

捅破算力天花板!DeepGEMM让大模型训练成本直降50%
前 言
开源周第三日发布的DeepGEMM 是一个专为简洁高效的 FP8 通用矩阵乘法(GEMM)设计的库,具有细粒度缩放功能,如 DeepSeek-V3 中所提出。仅用300行代码,DeepGEMM就实现超越专家级优化的矩阵乘法,不仅在Hopper GPU上飙出1350 TFLOPS的惊人速度,还实现了教科书般简洁。

DeepGEMM是一个一个支持密集和MoE GEMM的FP8GEMM库,为V3/R1训练和推理提供支持。简单来说,这是一个专门给AI大模型「打鸡血」的计算工具包。就像快递分拣系统能让包裹更快送达,DeepGEMM能让GPU(图形处理器)的算力发挥到极限,尤其是训练和运行ChatGPT这类大模型时。
(图源新浪头条:品玩)
X上,DeepSeek展示其核心亮点包括:
Hopper GPU上最高可达1350+ FP8 TFLOPS
没有过多的依赖,像教程一样简洁
完全即时编译
核心逻辑约为300行 - 但在大多数矩阵大小上均优于专家调优的内核
支持密集布局和两种MoE布局
传统计算用16位或32位数字(类似快递用大箱子装小物件),而DeepGEMM用8位数字(换成小箱子),内存占用直接砍半,但通过特殊技巧保证计算不出错。
代码只有300行,但比大公司(比如英伟达)的官方工具还快,某些场景下速度翻倍。
像手机自动调亮度一样,DeepGEMM能根据任务大小自动生成最适合的代码,不用人工调整。特别擅长处理形状不规则的矩阵(比如112x112这种非标准尺寸),避免资源浪费。
针对最新一代GPU(比如H100)的「隐藏技能」深度优化,相当于给跑车换了定制发动机。
DeepGEMM通过FP8低精度计算和动态负载均衡技术,让万亿参数模型的训练成本断崖式下降。
例如:
- DeepSeek-V3/R1模型:训练时间缩短50%,硬件成本节省40%。这得益于FP8将显存占用压缩至传统方法的1/3,同时通过CUDA核心两级累加技术维持计算精度,相当于用"小货车运大件"却不出错。
- MoE模型突破:在混合专家模型中,DeepGEMM通过连续布局优化和动态路由调度,将专家网络激活效率提升89%,让"95%参数静默、5%专家工作"的稀疏计算效率最大化。

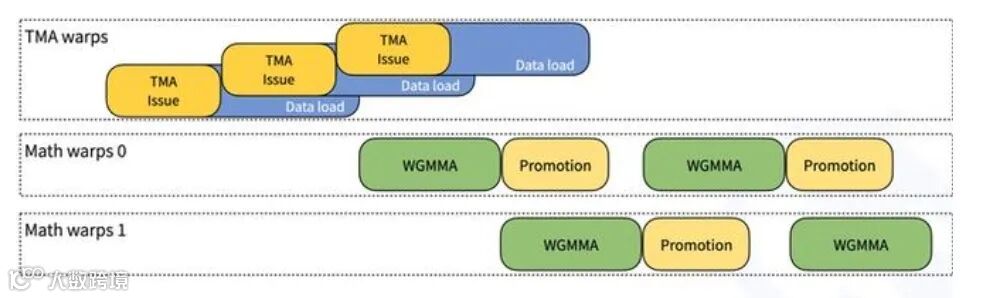
- 智能客服升级:响应速度提升2倍,某电商平台日均处理量从10万次飙升至50万次。这得益于其1358 TFLOPS的推理算力,以及TMA异步数据搬运技术,让对话生成像"流水线作业"般顺畅。
- 游戏与元宇宙:Unity引擎集成DeepGEMM后,3D人物渲染速度从5秒/帧压缩至1.8秒/帧,实时物理特效(如布料模拟、流体效果)延迟降低60%。
- 气象预测:全球大气环流模型的矩阵运算效率提升2.1倍,72小时台风路径预测耗时从3小时缩短至47分钟。
- 生物医药:蛋白质折叠预测工具AlphaFold的单次计算耗时从3小时降至47分钟,加速新药研发进程。
- 金融工程:蒙特卡洛模拟在H800显卡上的运行效率提升2.7倍,助力对冲基金年化收益增加8%。
- 手机端AI爆发:Stable Diffusion模型在骁龙8 Gen4芯片上的推理速度提升3倍,小红书创作者AI内容产出量增长120%。
- 工业物联网:工厂质检系统的图像识别延迟从220ms压缩至68ms,功耗降低40%,实现生产线实时瑕疵检测。
- 云服务降价潮:阿里云AI训练实例价格下降39%,个人开发者可0.2元/分钟租用H800算力,相当于"用网吧电脑价格玩转超算"。
- 企业级应用下沉:初创公司用单卡RTX 4090即可训练70亿参数模型,AI创业门槛从百万级降至十万级。
- 实时翻译革命:跨国视频会议的语音转文字延迟从3秒压缩至0.8秒,字幕同步率提升90%。
- AI内容创作:4K视频渲染耗时从6小时降至2.5小时,自媒体创作者日均产出量翻倍。
- 智能家居进化:全屋智能系统的决策响应速度提升3倍,灯光/温控调节延迟低于200ms。
- 气象预测:全球大气环流模型的矩阵运算效率提升2.1倍,72小时台风路径预测耗时从3小时缩短至47分钟。
- 生物医药:蛋白质折叠预测工具AlphaFold的单次计算耗时从3小时降至47分钟,加速新药研发进程。
- 金融工程:蒙特卡洛模拟在H800显卡上的运行效率提升2.7倍,助力对冲基金年化收益增加8%。
内容包含AI生成,仅供参考讨论





跨架构征服计划:2025Q3将支持AMD MI300系列,通过HIP框架移植核心算法,让非英伟达显卡也能获得80%性能提升。
智能精度切换:正在研发的动态精度引擎,能根据神经网络层重要性自动切换FP8/FP16计算,类似相机根据光线自动调节ISO。
量子计算接口:实验性分支已实现量子模拟器的矩阵乘法加速,在IBM Quantum平台上验证了12%的速度提升。
这场由DeepGEMM引发的技术革命,正在将AI从"实验室玩具"转化为"水电煤"级基础设施。正如开发者社区所言:"当全球都在clone这300行代码时,算力霸权已悄然易主。"

结 语
三天以来DS接连发布了FlashMLA、DeepEP和DeepGEMM三项底层优化技术,展现了DeepSeek团队对GPU底层架构的深刻理解,对此,AI infra厂商趋境科技的相关技术人员表示,“称其为比NVIDIA还了解Hopper架构下怎么写算子毫不为过。”
声明:文章内容仅供参考,不构成投资建议或其他任何形式的专业建议。对于因使用、引用、参考文章内容而导致的任何损失,我方不承担任何责任。
文章内部分图源网络,如有内容、版权和其他问题,请及时与我们联系,我们将在第一时间处理。
如果您有兴趣了解更多,可以持续关注我们的公众号资讯,以及即将推出的“2025SIE全球供应链创新论坛”。同时,欢迎各位读者向我们投稿,分享您的行业经验和成果。
活动预告:
2025 SIE 全球供应链创新论坛 现已预定于 2025年3月22日 在上海举办。

在本次博览会上,您将了解到企业如何在供应链重塑的过程中抓住新机遇,通过变革不断优化各个环节。我们将探讨人工智能、自动化、先进分析和协作网络等技术的快速发展,如何为您的企业提供强大的支持,帮助优化运营、提升决策质量并提高效率。同时,我们也将为企业构建更加可持续、高效且协作的供应链提供创新思路。
我们期待您的参与,让我们一起碰撞思想,共同推动供应链的变革,塑造更加具有韧性和创新精神的未来。
欢迎转发分享活动,若有多人填写您的信息作为推荐人,更有好礼相送!
合作媒体:

往期推荐:



