


文 | BBD基础架构部 周昊
随
着去中心化思想的流行,越来越多的系统正在从大规模整体式架构向着分布式微服务架构迁移,服务之间的相互调用日益复杂。如何保证系统的可观测性,快速发现系统性能瓶颈,及时定位线上错误?
分布式追踪系统正在快速成为解决上述问题的一种不可或缺的工具。Google、Twitter、Uber、淘宝、京东等公司根据自己的系统场景做了类似追踪系统的实现。
一般来说,设计一个大规模集群的跟踪系统,本质上是为了收集更多的复杂分布式系统的行为信息,帮助开发者在分布式中更好地理解系统的行为。
举个例子来说明。用户发起一次请求,这个请求会先到一个前端服务A,再发送两次RPC到中间层服务B和C,B会马上做出反应,但是C需要和后端的D和E交互后再返回给A,由A来响应最初的请求。
一般这些服务都会隔离部署在不同的机器上面,假设有其中一台服务发生故障,对于用户而言这种故障不会直接指向到具体的某个服务,这个时候需要我们依次排查所有服务直到找到问题发生的地方,这样的过程显然是痛苦又漫长的。
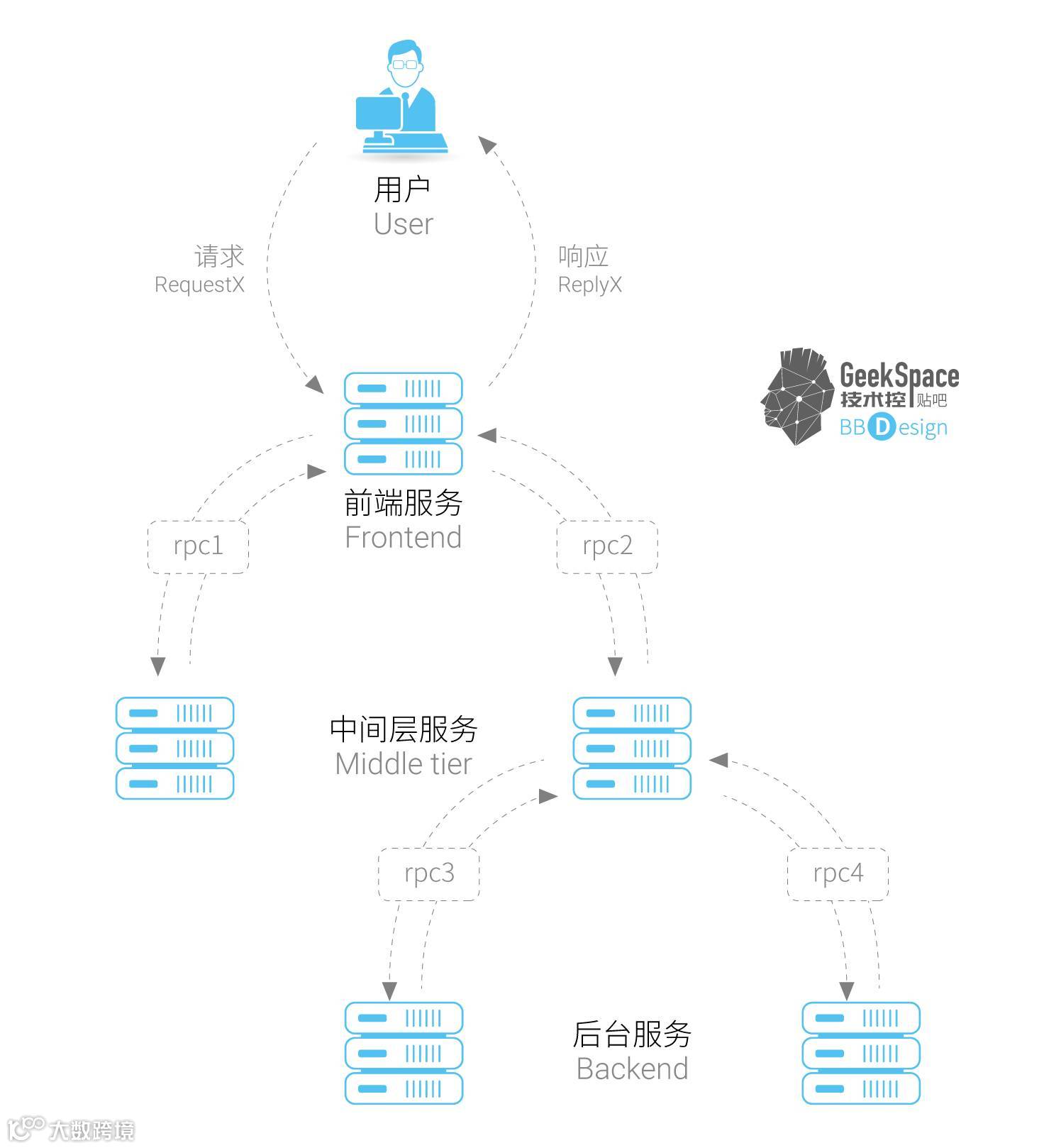
服务之间的相互调用
我们希望把它变成一件简单的事情。
如果某个服务发生故障,或者耗时很高,我们就能快速地从调用追踪的树形结构中发现问题。
 淘宝鹰眼的树形追踪效果
淘宝鹰眼的树形追踪效果
Google的Dapper如何实现跟踪?
在Google的Dapper论文中,树节点是整个架构的基本单元,而每一个节点又是对span(一个span可以简单视为一次原子调用)的引用。Dapper记录了span名称,以及每个span的id和父id,以重建在一次追踪过程中不同span之间的关系。
如果一个span没有父id被称为root span。所有span都挂在一个特定的跟踪上,也共用一个跟踪id(trace id)。任何一个span可以包含来自不同的主机信息,这些也要记录下来。
事实上,每一个RPC span可以包含客户端和服务器两个过程的注释,使得链接两个主机的span能描述一次完整的调用。当一个线程在处理跟踪控制路径的过程中,Dapper把这次跟踪的上下文在ThreadLocal中进行存储。
追踪上下文是一个小而且容易复制的容器,其中承载了跟踪的属性比如trace id和span id。当计算过程是延迟调用的或是异步的,通过线程池或其他执行器,使用一个通用的控制流库来回调。
Dapper确保所有这样的回调可以存储这次跟踪的上下文,而当回调函数被触发时,这次跟踪的上下文会与适当的线程关联上。在这种方式下,Dapper可以使用trace id和span id来辅助构建异步调用的路径。
Dapper的跟踪记录和收集管道的过程
首先,span数据写入本地日志文件中。
然后,Dapper的守护进程和收集组件把这些数据从生产环境的主机中拉出来。
最终,写到Dapper的Bigtable仓库中。
一次跟踪被设计成Bigtable中的一行,每一列相当于一个span。Bigtable的支持稀疏表格布局正适合这种情况,因为每一次跟踪可以有任意多个span。
Dapper的收集跟踪数据方式
带外数据收集:传输层协议使用带外数据(out-of-band)来发送一些重要的数据,如果通信一方有重要的数据需要通知对方时,协议能够将这些数据快速地发送到对方。为了发送这些数据,协议一般不使用与普通数据相同的通道,而是使用另外的通道。
带内数据收集:这里指的in-band策略是把跟踪数据随着调用链进行传送。out-of-band是通过其他的链路进行跟踪数据的收集,Dapper的写日志然后进行日志采集的方式就属于out-of-band策略。
Dapper的跟踪损耗
跟踪系统的成本:正在被监控的系统在生成追踪和收集追踪数据的消耗导致系统性能下降。需要使用一部分资源来存储和分析跟踪数据。
生成跟踪的损耗:Dapper运行库中最重要的跟踪生成消耗在于创建和销毁span和annotation,并记录到本地磁盘供后续的收集。
跟踪收集的消耗:读出跟踪数据也会对正在被监控的负载产生干扰。
在生产环境下对负载的影响:每个请求都会利用到大量的服务器的高吞吐量的线上服务,这是对有效跟踪最主要的需求之一,这种情况需要生成大量的跟踪数据,并且他们对性能的影响是最敏感的。
低损耗是追踪系统的一个关键的设计目标,某些类型的Web服务对植入带来的性能损耗确实非常敏感,因为如果这个工具价值未被证实但又对性能有影响的话,很难说服开发人员使用它。

基于Dapper,我们也做了一套自己的分布式追踪系统,叫做「Light」。
Light以插件的形式为应用服务提供了追踪分析RPC、Mysql、Http、Servlet等常见分布式调用的能力,并在Log4j或者Logback的堆栈中存放当前调用trace id以方便使用者实时查看,后台线程使用TCP将缓存在本地内存的追踪信息异步发送到Light收集器,经过追踪分析器处理以后便把追踪数据持久化到Hbase。
经过测试,Light在性能上表现良好,对应用性能损耗极低,追踪数据的展示也是实时的。Light正在内测中,相信一定会对应用有很大的帮助,希望以后还有机会和大家分享Light是怎样一点点做起来的。
Reference:Sigelman B H, Barroso L A, Burrows M, et al. Dapper, a Large-Scale Distributed Systems Tracing Infrastructure[J]. 2010.
本文由BBD(微信号:Brand_bigdata)原创,转载请注明来源及出处,违者必究。
