

数据湖或hub的概念最初是由大数据厂商提出的,表面上看,数据都是承载在基于可向外扩展的HDFS廉价存储硬件之上的。但数据量越大,越需要各种不同种类的存储。最终,所有企业数据都可以被认为是大数据,但并不是所有的企业数据都是适合存放在廉价的HDFS集群之上的。

数据湖应该是一种不断演进中、可扩展的大数据存储、处理、分析的基础设施;以数据为导向,实现任意来源、任意速度、任意规模、任意类型数据的全量获取、全量存储、多模式处理与全生命周期管理;并通过与各类外部异构数据源的交互集成,支持各类企业级应用。

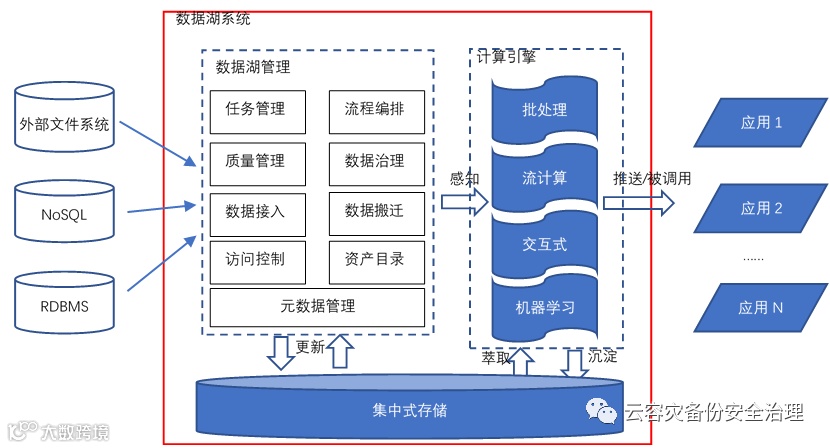
数据湖组件参考架构
记住以下4个特点:
1:存储原始数据,来源非常丰富,结构和非结构化
2:支持多种计算模型
3:完善的数据管理能力:多种数据源接入,实现不同数据之间的连接,支持 schema 管理和权限管理
4:灵活的底层存储,一般用 ds3、oss、hdfs 这种廉价的分布式文件系统


数据湖中的数据生命周期示意

