
我们为神马做数据抓取?
困扰我们的不是信息匮乏,而是信息提取!

在当今互联网络时代,信息如同大海般没有边际,各行各业以前所未有的速度生产着大量的丰富的数据信息。我们获取信息的方法已经发生改变:从传统的翻书查字典,继而变成通过搜索引擎进行检索。
今天,困扰我们的问题不是信息匮乏,而是信息提取。因此,提供一个能够自动在互联网上抓取数据,并能自动分析存储的工具有非常重要的意义。
信息更新之快,我们该如何及时更新数据?
我们通过互联网网站上所获得的信息,通常是通过网页表格的形式所展现的,但计算机需要针对网页进行自动识别,分析数据的结构,去除网页的格式,以结构化的形式将数据提取并保存起来。
互联网网站上的信息随时可能更新,比如金融证券市场价格数据,数据的更新频率达到分钟、秒的级别。
数据提取无法通过人工方式操作, 我们需要能够定时计划执行的数据抓取工具。
i@Report5.1中的网络抓数利器
i@Report5.1作为通用的数据采集报表平台,内置了强大的数据抓取通用解决方案,帮助你在网络上抓取有价值的数据。
i@Report5.1数据抓取功能可以从指定的网页地址提取表格数据,分析数据结构并自动生成相应的报表任务,通过计划任务方式定期从网页中获取数据存储到该任务中。

这网络抓数利器该怎么用?
i@Report5.1数据抓取功能基于用户自定义的抓取方案。
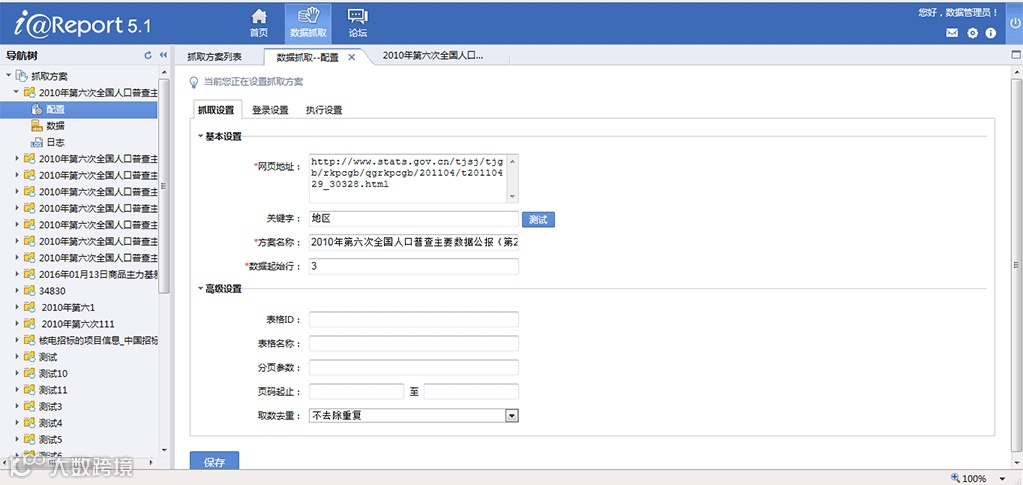
抓取方案新建的第一步配置要抓取的网页地址,根据关键字识别到有效的数据表格并显示出来,进而分析网页上的数据结构。这里的关键字指的是目标表格的表头文字、表格前面的文字用于协助定位表格。
配置好抓取地址和关键字之后,点击界面上的测试按钮,会根据默认的抓取规则,从目标地址中将匹配的表格标签中的内容抓取出来重新渲染, 不依赖于网页样式。

在网页上的表格无明显关键字或者有多个同样标题的表格时,可以考虑使用高级功能中设置表格的ID来定位表格。
一般而言,网页中的大量数据都是通过分页形式呈现的,高级功能中支持使用分页参数设置获取目标站点的多页数据抓取,甚至可以配置从第几页抓取到第几页,以及对于抓取到的重复数据如何处理等等。
有的网页站点需要用户登录后才能进行访问网页,比如在i中抓取BI中的数据,这种情况咋么办?
不要紧,数据抓取方案中还支持登录设置!您可以配置登录要使用的用户名密码等信息到抓取方案中,抓取时系统会帮您自动登录。

完成这些以后,我们可以通过配置抓取频率将抓取方案作为计划任务定期执行,这样您就完全不用值守在电脑旁苦巴巴的等着网站更新数据了,到了您设置的时间点系统会自动完成抓取任务的。
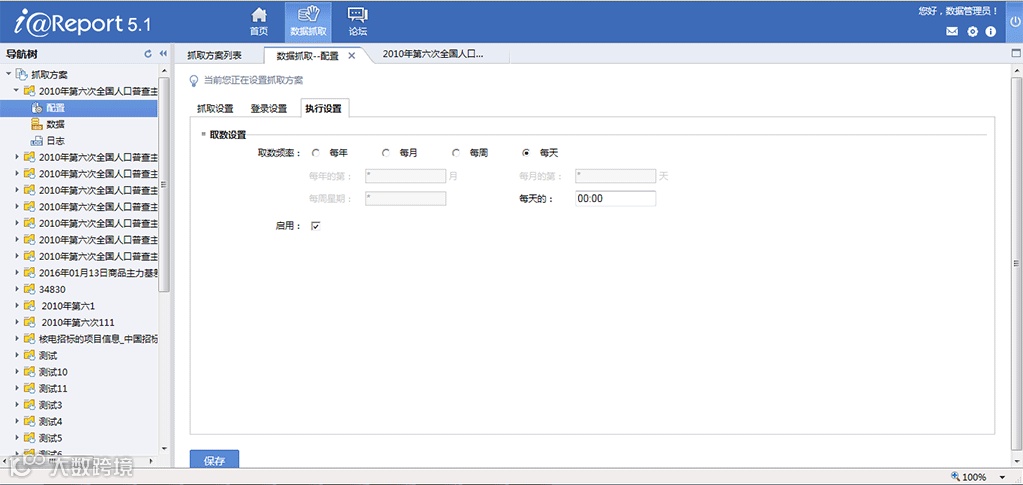
好了,到这里数据抓取方案就配置完成了,保存以后您就可以高枕无忧了。说不准在您一边看着新闻一边喝着咖啡的时候,网站刚刚发布的新数据已经跑进了您的数据库!
