
导语
配对交易(Pairs Trading)是通过一买一卖的手段来赚取两只股票走势的差价的投资策略。本文介绍如何通过协整关系实现配对交易,以及在缺乏卖空机制情况下的搬砖策略。
本文由JoinQuant量化课堂推出,难度为进阶下,理解深度为level-0。
阅读本文需要掌握协整(level-0)的知识。
配对交易
相信很多同学都了解过 Pairs Trading,即配对交易策略。其基本原理就是找出两只走势相关的股票。这两只股票的价格差距从长期来看在一个固定的水平内波动,如果价差暂时性的超过或低于这个水平,就买多价格偏低的股票,卖空价格偏高的股票。等到价差恢复正常水平时,进行平仓操作,赚取这一过程中价差变化所产生的利润。
使用这个策略的关键就是“必须找到一对价格走势高度相关的股票”,而高度相关在这里意味着在长期来看有一个稳定的价差,这就要用到协整关系的检验。
在量化课堂介绍协整关系的文章里,我们知道如果用 Xt 和 Yt 代表两支股票价格的时间序列,并且发现它们存在协整关系,那么便存在实数 a 和 b,并且线性组合 Zt=aXt−bYt 是一个(弱)平稳的序列。如果 Zt 的值较往常相比变得偏高,那么根据弱平稳性质,Zt 将回归均值,这时,应该买入 b 份 Y 并卖出 a 份 X,并在 Zt 回归时赚取差价。反之,如果 Zt 走势偏低,那么应该买入 a 份 X 卖出 b 份 Y,等待 Zt上涨。所以,要使用配对交易,必须找到一对协整相关的股票。
这里要提醒读者,无论是原始的 Pairs Trading 策略,还是本篇的搬砖策略,在寻找股票对时,数据上的检验都只是辅助手段。我们首先要做的还是在基本面的角度进行分析,分析公司的主营业务,产品链,业内地位等。在此基础上,我们才会对有可能具有协整关系的股票进行数据上的检验。这是非常重要的。
协整关系的检验
我们想使用协整的特性进行配对交易,那么要怎么样发现协整关系呢?
在 Python 的 Statsmodels 包中,有直接用于协整关系检验的函数 coint,该函数包含于 statsmodels.tsa.stattools 中。
首先,我们构造一个读取股票价格,判断协整关系的函数。该函数返回的两个值分别为协整性检验的 p 值矩阵以及所有传入的参数中协整性较强的股票对。我们不需要在意 p 值具体是什么,可以这么理解它: p 值越低,协整关系就越强;p 值低于 0.05 时,协整关系便非常强。
import numpy as np
import pandas as pd
import statsmodels.api as sm
import seaborn as sns
# 输入是一DataFrame,每一列是一支股票在每一日的价格
def find_cointegrated_pairs(dataframe):
# 得到DataFrame长度
n = dataframe.shape[1]
# 初始化p值矩阵
pvalue_matrix = np.ones((n, n))
# 抽取列的名称
keys = dataframe.keys()
# 初始化强协整组
pairs = []
# 对于每一个i
for i in range(n):
# 对于大于i的j
for j in range(i+1, n):
# 获取相应的两只股票的价格Series
stock1 = dataframe[keys[i]]
stock2 = dataframe[keys[j]]
# 分析它们的协整关系
result = sm.tsa.stattools.coint(stock1, stock2)
# 取出并记录p值
pvalue = result[1]
pvalue_matrix[i, j] = pvalue
# 如果p值小于0.05
if pvalue < 0.05:
# 记录股票对和相应的p值
pairs.append((keys[i], keys[j], pvalue))
# 返回结果
return pvalue_matrix, pairs
其次,我们挑选10只银行股,认为它们是业务较为相似,在基本面上具有较强联系的股票,使用上面构建的函数对它们进行协整关系的检验。在得到结果后,用热力图画出各个股票对之间的 p 值,较为直观地看出他们之间的关系。
我们的测试区间为2014年1月1日至2015年1月1日。热力图画出的是 11 减去 p 值,因此颜色越红的地方表示 p 值越低。
stock_list = [“002142.XSHE", ”600000.XSHG", “600015.XSHG", ”600016.XSHG", ”600036.XSHG", “601009.XSHG",“601166.XSHG", ”601169.XSHG", “601328.XSHG", ”601398.XSHG", “601988.XSHG", “601998.XSHG"]
prices_df = get_price(stock_list, start_date=”2014-01-01", end_date=“2015-01-01", frequency=”daily", fields=[“close"])[”close"]
pvalues, pairs = find_cointegrated_pairs(prices_df)
sns.heatmap(1-pvalues, xticklabels=stock_list, yticklabels=stock_list, cmap=“RdYlGn_r’, mask = (pvalues == 1))
print pairs

可以看出,上述10只股票中有5对具有较为显著的协整性关系的股票对(红色表示协整关系显著)。我们选择使用其中 p 值最低(0.01060.0106)的工商银行(601398.XSHG)和中国银行(601988.XSHG)这一对股票来进行研究。首先调取工商银行和中国银行的历史股价,画出两只股票的价格走势。
stock_df1 = prices_df["601398.XSHG”]
stock_df2 = prices_df["601988.XSHG“]
plot(stock_df1); plot(stock_df2)
plt.xlabel("Time“); plt.ylabel("Price”)
plt.legend(["601988.XSHG”, "601998.XSHG“],loc=’best‘)

接下来,我们用这两支股票的价格来进行一次OLS线性回归,以此算出它们是以什么线性组合的系数构成平稳序列的。
x = stock_df1
y = stock_df2
X = sm.add_constant(x)
result = (sm.OLS(y,X)).fit()
print(result.summary())

系数是 0.99380.9938,画出数据和拟合线。
fig, ax = plt.subplots(figsize=(8,6))
ax.plot(x, y, 'o', label="data")
ax.plot(x, result.fittedvalues, 'r‘;, label="OLS";)
ax.legend(loc='best’)
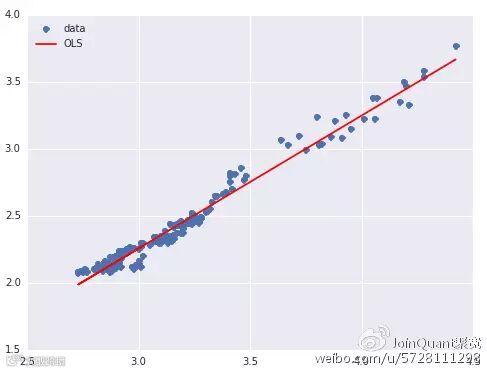
设中国银行的股价为 Y,工商银行为 X,回归拟合的结果是
Y=−0.7248+0.9938⋅X
也就是说 Y−0.9938⋅X是平稳序列。
依照这个比例,我们画出它们价差的平稳序列。可以看出,虽然价差上下波动,但都会回归中间的均值。
plot(0.9938*stock_df1-stock_df2);
plt.axhline((0.9938*stock_df1-stock_df2).mean(), color="red", line)
plt.xlabel("Time"); plt.ylabel("Stationary Series")
plt.legend(["Stationary Series", "Mean"])

买卖时机的判断
这里,我们先介绍一下 z-score。z-score 是对时间序列偏离其均值程度的衡量,表示时间序列偏离了其均值多少倍的标准差。首先,我们定义一个函数来计算 z-score:
一个序列在时间 t 的 z-score,是它在时间 t 的值,减去序列的均值,再除以序列的标准差后得到的值。
def zscore(series):
return (series - series.mean()) / np.std(series)
对于工商银行与中国银行的平稳线性组合,用上面的函数计算 z-score 并绘出图。
plot(zscore(0.9938*stock_df1-stock_df2))
plt.axhline(zscore(0.9938*stock_df1-stock_df2).mean(), color="black")
plt.axhline(1.0, color="red", line)
plt.axhline(-1.0, color="green", line)
plt.legend(["z-score", "mean", ”+1", “-1"])

我们认为,当两这个序列的 z-score 突破 1 或者 −1 时,说明两支股票的价差脱离了统计概念中的合理区间,如果它们的协整关系能够保持,那么它们的价差应该收敛。所以,在发现上述序列突破 1 或 −1 时,应该按照比例买多一支股票并做空另外一支,从而赚取之后收敛的差价。
结合上图,当 z-score 突破上方红线时,说明工商银行的价格相对于中国银行高估,因此我们买入 1 份中国银行并卖空 0.9938 份工商银行(系数根据前面的线性回归得出),并当 z-score 回归于 0 时清仓获利。如果 z-score 突破下方绿线的话,反方向操作即可
中国式 Pairs Trading 策略:搬砖
标准的配对交易策略是通过一买一卖的行为来对冲掉系统性风险,从而以较低的风险赚取到持续的利润。但目前A股市场是不允许进行直接卖空操作的。融券的渠道我等散户又搞不定。因此,我们对原始的配对交易进行修改,只进行做多操作,不进行做空操作。这种操作被形象的成为“搬砖”。其目标不是追求绝对收益,而是追求收益率比一直持有一个股票的高。
在选定一组协整关系为 aX−bY 的股票后,我们有以下策略:
∙∙ 选定比例 p 和 q,初始仓位为 p% 的 X 和 q% 的 Y。选定测试 z-score 天数的参数 test_daystest_days。
∙∙ 每天执行:
- 计算两支股票的线性组合序列 aX−bY 在过去 test_daystest_days 的标准差和均值,以此计算 z-score。
- 如果当天 z-score 高出 1,则将仓位调整为全仓 Y。如果当天 z-score 小于 −1,则将仓位调整为全仓 X。
- 如果上一交易日处于全仓一支股票的状态,并且今日 z-score 回归 0 点,则调整回至 p% 和 q% 的比例。
在之前章节中我们通过分析发现,工商银行和中国银行在2014年全年有着非常强的协整关系,但我们不能再14年进行回测,因为这样等同于使用未来函数(比如文章最后的回测),因此我们在2015至2016的区间内进行回测。使用的参数是 p%=50%,q%=50%,test_days=120。
由于没有对冲机制,所以不能依靠绝对收益评估策略的效益,而要用它和配对的两支股票对比。如果分别跑赢了两支股票,那么说明该策略是有效的。
首先是和工商银行的对比,我们的策略完全跑赢了这支股票。

其次是和中国银行的对比,虽然前半年被工商银行拖了后腿,但后半年还是稳稳地跑赢了。

本策略全程满仓,持有股票只限于以上两支。通过判断两支股票的相对强度进行仓位调整,最后收益胜过了其中的任何一支,效果是非常显著的。
策略的应用
搬砖的策略能跑赢个股,但也只能跑赢个股,所以若想投入使用并赚取稳定收益,还要结合其他策略一起使用。比如,使用基本面或者技术面的思路来判断银行指数在未来一段时间中的走势。如果趋势乐观,则可以在指数成分股中选取两支具有协整性质的个股进行搬砖。如果趋势不乐观,则空仓对待。这样,通过搬砖,在其他策略之上产生更多的超额收益
代码说明书与变量说明书
函数说明书

全局变量说明书

本文由JoinQuant量化课堂推出,版权归JoinQuant所有,商业转载请联系我们获得授权,非商业转载请注明出处。
为了更好的阅读体验以及查看代码请移步原文:连接君在此,谁敢点我!╭(╯^╰)╮
这么酷炫的文章还不转发和关注吗:)
点击『阅读原文』,可查看原文,克隆策略。

长按指纹,关注JoinQuant