

Lustre定义
Lustre是一个开源、分布式并行文件系统软件平台,具有高可扩展、高性能、高可用等特点。
Lustre的构造目标是为大规模计算系统提供一个全局一致的POSIX兼容的命名空间,这些计算系统包括了世界上包含最强大的高性能计算系统。它支持数百PB数据存储空间,支持数百GB/s乃至数TB/s并发聚合带宽。
Lustre*是一个开源的、全局单个命名空间的、符合POSIX标准的分布式并行文件系统,旨在实现系统的可扩展性、高性能和高可用性。Lustre在基于Linux的操作系统上运行,并采用客户端-服务器模式的网络架构。Lustre的存储由一组服务器提供,这些服务器可以扩展到多达数百台的数量。运行着单个文件系统实例的Lustre服务器总共可以向数千个计算客户端提供高达几十PB的存储容量,总吞吐量超过1TB/s。
Lustre是一个文件系统,可扩展以满足从小型HPC环境到超级计算机等不同规模的系统上运行的各种应用程序的需求,而且Lustre是使用基于对象的存储构建块创建的,这样可以最大限度地提高系统扩展性。
当元数据和数据存储在独立的服务器上时,冗余服务器可以支持存储故障转移功能,这样每个文件系统可以针对不同的工作负载进行优化。Lustre可以通过高速网络结构(如英特尔全路径架构( OPA )、InfiniBand*和以太网)向应用程序提供快速的IO。
Lustre架构

Lustre 扩展性
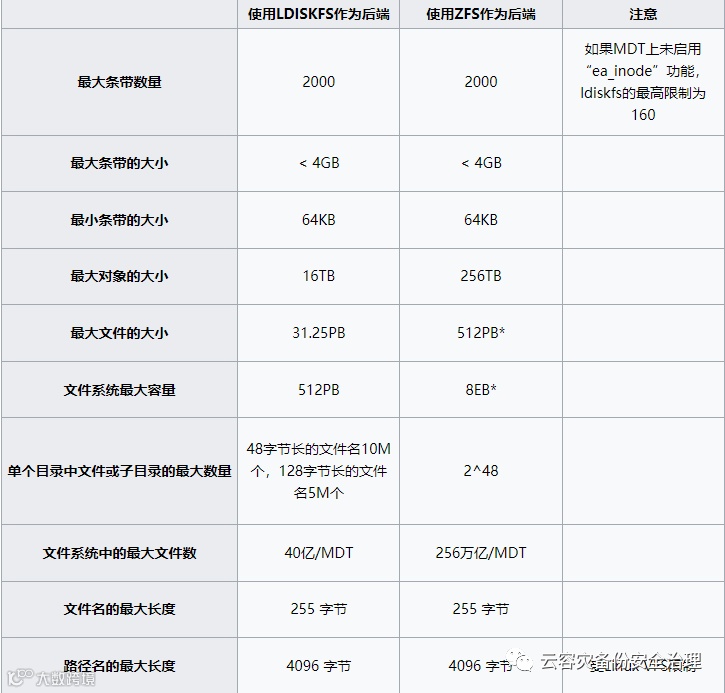
* 理论值
高可用性与数据存储可靠性
Lustre存储
如果一个组织想要获得成功,必须确保其IT基础设施资源的可靠性和可用性。对于做存储系统的组织来说,这意味着用户必须确信他们的数据被持久地、可靠地存储,信息不会被丢失或损坏,并且数据一旦被存储,就可以根据应用程序的要求被重新调用。
Lustre旨在满足世界上最大的超级计算机上运行的应用程序对数据最密集的工作负载的需求。任何引入到这些环境中的开销都会降低应用程序的可用带宽、降低整体效率,反过来又会增加获得结果所需的时间。因此,Lustre文件系统体系结构没有为存储服务器上的数据对象实现冗余存储模式,这是由于复制和其他数据冗余机制都将引入其固有的延迟和带宽开销。
数据可靠性是在存储子系统中实现的。在存储子系统中,数据可靠性可以在很大程度上与用户应用程序级的I/O和通信隔离开来。这些存储系统通常由多端口机架组成,每个机架包含磁盘阵列或其他持久化存储设备。阵列可以是带有专用控制器的智能数据存储系统,也可以是没有专用控制软件的简单托盘(通常称为JBODs,“磁盘簇”)。
智能存储阵列的优点是通过RAID配置,降低了服务器上管理存储冗余的复杂性,并减少了计算校验和与奇偶校验的开销。专用存储控制器通常配有带电池后备电源的高速缓存,用于缓存数据,从而进一步将与写入附加数据块相关联的IO开销和主机上运行的存储服务隔离开来(如在RAID 6或RAID 10设备中的布局)。
JBOD存储模式比智能存储阵列(通常称为“硬件RAID阵列”)更简单,成本更低。但这种低成本的好处被主机服务器操作系统中更复杂的软件配置所抵消了,因为所有数据管理任务,包括冗余布局配置,都必须由主机执行和监控。Linux内核的存储卷管理标准工具(MDRAID和LVM)为管理JBOD存储提供了基本工具,并允许定义复杂的容错磁盘布局。定义块布局后,可以在软件卷的顶部格式化文件系统。
LVM和MDRAID虽然流行,但有些复杂,在大规模存储平台上难以进行有效的管理。然而近年来,JBOD体系结构由于高级的文件系统技术的发展而受到了极大的欢迎,OpenZFS就是一个例子,它使存储管理变得更容易,同时还提高了可靠性和数据完整性。自从Sun Microsystems公司 (现在被Oracle Solaris 收购)最初将OpenZFS引入Solaris操作系统以来,OpenZFS打破了许多关于存储管理和“软件RAID”的假设。
OpenZFS文件系统将文件系统和存储管理当作整体看待,从而降低了维护基于软件的存储的管理复杂性。ZFS将卷管理功能与高级文件系统集成在一起,该文件系统可高效地扩展并添加一些增强功能,包括端到端校验和以防止数据损坏、存储配置的多样性、在线数据完整性验证,以及无需执行离线修复的写入时复制体系架构。此外,ZFS中没有文件系统校验(fsck)。
基于软件的存储架构的发展也影响着存储硬件的设计,创造出了混合服务器和存储机架,将存储托盘和标准服务器组合成一个高密度机架。这些集成系统可以提供更高的机架密度和更少的物理集成复杂度(包括减少布线)。
针对Lusre服务连续性的高可用性
Lustre服务器负责处理运行在计算机网络上的应用程序的I/O请求,并管理用于维护数据持久化记录的块存储。Lustre客户端不直接与数据块存储连接,通常是完全无盘的,即没有本地数据持久化单元。因为Lustre服务器之间不进行数据复制,所以不能访问服务器意味着不能访问该服务器上管理的数据,这反过来意味着Lustre文件系统管理的数据中的一部分将不可被客户端使用。
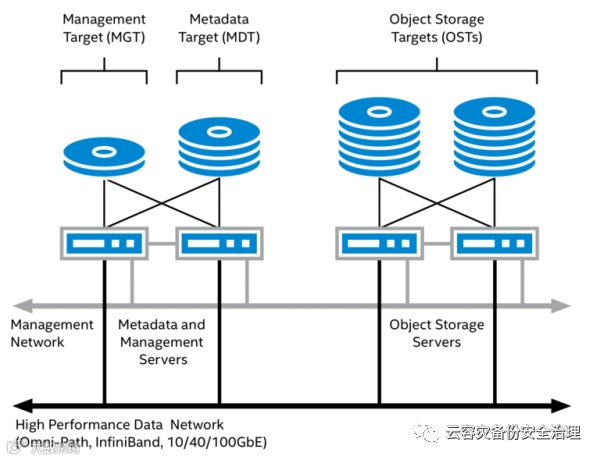
为了防止服务出现故障,Lustre数据通常保存在与两个或更多服务器相连的多端口的专用存储上。存储被细分为卷或LUN,每个LUN代表一个Lustre存储目标( MGT、MDT或OST )。连接到存储目标的每台服务器对存储目标具有同等的访问权限,并且可以被配置为将存储模块呈现给网络,尽管在任一给定时间,只允许一台服务器访问存储模块中的单个存储目标。Lustre使用节点间故障转移模型来保持服务的可用性,这意味着如果服务器出现故障,则故障服务器管理的任何Lustre存储目标都可以转移到连接到同一存储阵列的正常服务器上。
这种配置通常被称为高可用(HA)集群。单个Lustre文件系统安装将由几个这样的HA集群组成,每个集群提供一组独立的服务,这些服务是整个文件系统服务的子集。这些独立的HA集群是高可用的Lustre并行分布式文件系统的构建模块,可将文件系统扩展到数十PB的容量,并达到超过1tb/s的联合吞吐量。
构建块模式可能会有所不同,这反映了Lustre在设计高性能存储基础架构时,就考虑到要为集成商和管理员提供灵活性。最常见的模式是将两台服务器连接到共享存储上,形成一个双HA集群的拓扑结构。虽然HA集群中服务器的数量可以有所不同,但双节点配置提供了最大的整体灵活性,代表了能提供高可靠性的最少构建块。每个构建块都具有确定的容量和可测量的吞吐量,因此可以根据目标容量和目标吞吐量,来设计Lustre文件系统所需的构建块的数量。
高可用性与GNU / Linux
每个主要的企业级操作系统都提供了一个遵循这一基本模型的高可用性集群软件框架。在当前的GNU/Linux发行版中,事实上的HA集群框架已经整合了大约两个软件包:用于集群成员和通信的Corosync软件包和用于资源管理的Pacemaker软件包。
操作系统发行版都围绕这些软件包开发了自己的管理工具。例如,红帽子企业版Linux ( RHEL )使用了PCS (Pacemaker/Corosync配置系统),而SuSE Linux企业服务器( SLES )使用了CRMSH (Cluster Resource Management Shell,集群资源管理外壳)。PCS和CRMSH都是开源应用。还有许多其他可用的工具,包括基于web的应用HAWK,它与CRMSH有接口。PCS也有自己基于web的用户界面。