

极市导读
OccScene 把语义 Occupancy 预测塞进扩散生成框架,用 Mamba 对齐模块实现“边生成-边感知”闭环,仅文本即可产出跨视角一致的 3D 场景,并显著提升下游感知模型性能,代码已开源。>>加入极市CV技术交流群,走在计算机视觉的最前沿

-
论文标题: OccScene: Semantic Occupancy-based Cross-task Mutual Learning for 3D Scene Generation -
作者: Bohan Li, Xin Jin, Jianan Wang, Yukai Shi, Yasheng Sun, Xiaofeng Wang, Zhuang Ma, Baao Xie, Chao Ma, Xiaokang Yang, Wenjun Zeng -
机构: 上海交通大学, 宁波东方理工大学,Astribot, PhiGent Robotics -
论文地址: https://arxiv.org/abs/2412.11183 -
录用期刊: IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
研究背景:当生成模型遇上自动驾驶
在自动驾驶系统的研发中,高质量、大规模的标注数据是训练感知模型的“燃料”。但获取这些数据费时费力,成本高昂。因此,学界和业界开始将目光投向生成模型,希望用AI来创造合成数据,从而“喂饱”感知模型。
然而,传统的做法通常将“生成”和“感知”作为两个独立的环节。生成模型只管“画画”,画出来的场景虽然好看,但可能不符合真实世界的物理规律和几何结构,对于下游的感知任务来说,这些“华而不实”的数据价值有限。OccScene要解决的正是这个“学用脱节”的问题。
01 核心亮点与贡献
OccScene 首次实现了 3D 场景生成与语义Occupancy感知的深度融合,通过创新的联合扩散框架,让生成与感知任务“互惠互利”,实现“1+1>2”的效果。
-
范式创新 (联合学习框架) :提出了一个统一的感知-生成框架,感知模型为生成提供精细的几何与语义先验,生成的合成数据反哺感知模型,形成良性循环。 -
技术突破 (Mamba对齐模块) :设计了新颖的基于Mamba的双重对齐模块 (MDA) ,高效地对齐了相机轨迹、语义Occupancy与扩散特征,确保了生成内容(尤其是视频)的跨视角一致性和几何精确性。 -
实用价值 (SOTA性能) :仅需文本提示,即可同时生成高质量的图像/视频以及对应的3D语义占据信息。作为一种即插即用的训练策略,它还能显著提升现有SOTA感知模型的性能。 -
理论支撑 (协同进化) :通过互学习机制推动模型找到更宽、更稳定的损失谷底,避免了独立学习中可能出现的局部极小值停滞问题,实现了生成与感知的协同进化。

02 与传统方法的本质区别

03 核心技术解析
3.1 联合感知-生成扩散框架 (Joint Perception-Generation Diffusion)
OccScene 的核心在于将语义Occupancy预测与文本驱动生成统一到单个扩散过程中。感知模型不再是独立的下游任务,而是作为“指导者”深度参与到生成环节。

两阶段训练策略
-
阶段一:生成器调优
-
目标:让生成器学会理解Occupancy的几何约束。 -
做法:冻结一个预训练好的感知模型权重,仅训练扩散UNet,使其学会在语义Occupancy条件的引导下生成真实场景。 -
阶段二:联合优化 (Mutual Learning)
-
目标:实现生成与感知的双向促进。 -
做法:同时解冻并训练扩散UNet和感知模型。生成器在感知器的指导下创造更多样、更困难的合成数据,这些高质量数据反过来提升感知器的性能,尤其是在处理罕见场景(corner case)时。
联合损失函数
为了在联合优化阶段平衡两个任务,设计了动态加权的损失函数:
其中, 是标准的扩散模型损失。感知损失 包含语义、几何和类别加权损失:
关键洞察: 通过噪声水平 进行动态加权。在去噪早期( 较大,噪声多),感知模型的监督权重较低;随着图像变清晰( 变小,噪声少),其监督权重逐渐增强,确保了训练的稳定性。

3.2 基于 Mamba 的双重对齐模块 (MDA)
为了让语义Occupancy这个“3D地图”和生成过程中的特征(diffusion latent)完美对齐,研究者们引入了 Mamba-based Dual Alignment (MDA) 模块,这也是性能超越传统Attention架构的关键。

MDA模块巧妙地利用Mamba线性复杂度和长序列建模的优势,实现了两大对齐:
-
跨视角相机编码与对齐:通过可变形3D卷积和相机参数编码,为每个视角的生成过程提供与之匹配的、视角感知的Occupancy特征,从而保证了视频生成时序上的一致性。 -
序列特征编码与融合:利用双向Mamba块并行扫描深度维度的Occupancy特征和时序维度的潜在特征,高效地融合空间几何与时间上下文信息。最后通过一个零卷积层将增强后的特征注入扩散UNet,既保留了原始生成能力,又引入了精确的几何语义指导。

3.3 推理过程的自我优化
OccScene的推理过程是一个独特的闭环:
-
从纯高斯噪声开始迭代去噪。 -
在每一步,解码出的(含噪)图像都会被送入感知模型。 -
感知模型预测出当前的语义Occupancy。 -
这个预测出的Occupancy立即作为条件,反馈给生成器的同一步,指导下一步的去噪。
这个“边生成、边感知、边校正”的自我优化过程,确保了最终生成结果的几何一致性和语义准确性,实现了“图像越清晰 → Occupancy越准确 → 生成质量越高”的正向循环。
04 实验结果与分析
4.1 3D场景生成质量
OccScene在室内、室外、单图和视频生成任务上均取得了SOTA性能。

定性分析:相比传统方法,OccScene生成的场景在几何上更合理(如车辆形状正常),细节更清晰(如远处景物),并且在跨视角视频中保持了高度的逻辑一致性。



4.2 对下游感知任务的提升
将OccScene作为数据增强策略,可以显著提升现有SOTA感知模型的性能。

结论:这证明了OccScene生成的合成数据质量高、信息量大,能有效帮助感知模型学习更鲁棒的特征。
4.3 消融实验

关键发现:
-
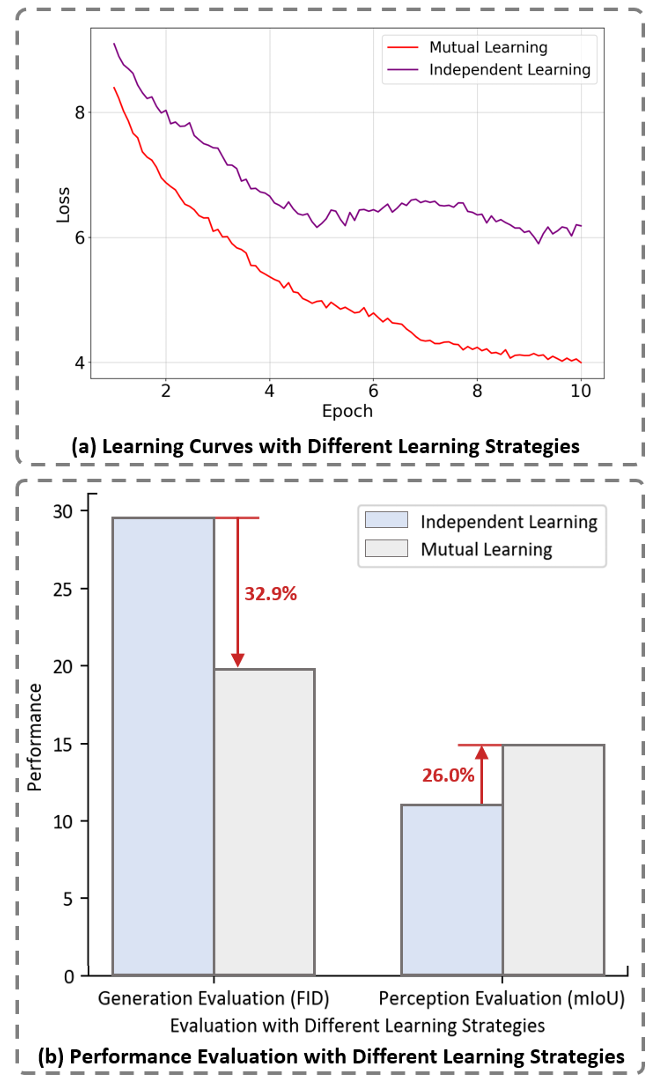
联合学习至关重要:相比离线生成数据再训练的模式,联合学习策略在生成质量(FID)和感知性能(mIoU)上都取得了压倒性胜利。 -
Mamba架构高效卓越:MDA模块不仅效果最好(FID最低),而且推理速度最快,相比Attention架构节省了32.5% 的时间。
05 总结与应用价值
OccScene通过一个设计优雅的“感知-生成”互学习框架,成功地将3D场景的生成与感知两个任务从彼此割裂推向了深度融合。这种“感知驱动生成,生成反哺感知”的闭环模式,不仅解决了生成模型“心中无数”的几何难题,也为感知模型提供了源源不断的高质量“养料”。
核心应用价值:
-
自动驾驶仿真:生成高保真、多样化的驾驶场景,特别是各种极端(corner case)场景,以低成本增强系统的鲁棒性。 -
机器人与AR/VR:为室内外场景的导航、交互提供可控、可编辑的虚拟环境。 -
通用数据增强:作为一种即插即用的数据生成器,为各类下游3D视觉任务提供高质量的训练数据,有效解决数据稀缺问题。
公众号后台回复“数据集”获取100+深度学习各方向资源整理
极市干货

点击阅读原文进入CV社区
收获更多技术干货