聚合和排序),
③ 然后将所有流的部分聚合状态 ④ 合并为最终结果。
在聚合阶段内部,① 每个数据流维护一张属于自己的哈希表,用于将每个键映射到对应的部分聚合状态。例如,avg() 聚合函数会为每个键分别记录本地的总和和计数。随后,这些部分聚合状态会被 ② 合并,并进行 ③ 最终计算处理:

在常规情况下,ClickHouse 会使用一种两级哈希表结构,键对应的聚合状态存储在一个共享的内存池中:

此时,合并步骤本身(如上方动画中的 ②)也会通过多个合并线程并行执行。
(此外,如果查询中使用了多个聚合函数,例如 COUNT、SUM 或 MAX,每个聚合函数都会维护独立的部分状态,它们的合并操作也会彼此并行进行。)
但 GROUP BY 是高度特化的
ClickHouse 并不依赖单一类型的哈希表实现,而是拥有超过 30 种针对不同场景的专用变体,并会根据如下因素自动选择合适的实现:
键的类型、
预期的基数(cardinality)、
所使用的聚合函数、
以及其他查询特征。
例如:
在 GROUP BY … count() 的场景中,ClickHouse 会完全跳过内存池,直接将计数值写入哈希表的单元格。
在对小整数键(8 位、16 位)进行分组的查询中,ClickHouse 会采用高度优化的 FixedHashMap,这本质上是一个以键值为索引的数组。
而这类针对性的优化正是本文的重点。
尽管在通用的两级哈希表结构下,合并步骤是并行执行的,但在本次发布之前,当聚合使用 FixedHashMap 时,合并过程仍是单线程的。
这就意味着,那些对小整数字段(在维度分析和类别分析中非常常见)进行分组的查询,之前无法受益于多线程的合并优化。
25.11 新特性:FixedHashMap 支持并行合并
在 ClickHouse 25.11 中,针对使用 8 位和 16 位小整数键的 GROUP BY 查询,合并步骤现已实现并行化。虽然每个处理流仍各自构建一个 FixedHashMap,但最终的合并过程现在可以由多个线程并行完成,每个线程负责处理哈希表中不同的区域。
示例:按房产类型计算平均价格
以下是一个基于 8 位键的查询示例,用于计算英国房产价格数据集中不同房产类型的平均价格:
SELECTtype,avg(price) AS price_avgFROM uk_price_paidGROUP BY type
type 列的数据类型为 Enum8('terraced' = 1,'semi-detached' = 2,'detached' = 3,'flat' = 4,'other' = 0),在 ClickHouse 内部以 8 位整数进行存储。
在执行该查询时,每个处理流会将部分聚合状态存储于一个 FixedHashMap 中——本质上是一个以键值为索引的数组。这种结构不仅具备极高的插入和查找效率,更关键的是,它允许多个合并线程在彼此互不冲突的键区间上并行工作,从而避免了锁竞争问题。
下方的三幅图展示了在一台拥有三个 CPU 核心的机器上,三个处理流各自独立产生的部分 avg 状态:
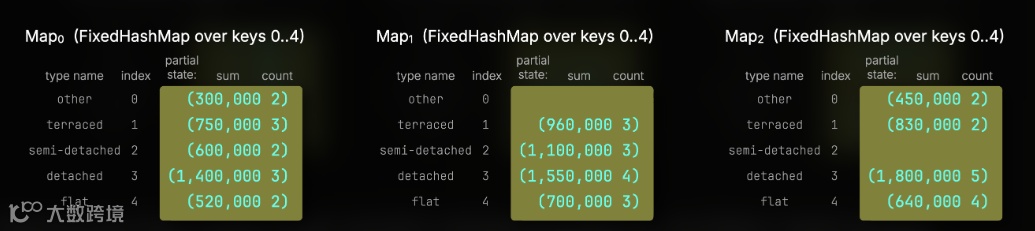
ClickHouse 随后通过三个并行合并线程来整合这些部分状态。每个线程分配一个编号(0 到 2),仅处理对应编号的键位。例如,线程 0 处理位置 0、3、6…,线程 1 处理 1、4、7…,线程 2 处理 2、5、8…。
下图示意了三个线程(以不同颜色标示)如何对多个 map 中的对应条目进行合并:

在实际运行中,所有的部分 map 都会合并为一个最终结果的 FixedHashMap。每个合并线程将其负责的键所对应的平均值写入该表。由于该设计确保线程间可安全并行写入不同部分,而传统哈希表在插入时并不具备线程安全性,因此无法实现类似的优化。
性能提升
本次优化对于需要执行复杂合并操作的聚合函数效果最为显著。在典型的 GROUP BY 查询中,合并阶段只是整个执行流程的一部分,其他环节还包括数据读取、表达式计算以及排序等。像 count、avg、max、min 这类简单聚合函数中,合并阶段对整体查询时间的影响很小。而对于类似 uniqExact 这类会维护较大中间状态的聚合函数,其在合并阶段的开销显著,因此也最能从本次优化中获益。
为了更直观地展示优化效果,我们选择了 uniqExact 函数作为测试对象。它的中间状态会存储原始的唯一值(或根据类型存储其哈希值),合并时通过去重并集(distinct union)的方式完成。
我们在一台 AWS EC2 m6i.8xlarge 实例(32 核心、128 GB 内存)上进行了基准测试,使用了 gp3 类型的 EBS 存储卷(16K IOPS、最高吞吐量 1000 MiB/s),并执行了如下查询:
SELECTtype,uniqExact(street) AS uFROM uk.uk_price_paidGROUP BY typeORDER BY u ASC;
(你可以按照文档说明自行创建表格并加载测试数据。(https://clickhouse.com/docs/getting-started/example-datasets/uk-price-paid))
在 25.10 版本中,三次运行中最快的一次(在操作系统页面缓存已清空的前提下)耗时为 0.143 秒:
5 rows in set. Elapsed: 0.159 sec. Processed 30.73 million rows, 100.09 MB (193.80 million rows/s., 631.22 MB/s.)Peak memory usage: 153.28 MiB.5 rows in set. Elapsed: 0.143 sec. Processed 30.73 million rows, 100.09 MB (214.45 million rows/s., 698.48 MB/s.)Peak memory usage: 152.92 MiB.5 rows in set. Elapsed: 0.148 sec. Processed 30.73 million rows, 100.09 MB (207.14 million rows/s., 674.66 MB/s.)Peak memory usage: 154.35 MiB.
而在 25.11 中,在相同测试条件下,最快运行时间为 0.089 秒:
5 rows in set. Elapsed: 0.101 sec. Processed 30.73 million rows, 100.09 MB (302.84 million rows/s., 986.37 MB/s.)Peak memory usage: 113.11 MiB.5 rows in set. Elapsed: 0.089 sec. Processed 30.73 million rows, 100.09 MB (344.56 million rows/s., 1.12 GB/s.)Peak memory usage: 112.69 MiB.5 rows in set. Elapsed: 0.092 sec. Processed 30.73 million rows, 100.09 MB (335.41 million rows/s., 1.09 GB/s.)Peak memory usage: 112.61 MiB.
最终结果为:0.089 秒 对比 0.143 秒 —— 性能提升约 40%。
此外,如果在执行查询时启用追踪日志(SETTINGS send_logs_level = 'trace'),在 25.11 中可以清楚确认系统使用了并行合并路径。
...AggregatingTransform: Use parallel merge for single level fixed hash map....
总结来说:所有基于小整数键的 GROUP BY 查询现在都能充分利用并行合并的能力,从而实现进一步的性能加速。

贡献者:Amos Bird
主索引是 ClickHouse 加速筛选查询的核心机制之一。通过将表的数据按排序键有序存储在磁盘上,ClickHouse 能够维护一个稀疏索引,从而快速定位相关数据范围。
但由于这个索引依赖于表的物理排序方式,因此每个表只能拥有一个主索引。
为了提升那些筛选条件与主索引不匹配的查询性能,ClickHouse 提供了“投影”功能 —— 这是以不同排序顺序维护的自动化隐藏表副本,因此具备不同的主索引。这样的替代存储结构能够加快对特定列排序优化的查询。不过,过去这项功能的缺点是较高的存储成本:投影会在磁盘上复制整张基础表的数据。
自 25.6 版本起,ClickHouse 支持创建更轻量的投影,它们的行为类似于辅助索引,但无需复制完整的数据行。这些轻量投影只存储排序键和一个 _part_offset 指针,指向基础表中的原始数据,从而大幅降低存储开销。
当查询条件匹配时,ClickHouse 会将这种投影的主索引作为辅助索引来定位匹配行,而实际数据仍从基础表中读取。多个轻量级投影可联合使用,因此当查询包含多个过滤条件时,所有符合条件的投影都能协同参与;如果其中某个条件也匹配基础表的主索引,那么主索引也会参与进来。
在此之前,这种机制仅能在 part 级别进行数据裁剪,无法细化到 granule(块标记)级别。
而在本次版本中,基于 _part_offset 的投影已实现 granule 级裁剪,真正具备辅助索引能力,能够实现更精细的筛选,大幅提升查询效率。
为演示该特性,我们再次使用英国房产成交价格数据集,并定义包含两个基于 _part_offset 的轻量级投影的表结构:by_time 和 by_town。
CREATE OR REPLACE TABLE uk.uk_price_paid_with_proj(price UInt32,date Date,postcode1 LowCardinality(String),postcode2 LowCardinality(String),type Enum8('terraced' = 1, 'semi-detached' = 2, 'detached' = 3, 'flat' = 4, 'other' = 0),is_new UInt8,duration Enum8('freehold' = 1, 'leasehold' = 2, 'unknown' = 0),addr1 String,addr2 String,street LowCardinality(String),locality LowCardinality(String),town LowCardinality(String),district LowCardinality(String),county LowCardinality(String),PROJECTION by_time (SELECT _part_offset ORDER BY date),PROJECTION by_town (SELECT _part_offset ORDER BY town))ENGINE = MergeTreeORDER BY (postcode1, postcode2, addr1, addr2);
接着,我们按照文档说明加载数据(https://clickhouse.com/docs/getting-started/example-datasets/uk-price-paid)。
下图展示了基础表及其两个轻量投影的大致结构:
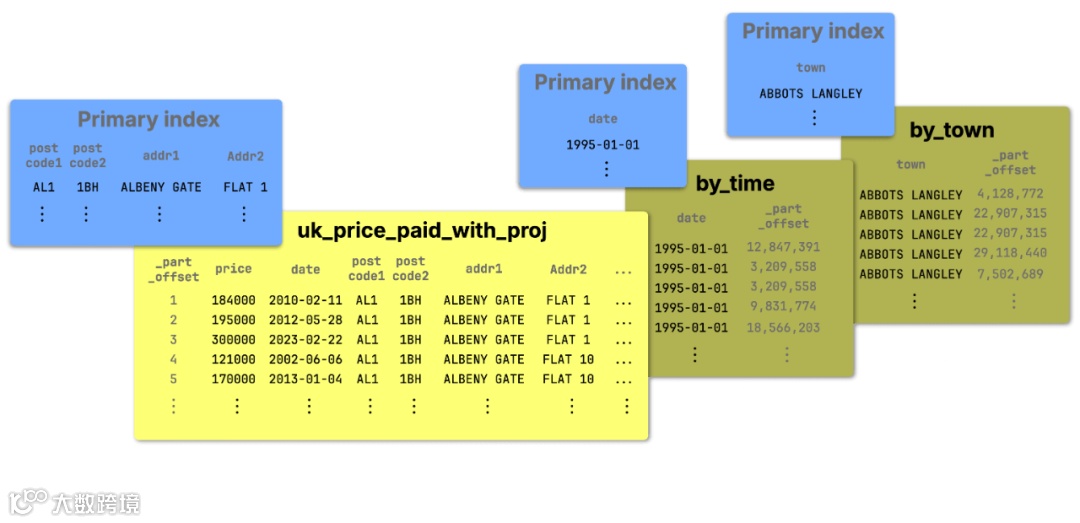
① 基础表按 (postcode1, postcode2, addr1, addr2) 排序,构成其主索引,使得基于这些字段过滤的查询效率极高。
② by_time 和 ③ by_town 投影只存储各自的排序键和 _part_offset 指针,指向基础表中对应的数据,避免重复存储。它们的主索引可作为辅助索引参与过滤操作,从而加快按日期或城市字段过滤的查询。
我们在 AWS EC2 m6i.8xlarge 实例(32 核心,128 GB 内存)上进行测试,使用 gp3 EBS(16K IOPS,最大吞吐 1000 MiB/s)作为存储。
本次查询将对 date 和 town 两列进行过滤。需要注意的是,这两列并不属于基础表的主索引。
我们首先在关闭投影支持的情况下运行该查询,以获取基准性能数据。同时,我们关闭了查询条件缓存和 PREWHERE,以确保仅观察索引对数据裁剪的影响:
SELECT *FROM uk.uk_price_paid_with_projWHERE (date = '2008-09-26') AND (town = 'BARNARD CASTLE')FORMAT NullSETTINGSuse_query_condition_cache = 0,optimize_move_to_prewhere = 0,optimize_use_projections= 0;
三次测试中最快一次耗时 0.077 秒:
0 rows in set. Elapsed: 0.084 sec. Processed 30.73 million rows, 1.29 GB (363.92 million rows/s., 15.26 GB/s.)Peak memory usage: 129.07 MiB.0 rows in set. Elapsed: 0.076 sec. Processed 30.73 million rows, 1.29 GB (406.96 million rows/s., 17.07 GB/s.)Peak memory usage: 129.29 MiB.0 rows in set. Elapsed: 0.077 sec. Processed 30.73 million rows, 1.29 GB (398.51 million rows/s., 16.71 GB/s.)Peak memory usage: 129.27 MiB.
该查询为全表扫描,读取了约 3000 万行数据。
随后启用投影支持再次执行相同查询:
SELECT *FROM uk.uk_price_paid_with_projWHERE (date = '2008-09-26') AND (town = 'BARNARD CASTLE')FORMAT NullSETTINGSuse_query_condition_cache = 0,optimize_move_to_prewhere = 0,optimize_use_projections= 1; -- default value
最快运行耗时 0.010 秒:
0 rows in set. Elapsed: 0.010 sec. Processed 16.38 thousand rows, 644.86 KB (1.60 million rows/s., 63.06 MB/s.)Peak memory usage: 4.89 MiB.0 rows in set. Elapsed: 0.010 sec. Processed 16.38 thousand rows, 644.86 KB (1.69 million rows/s., 66.36 MB/s.)Peak memory usage: 4.88 MiB.0 rows in set. Elapsed: 0.011 sec. Processed 16.38 thousand rows, 644.86 KB (1.54 million rows/s., 60.57 MB/s.)Peak memory usage: 4.89 MiB.
结果显示:0.077 秒对比 0.010 秒 —— 性能提升近 90%。
此外,本次仅扫描了约 1.6 万行,而非之前的全部 3000 万行。
通过 EXPLAIN 我们可以验证 ClickHouse 使用了两个投影的主索引作为辅助索引,对基础表 granule 进行了裁剪:
EXPLAIN projections = 1SELECT *FROM uk.uk_price_paid_with_projWHERE (date = '2008-09-26') AND (town = 'BARNARD CASTLE')SETTINGSuse_query_condition_cache = 0,optimize_move_to_prewhere = 0,optimize_use_projections= 1; -- default value
┌─explain────────────────────────────────────────────────────────────┐1. │ Expression ((Project names + Projection)) │2. │ Filter ((WHERE + Change column names to column identifiers)) │3. │ ReadFromMergeTree (uk.uk_price_paid_with_proj) │4. │ Projections: │5. │ Name: by_time │6. │ Description: Projection has been analyzed... │7. │ Condition: (date in [14148, 14148]) │8. │ Search Algorithm: binary search │9. │ Parts: 5 │10. │ Marks: 7 │11. │ Ranges: 5 │12. │ Rows: 57344 │13. │ Filtered Parts: 0 │14. │ Name: by_town │15. │ Description: Projection has been analyzed... │16. │ Condition: (town in ['BARNARD CASTLE', 'BARNARD CASTLE']) │17. │ Search Algorithm: binary search │18. │ Parts: 5 │19. │ Marks: 5 │20. │ Ranges: 5 │21. │ Rows: 40960 │22. │ Filtered Parts: 0 │└────────────────────────────────────────────────────────────────────┘
在 EXPLAIN 的第 10 行中,by_time 投影(通过其主索引)首先将扫描范围缩小至 7 个 granule。每个 granule 包含 8192 行,合计需扫描 7 × 8192 = 57,344 行(如第 12 行所示)。这些 granule 分布于 5 个数据 part 中(第 9 行),因此需读取 5 个对应的数据范围(第 11 行)。
随后从第 14 行起,by_town 投影的主索引被进一步应用,从先前选出的 7 个 granule 中排除 2 个。最终引擎仅需扫描 5 个 granule,分布于基础表的 5 个 part 中,这些 granule 可能包含满足时间与城市双重过滤条件的行。
为支持该优化,ClickHouse 新增了两个参数:
max_projection_rows_to_use_projection_index:如果预估读取投影的行数不超过该值,则启用投影索引。
min_table_rows_to_use_projection_index:如果预估读取基础表的行数不小于该值,则考虑使用投影索引。
曾经,ClickHouse 的每张表只能有一个主索引。
现在,它可以拥有多个“类主索引”,每个都可在查询中充当辅助索引。当查询包含多个过滤条件时,ClickHouse 会充分利用所有可用的索引,为你带来更快的查询性能。

贡献者:Nihal Z. Miaji
本次版本新增了另一项基于投影的优化功能。
正如前文所述,投影是 ClickHouse 自动维护的、以不同排序方式(或预聚合布局)存储的隐藏表副本,旨在加速能够从特定数据组织中获益的查询。
当查询执行时,ClickHouse 会自动选择最具成本优势的数据路径,无论是读取基础表还是投影,以尽可能减少扫描的数据量。
从本版本开始,这一机制也可用于加速 DISTINCT 查询:如果读取唯一值时,从投影中读取的行数更少,ClickHouse 将自动使用投影作为数据来源。
一种常见的优化方式,是为包含 DISTINCT 字段的查询创建一个以该字段为 GROUP BY 键的预聚合投影。这样,投影虽然行数远少于原始表,但仍包含所有唯一值,因此非常适合用作 DISTINCT 查询的高效数据源。
为演示这一优化,我们再次使用英国房产成交数据集,这次我们在表中定义了一个名为 sales 的投影:
CREATE TABLE uk.uk_price_paid_with_sales_proj(price UInt32,date Date,postcode1 LowCardinality(String),postcode2 LowCardinality(String),type Enum8('terraced' = 1, 'semi-detached' = 2, 'detached' = 3, 'flat' = 4, 'other' = 0),is_new UInt8,duration Enum8('freehold' = 1, 'leasehold' = 2, 'unknown' = 0),addr1 String,addr2 String,street LowCardinality(String),locality LowCardinality(String),town LowCardinality(String),district LowCardinality(String),county LowCardinality(String),PROJECTION sales (SELECT count(), sum(price), avg(price)GROUP BY county, town, district))ENGINE = MergeTreeORDER BY (postcode1, postcode2, addr1, addr2);
随后我们按照文档说明加载了数据。
这个投影本身并不是专门为 DISTINCT 查询设计的,性能提升只是一个额外收获。其最初的设计目的是支持诸如统计英国热门区域或高价值地区等查询。
对于 DISTINCT 加速而言,投影的 SELECT 子句内容并不重要;关键是去重字段包含在投影的 GROUP BY 中即可。
需要注意的是,GROUP BY 中的字段即使未出现在投影的 SELECT 子句中,也依然会作为排序键存在,并自动构建主索引用于高效过滤。在查询中依然可以选取这些字段:
SELECTtype,sorting_keyFROM system.projectionsWHERE (database = 'uk') AND (`table` = 'uk_price_paid_with_sales_proj') AND (name = 'sales');
┌─type──────┬─sorting_key──────────────────┐1. │ Aggregate │ ['county','town','district'] │└───────────┴──────────────────────────────┘
因此,像 county、town 和 district 等字段的所有唯一值都已被包含在投影表中,但行数远远少于基础表:
SELECT sum(rows)FROM system.projection_partsWHERE (database = 'uk') AND (`table` = 'uk_price_paid_with_sales_proj') AND (name = 'sales') AND active;
┌─sum(rows)─┐1. │ 9761 │└───────────┘
而随着后台的 part 合并操作持续执行,这些投影中的行数还会逐步减少。
对应的基础表包含超过 3000 万行数据:
SELECT count() from uk.uk_price_paid_with_sales_proj;┌──count()─┐1. │ 30729146 │ -- 30.73 million└──────────┘
我们在 AWS EC2 的 m6i.8xlarge 实例(32 核,128 GB 内存)上进行以下查询的基准测试,存储使用的是 gp3 类型的 EBS(16K IOPS,最大吞吐 1000 MiB/s)。
首先,我们在禁用投影功能的情况下,对 town 列执行 DISTINCT 查询:
SELECT DISTINCT townFROM uk.uk_price_paid_with_sales_projSETTINGSoptimize_use_projections = 0;
三次运行中最快一次耗时为 0.062 秒:
1173 rows in set. Elapsed: 0.062 sec. Processed 30.73 million rows, 61.46 MB (494.48 million rows/s., 988.97 MB/s.)Peak memory usage: 2.11 MiB.1173 rows in set. Elapsed: 0.064 sec. Processed 30.73 million rows, 61.46 MB (483.01 million rows/s., 966.02 MB/s.)Peak memory usage: 1.51 MiB.1173 rows in set. Elapsed: 0.063 sec. Processed 30.73 million rows, 61.46 MB (487.14 million rows/s., 974.28 MB/s.)Peak memory usage: 1.20 MiB.
这是一场完整的全表扫描,处理了全部约 3000 万行数据。
接着我们启用投影功能,运行相同的查询:
SELECT DISTINCT townFROM uk.uk_price_paid_with_sales_projSETTINGSoptimize_use_projections = 1; -- the default value
1173 rows in set. Elapsed: 0.003 sec. Processed 9.76 thousand rows, 59.46 KB (3.29 million rows/s., 20.05 MB/s.)Peak memory usage: 472.22 KiB.1173 rows in set. Elapsed: 0.003 sec. Processed 9.76 thousand rows, 59.46 KB (3.29 million rows/s., 20.01 MB/s.)Peak memory usage: 472.22 KiB.1173 rows in set. Elapsed: 0.003 sec. Processed 9.76 thousand rows, 59.46 KB (3.37 million rows/s., 20.54 MB/s.)Peak memory usage: 472.22 KiB.
最快运行耗时仅为 0.003 秒 —— 性能提升约 96%。
这一次,ClickHouse 并没有扫描基础表中全部 3000 万行数据来找出唯一的 town 值,而是只读取了 9760 行投影数据,因为这个路径的数据量显著更小。这正是投影的优势所在:ClickHouse 会自动选择更高效、更具性价比的数据来源。

贡献者:AbdAlRahman Gad
在 ClickHouse 25.11 中,新增了两个聚合函数:argAndMax 和 argAndMin。我们仍然以英国房产价格数据集为例来展示它们的用法。
假设我们希望查询 2025 年售价最高的房产,可以写出如下 SQL:
SELECT max(price)FROM uk_price_paidWHERE toYear(date) = 2025;
┌─max(price)─┐│ 127700000 │ -- 127.70 million└────────────┘
但如果我们还想知道这套房产所在的城市(town),可以使用 argMax 函数来实现:
SELECT argMax(town, price)FROM uk_price_paidWHERE toYear(date) = 2025;
┌─argMax(town, price)─┐│ PURFLEET-ON-THAMES │└─────────────────────┘
现在,通过 argAndMax 函数,我们可以一次性获取城市以及对应的最高价格:
SELECT argAndMax(town, price)FROM uk_price_paidWHERE toYear(date) = 2025;
┌─argAndMax(town, price)───────────┐│ ('PURFLEET-ON-THAMES',127700000) │└──────────────────────────────────┘
同理,使用 argAndMin 函数可以查出价格最低的房产及其所在城市:
SELECT argAndMin(town, price)FROM uk_price_paidWHERE toYear(date) = 2025;
┌─argAndMin(town, price)─┐│ ('CAMBRIDGE',100) │└────────────────────────┘
这个最低价似乎有些异常 —— 2025 年居然有房产以 100 英镑售出,这显然不太可能,可能是数据质量问题。

贡献者:Ahmed Gouda
ClickHouse 25.11 还支持了 LIMIT 和 OFFSET 的小数形式(fractional limit / offset)。继续使用房产价格数据集,下面这个查询通过将 limit 设置为 0.1,可以获取平均房价排名前 10% 的县(county):
SELECT county, round(avg(price), 0) AS priceFROM uk_price_paidGROUP BY countyORDER BY price DESCLIMIT 0.1;
┌─county──────────────────────────────┬──price─┐│ GREATER LONDON │ 431459 ││ WINDSOR AND MAIDENHEAD │ 427476 ││ WEST NORTHAMPTONSHIRE │ 417312 ││ BOURNEMOUTH, CHRISTCHURCH AND POOLE │ 403415 ││ SURREY │ 386667 ││ BUCKINGHAMSHIRE │ 349638 ││ CENTRAL BEDFORDSHIRE │ 343227 ││ NORTH NORTHAMPTONSHIRE │ 338155 ││ WOKINGHAM │ 332415 ││ WEST BERKSHIRE │ 326481 ││ BEDFORD │ 318778 ││ OXFORDSHIRE │ 317245 ││ HERTFORDSHIRE │ 317055 ││ BATH AND NORTH EAST SOMERSET │ 304950 │└─────────────────────────────────────┴────────┘
此外,我们还可以设置小数形式的 offset。例如,如果我们希望从列表中间开始,选取 10 个县(按平均房价排序),只需设置 offset 为 0.5 即可:
SELECT county, round(avg(price), 0) AS priceFROM uk_price_paidGROUP BY countyORDER BY price DESCLIMIT 10OFFSET 0.5;
┌─county───────────────────┬──price─┐│ TORBAY │ 170050 ││ CITY OF NOTTINGHAM │ 169037 ││ PEMBROKESHIRE │ 167116 ││ WEST MIDLANDS │ 166271 ││ LUTON │ 165885 ││ NORTHUMBERLAND │ 164153 ││ NORTHAMPTONSHIRE │ 164133 ││ EAST RIDING OF YORKSHIRE │ 163334 ││ ISLE OF ANGLESEY │ 162621 ││ DERBYSHIRE │ 161320 │└──────────────────────────┴────────┘

贡献者:Shankar
ClickHouse 25.11 新增了 EXECUTE AS
这一功能非常适合于以下场景:应用程序以某个用户身份登录系统,但在实际操作中需要以其他配置用户的权限来执行任务,以满足访问控制、资源限制、参数设置、配额管理以及审计合规等要求。
我们可以通过如下命令,将代理执行权限授权给指定用户:
GRANT IMPERSONATE ON user1 TO user2;之后,便可通过以下方式,代表其他用户执行单条查询:
EXECUTE AS target_userSELECT * FROM table;
也可以为当前会话设置代理用户身份:
EXECUTE AS target_user;此后,该会话中的所有查询都将以 target_user 的身份运行。

好消息:ClickHouse Xi'an User Group第 1 届 Meetup 火热报名中,将于2025年12月20日在西安高新区海星城市广场B座27楼2706 云尚书苑 举行,扫码免费报名


/END/
试用阿里云 ClickHouse企业版
轻松节省30%云资源成本?阿里云数据库ClickHouse 云原生架构全新升级,首次购买ClickHouse企业版计算和存储资源组合,首月消费不超过99.58元(包含最大16CCU+450G OSS用量)了解详情:https://t.aliyun.com/Kz5Z0q9G


征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

