
如果从 1965 年的达特矛斯会议开始算起,AI 已经走过了 65 年的历程。近些年,随着深度学习兴起,AI 也获取了越来越多的关注。目前,AI 技术都是以深度学习为基础,而深度学习想要完成复杂的学习过程需要完成两个过程:
大量的数据训练,深度学习极度依赖数据挖掘技术,消耗产生大量、有效的训练数据;
优化算法,深度学习需要通过复杂的神经网络找到最好的模型,用于分析新的数据。

数据处理阶段结构
故而深度学习对数据要求比普通模型的要求都要高。只有在大量数据的支持下,才能真正发挥深度学习的作用。然而,大数据比想象中都要复杂,训练数据的难度比传统机器学习的难度要大。而在整个数据处理过程中,不同阶段所使用的技术,以及这些技术对数据访问的要求都有差别。
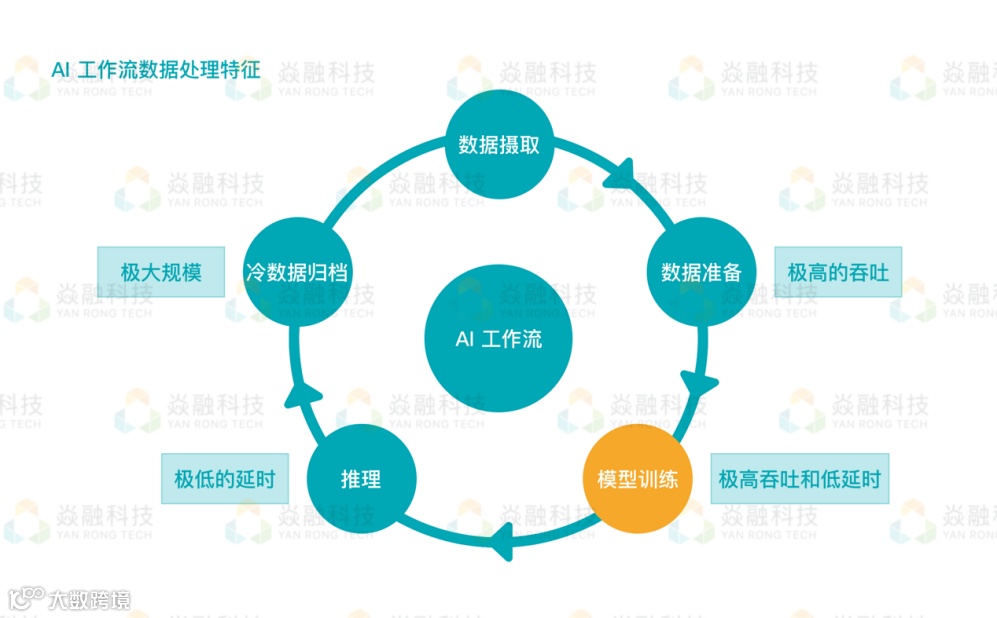
数据在各阶段访问的特点
作为一家专注以软件定义存储技术的企业,耀途投资组合焱融科技自 YRCloudFile 发布以来,长期关注存储技术在 AI 领域方面的应用,也亲历了近年数据存储在 AI 领域的落地过程。本篇文章,焱融科技将试图通过国内某家在语音及语言、自然语言理解、机器学习推理及自主学习等领域保持着国际前沿技术水平的 AI 领域企业的实际案例,带领大家了解当前数据存储在 AI 领域的技术发展现状,以及探索 AI 未来的发展情况。
海量数据亟需解决的“硬骨头”
目前,国内某 AI 领域企业的基础架构团队,需要为各个人工智能团队及业务部门提供稳定、高性能的训练存储平台,同时管理近千台高性能 GPU 服务器,如果训练使用存储平台性能滞后,将直接影响业务部门的训练效率。因此,数据处理流程是整个环节的重中之重,也是焱融科技本次优化训练平台的切入点。
为了满足该公司的人工智能业务部门训练的需要,其应用的模型训练数据平台必须具备以下特性:
具备高带宽、低延时的读写特性,保证为 GPU 服务器提供足够的数据输入,实现 GPU 的高效使用;
支持百亿级别的小文件及部分大文件混合的读写场景,满足大量特征文件或聚合后的文件存储需求;
上层训练模型使用标准文件接口访问数据;
能支持近千个高性能计算节点的并发访问;
满足多种计算集群模式存储服务,包括固有的裸金属计算架构、云计算架构、容器化计算架构的持久化存储等需求;
满足综合监控数据治理平台对接需求,实现数据管理、监控、运维一体化展现和简约化治理能力;
实现相关业务特征具体优化策略,根据不同业务类型特征具备可调节优化能力。
YRCloudFile 做对了什么?
在了解该公司的需求以后,焱融开始从 2019 年开始,就技术应用方案和落地措施进行了多次的交流和实际场景测试。同时,该公司的技术团队对训练使用的存储平台选型非常重视,其中数据平台的实际性能尤为关键,包括:
-
大文件的随机读写、小文件的读写性能; -
海量元数据的操作性能(creation, stat, removal 等); -
海量文件的支持,以及在海量文件的背景下,数据访问和操作性能是否保持一致; -
存储平台的稳定性; -
在故障场景中,尤其是在元数据服务故障场景下,集群性能的稳定性; -
与容器平台的对接能力; -
数据生命周期的管理。

-
强大的云原生存储能力。YRCloudFile 支持容器跨节点重建、PVC Quota、PVC扩容、PVC QoS、热点分析等特性,帮助其在云原生服务能力进一步增长的情况下,实现更多新业务以云原生的方式部署,实现敏捷开发能力和 AI 快速迭代。
-
高性能、高可靠性、完整的界面管理和向上对接能力。目前,YRCloudFile 在可靠性保障基础上,提供了节点级抗灾能力,并在容器对接层通过跨节点重建,满足故障后快速恢复应用的要求。另外,YRCloudFile 在混合文件优化上,采用了并行数据管理能力,将元数据和实体数据分离模式,在保障海量文件的高速访问和扩展能力的同时,实现了根据不同数据特征调节元数据性能的微调能力,并基于此强大的产品特性,在存储集群的扩展管理和面对业务优化上具备巨大的优势。
-
更了解业务。YRCloudFile 通过长期的生产时间,使得其更加了解公司业务,释放了更加贴合业务场景需求的 SDK,实现更加细致的文件共享服务,比如提供更加细致的权限管理,满足对接业务权限平台、资源均衡能力、业务感知能力、数据治理需求对接能力的要求等。
-
最大化实现高性能访问,保障业务高效迭代。在数据生命周期的管理中,YRCloudFile 通过训练热数据可实现三层架构,实现最大化高性能访问,在保障业务高效迭代的同时,YRCloudFile 还可以通过存储集群本身的两层数据流转模式,实现热数据前置,将训练数据贴近计算,使依赖高性能网络的分布式存储更进一步。除此之外,YRCloudFile 还可以将热数据层与计算总线直接打通,从而获得更高的 IOPS 和更低的时延,且热数据全程在 YRCloudFile 统一命名空间管理,摆脱计算系统低效的置换策略,使其提升了 YRCloudFile 在智能置换和预读方面的能力,在原有 YRCloudFile 存储性能的基础上,再提升 5 倍左右的性能。
-
无缝对接对象存储。针对热数据归档冷数据管理的问题,焱融开发了对象管理功能,实现无缝对接对象存储。再通过 YRCloudFile 命名空间统一管理的方式,达到策略式归档的目的。而在上层应用则表现为透明管理,满足细粒度调取的需求,最大化地帮助用户降低存储支出费用。同时,搭配焱融公有云产品云舟服务可形成混合云存储管理模式,实现轻松多地、多站点部署模式,极大地扩展了客户业务群,丰富了 IT 管理手段。

-
支持更加丰富的业务计算模式,其中包括高性能HPC集群、云计算集群、容器计算集群,能够满足多项业务共同开展; -
高可靠业务支撑,在保障业务能够按照预期顺利交付的同时,提升IT基础设施安全性,有效提升整体业务水平; -
全生命周期管理业务数据,实现热数据层更加高效的访问,冷数据管理更加智能,有效降低 IT 的 TCO; -
训练时间大幅缩短,相对于其它的商业存储,YRCloudFile 所具备的高带宽、低延时的特性,更能满足 GPU 等计算服务器的计算效率达到饱和的需求,使得单次训练时间由一周缩短至数小时; -
训练精度提升,在深度学习过程中,算法工程师需要通过不断调整训练模型,才能提升模型精准度,故而缩短单次训练时间,提升迭代频次的关键。借助 YRCloudFile,算法工程师可以通过调整深度学习中的参数,不断优化深度学习的成本函数(Cost Function),使模型迭代频次提高、训练精准度提升成为可能; -
协助客户完成数据治理工作,YRCloudFile 向上提供更加丰富的数据管理接口,可以帮助企业集中管理平台的搭建和运维管理,提升运维效率,解放生产力。

推荐阅读
一年收获9家硬科技独角兽,批量复制的秘密是什么?
都在挤破头投硬科技,成立仅五年VC何以差异化突围?
白宗义:芯片投资,新技术新功能的增量市场更具爆发性
硬科技投资从小众到群雄逐鹿,如何构建投资壁垒?
杨光:芯片是抓住新基建机遇的最小单元
