
大家在消费时经常使用到信用卡,为什么消费额度会因人而异?其实个人在申请信用卡贷款时,银行会综合申请人各项因素评估用户信贷风险及偿还能力,计算出贷款额度。
在金融行业中,银行贷款业务是很常见的业务,也是重要的盈利业务之一,同时它也存在相当大的风险。贷款用户不能正常还贷、抵押不能变现、质押不能变现、担保无效等情况评估错误,可能会造成银行收贷困难,资金流通障碍。
如何对贷款用户进行系统的风险分析,准确地识别出信用好、风险低的贷款用户,最大化地降低银行的贷款风险呢,是各大银行一直在寻找的秘方。

亿信豌豆DM可根据客户的年龄、教育程度、收入、信用卡贷款数量、贷款额预收入之比、其余手段贷款数量等因素,对客户贷款风险进行评估。
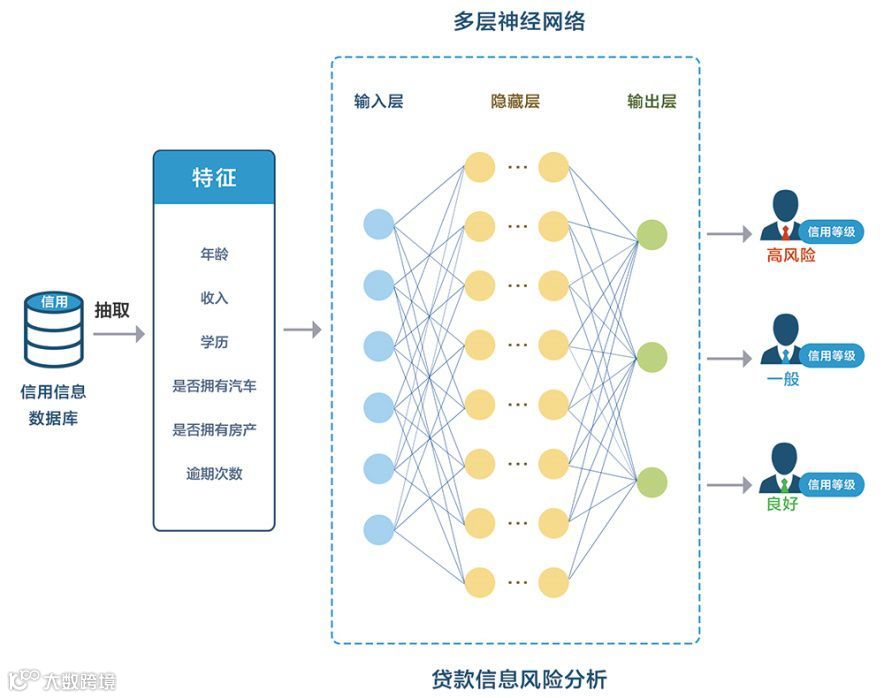
下图为某银行已知是否贷款存在风险的贷款客户的数据信息,共有850条数据,其中与贷款客户是否存在风险的相关因素有:
AGE(客户年龄)
ED(客户教育程度)
EMPLOY(客户工作)
ADDRESS(客户驻地时间)
INCOME(客户工作收入)
DEBTINC(客户贷款额与收入之比)
CREDDEBT(客户信用卡贷款数量)
OTHDEBT(客户其余手段贷款数量)
DEFAULLT((是否存在风险),DEFAULT=1,表示存在风险;DEFAULT=0,表示不存在风险。

豌豆DM是如何从银行贷款数据集中分析评估贷款用户是否存在风险的呢?通过以下几步来实现。

通过将上述银行贷款数据整理好,导出到我们的数据库中,生成数据库表,然后根据选择已有数据库表创建数据集。
对上面的数据集进行数据探索,查看数据是否含有缺失值,若含有缺失值,需要将数据集进行数据预处理,反之,则表示数据集完整性较好,不需要进行数据预处理。
通过数据探索我们可以看出,其中显示的缺失值均为零,表明该数据集完备性较好,不需要进行数据预处理。

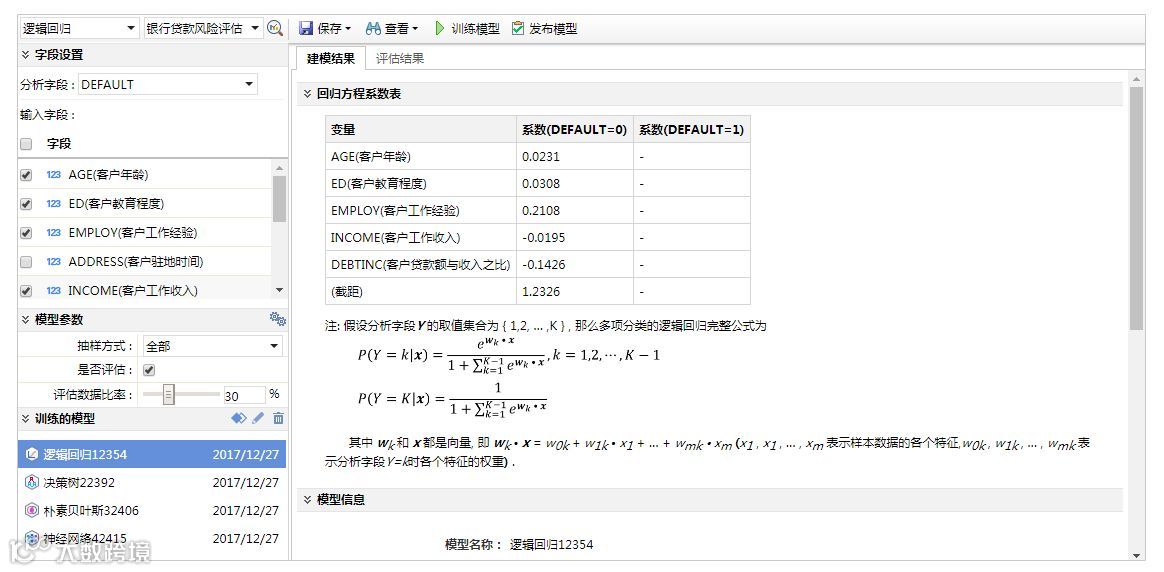
通过这份比较完备的数据集,我们可以开始创建分类挖掘过程,可选择 “决策树”、“神经网络”、“朴素贝叶斯”、“逻辑回归”等一系列的分类算法分别训练出模型。
分析字段为DEFAULT(是否存在风险),输入字段选取了数据集中的5个字段:
AGE(客户年龄)
ED(客户教育程度)
EMPLOY(客户工作)
INCOME(客户工作收入)
DEBTINC(客户贷款额与收入之比)
抽取全部数据训练模型,用其中30%的数据作为评估数据,运用模型进行评估,得出评估结果,对比查看各算法得出的评估结果的准确率,准确率最高的为最优模型,并发布到模型库。
评估结果中显示该模型的预测正确率为79.17%,使用该模型的平均提升率为149.71%,并且对分析字段DEFAULT(是否存在风险)取值为0的类别有最高的识别准确率为80.75%。

通过新建模型应用,用我们训练出来的最优模型对被预测数据进行预测评估,下图为新建银行贷款风险评估应用,只需将银行贷款风险评估模型拖拽到编辑区,当有新的客户需要判断他是否为风险客户时,可以通过模型应用来评估出其是否有风险。

模型应用会以统计图和表格的形式,展现所需要预测的贷款用户的风险评估结果,表格中的预测值字段可查看每个贷款用户的预测结果和预测概率,当数据量较大时,我们可以添加参数来筛选查询范围,如:输入客户的年龄阶段,可查询该年龄段的贷款用户的风险评估预测。
下图为某商业银行贷款部门,根据客户的年龄、教育程度、工作经验、收入、贷款额与收入之比等因素对未知风险的贷款客户信息数据集进行预测的预测结果,1代表存在风险,0代表不存在风险,对应的预测概率越高,代表预测结果越准确。

通过灵活的风险评估模型,科学严谨的评测,可快速评估业务风险,帮助提升银行机构整体风控能力,减少资金损失和品牌损失。
