

Stochastic Depth:对于深残差网络,随机跳过部分残差块。
与基于一致性训练和伪标签方法的对比:这些方法没有使用在标记数据上训练的教师模型来生成伪标签,而是使用正在训练的模型来生成伪标签。在训练的早期阶段,被训练的模型精度低,熵高,因此一致性训练会使模型正则化为高熵预测,从而阻止其获得良好的准确率。
实验

嘈杂学生训练的EfficientNet-L2达到了88.4%的top-1准确率,明显优于先前EfficientNet上报告的最佳准确率85.0%。其中0.5%的提升来自于扩大模型,2.9%的提升来自于嘈杂学生训练。嘈杂学生训练也优于FixRes ResNeXt-101 WSL的86.4%准确率,而这项工作需要3.5B有标签图像,相比之下嘈杂学生训练只需要300M未标记的图像。
在三个困难样本上的实验也证明了该方法的健壮性。
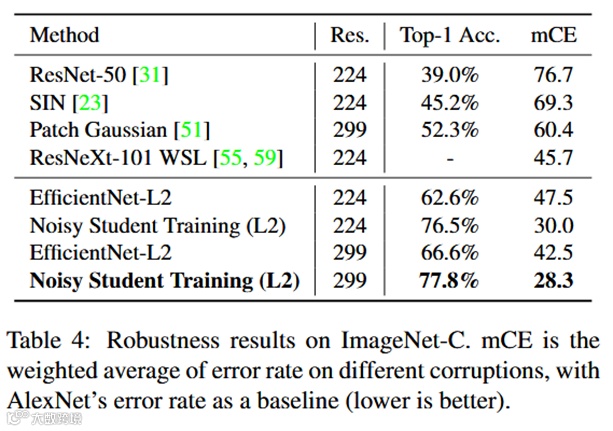


消融实验结论
移除噪声导致模型性能下降
迭代训练使得准确率上升
更大更强的教师模型会使学生模型也增强
学生模型性能需要大量无标签数据
对于域外数据,软伪标签效果好于硬伪标签
学生模型需要足够大
小模型需要数据平衡
将有标签和伪标签数据联合训练,效果好于在伪标签预训练,再用标签微调
无标签数据的batch size要大于有标签批次
重新训练优于用教师模型初始化
文献来源
Xie, Qizhe, et al. "Self-training with noisy student improves imagenet classification." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.