
导语:本文提供了在研究中自动根据指定参数进行回测,并将一组回测结果可视化的框架。
(内含代码与图表,推荐点击最下方“阅读原文”阅读。)
引言
在因子分析系列中我们遇到了一个比较明显的需求,就是把全部股票按照各个分位进行回测,并且分析每个分位的收益情况。但其实有这个需求的不仅限于因子的分析,有时我们在策略中还会有一些其他的参数需要进行调整并分析调整后的结果。本篇文章对于这个需求设立了一个参数分析框架,集合运行回测和各种分析结果的功能于一体。也希望读者多提意见,我们会对其进行改进。
整个框架写在了一个parameter_analysis 类里面,附在文章结尾的研究模块。下面讲功能和使用方法。
初始化回测
如果想进行分析的回测还没有被运行过,我们需要运行回测并保存回测结果。首先,
parameter_analysis(algorithm_id=None)
将这个类初始化。输入中的 algorithm_id 是想要回测使用的策略编码,获取方式是策略编辑页 url 的尾部,如下

parameter_analysis.run_backtest() 函数可以运行回测,并且 parameter_analysis.organize_backtest_results() 函数可以以回测结果分析一些指标和数据。但这两个函数都已经打包在 parameter_analysis.get_backtest_data() 中,所以我们只讲最后的这个函数。调用这个函数的输入较多,有
parameter_analysis.get_backtest_data(algorithm_id=None,
benchmark_id_None,
file_name='results.pkl',
running_max=10,
start_date='2006-01-01',
end_date='2016-11-30',
frequency='day',
initial_cash='1000000',
param_names=[],
param_values=[]
)
我们一个一个来讲。
algorithm_id 正如其名是策略的 id 编码,和之前提到的一样。如果在创建parameter_analysis 时已经提供了的话这里就不用再提供了。
benchmark_id 是自定义基准的回测编码,注意不是策略而是回测。函数会以这个回测的收益率曲线作为基准曲线,要求这个回测的起始和结束时间和参数中的 start_date 与 end_date 分别吻合。如果不提供 benchmark_id,则策略会自动用 algorithm_id 对应的策略中指定的基准作为基准。
file_name 是储存数据的文件名,因为是以 pickle 进行存储,文件名结尾必须是 .pkl。回测运行完毕后的 pickle 文件将被存储于和研究的 .ipyny 相同的文件夹,默认文件名为‘results.pkl’。
running_max 是同时可运行的回测的上限。由于在平台上同时运行的回测数量上限是 10 个,固 running_max 默认设为 10。但是,如果需要在这个框架运行的时候留出一些空位来运行其他回测,可以将 running_max 设为 9 或者更小的数字。当这个函数被要求运行超过 running_max 数量的回测时,会自动将它们进行排队,在之前的完成后再运行后面的。
start_date 和 end_date 顾名思义就是回测起始和结束的日期,默认数值如上所述。
frequency 是回测频率,按需求使用 'day' 或者 'minute',默认为'day'。
initial_cash 是回测的起始资金,默认一百万。
值得细讲的是 param_names 和 param_values 两个输入。这里 param_names 是一个 list 的 strings,它对应着策略中所有需要调整的全局变量的名字。比如说,我们需要将策略中的 g.abc 和 g.x_y_z 两个参数更改数值进行多次回测,那么 param_names 应该设为 ['abc', 'x_y_z']。而param_values 是一个 list 的 list,要求 len(param_values)==len(param_names)。其中 param_values[i] 是 param_names[i] 的名字所对应的调参值。举例来说,我们需要把 g.abc 和 g.x_y_z 分别赋予 ['a','b', 'c'] 和 [1,2] 的值进行回测,那么就应该输入 param_values=[['a','b','c'], [1,2]]。函数会自动列举所有这些参数选项的组合进行回测,在上面的例子中就会产生六个回测,分别对应参数值 (g.abc, g.x_y_z) 等于 ('a',1)、('a',2)、('b',1)、('b',2)、('c',1)、('c',2)。
在所有参数对应的回测运行完成之后,函数会整理数据并存储 pickle 文件。
数据内容和读取文件
当我们运行完 parameter_analysis.get_backtest_data() 之后,除了保存在 pickle 文件,还会直接保存在这个类下面。我们逐一介绍这些项目:
parameter_analysis.algorithm_id 顾名思义就是我们输入的策略编码。
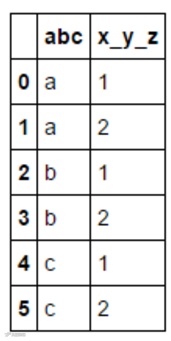
parameter_analysis.params_df 是包含了所有回测使用的参数的 DataFrame。其中,横行 index 是回测的编号,代表它是第几个被运行的回测,从 0 开始计数。竖列 columns 是之前输入的 param_names 的名字。df 中的内容是回测相对应的参数数值。举例来说,param_names = ['abc', 'x_y_z'],param_values=[['a','b','c'], [1,2]] 时,生成的 Data Frame 如下:.
parameter_analysis.evaluations 是一个 dict 的 dict。如果 i 是一个回测的编号(对应params_df 里的 index),那么 parameter_analysis.evaluations[i] 就是这个回测的各项指标,比如收益率、夏普比率、最大回撤。

当然,为了可以更直观地查看数据,还有 DataFrame 版的 parameter_analysis.evaluations_df。它是 evaluations 的 df 版,并且还带有 params_df 中的参数数据。

parameter_analysis.backtest_ids 是一个 dict 的 strings,keys 依旧是回测的编号,对应的 内容是该回测的 url 编码。
parameter_analysis.benchmark_id 是自定义基准回测的编码,如果没提供则是空。
parameter_analysis.dates 是一个 list 的 strings,是按序排列的回测中的每一个交易日。
parameter_analysis.benchmark_returns 是一 list 的 float,是基准的收益率数据,对应着 dates 中相同位置的日期。
parameter_analysis.returns 和 excess_returns 和 log_returns 和 log_excess_returns 都是一 dict 的 list,keys 是各个回测的编号,而相对应的 list 分别是该策略的收益率和超额收益率和对数收益率和对数超额收益率。其中,超额收益率是用回测净值除以基准净值计算而出,对数超额收益率是超额收益率的对数。和 benchmark_returns 一样,list 中的数据对应着 dates 中相同位置的日期。
最后两个特别计算的指标是 self.excess_max_drawdown 和self.excess_annual_return。这两个都是 dict,keys 是回测的编号,内容分别是策略超额收益曲线的最大回撤和策略超额收益曲线的年化收益率。这两个指标的意义在于,有时我们想看策略相对于基准的强弱,所以在排除掉基准的影响之后可以进行一些有意义的分析。
如果我们通过 parameter_analysis.get_backtest_data() 运行了回测并且获取了各种数据,但是关闭了研究模块,那么在再次打开研究继续分析时不需要再重新把回测都运行一遍,可以使用读取 pickle 文件的函数把已保存的数据读取。
使用 parameter_analysis.read_backtest_data(file_name='results.pkl') 即可读取数据。这里 file_name 是被读取的文件名,如果不是默认的 results.pkl 的话则需要另行输入。在读取之后,parameter_analysis 中的每个项目会变成上面所讲的内容,可以进行调取或者使用接下来的介绍的功能。
一些可视化功能
在获取数据之后,我们可以把一些指标或者曲线画出来,便于进行观察和分析。
首先是 parameter_analysis.get_eval4_bar(sort_by=[]) 函数,这个函数会以 bar 图的形式画出回测的收益率、最大回撤、夏普比率和波动率四个图表。每个图表上从左到右是每一个回测,默认是按照回测编号进行排列,但是也可以输入 sort_by 进行自定义排列。sort_by 是一个 list 的 strings,它是参数名称 param_names 的一个子集,意义为按照这些变量进行排序。举例来说,如果 sort_by=[‘abc’],那就是按照 ‘abc’ 参数从小到大排列回测,然后划出四张图表;如果 sort_by=[‘abc’, ‘x_y_z’],那就是先按照 ‘abc’ 进行排列,然后再按照 ‘x_y_z’ 进行排列(以 ‘x_y_z’ 排序后,组内按照 ‘abc’ 排序),排好之后画图。下图是按照 BP 指标大小排列出来的, get_eval4_bar() 函数使用默认值既可。

接下来是 parameter_analysis.get_eval(sort_by=[]) 和 parameter_analysis.get_excess_eval(sort_by=[])。第一个函数会画出各个回测年化收益率和最大回撤,而第二个函数会画出超额年化收益率和超额最大回撤,sort_by 的功能和之前解释的一样。这两个函数的效果还是直接举例画出来最直接。下图是以 BP 单因子策略十分位结果的 paramter_analysis.get_eval() 得出的图。

最后是画出回测的收益曲线、超额收益曲线、对数收益曲线以及超额对数收益曲线的函数,分别是 parameter_analysis.plot_returns() 、plot_excess_returns()、plot_log_returns() 和 plot_log_excess_returns()。这些函数没有输入,直接用就行。图是以 BP 单因子策略十分位结果的 paramter_analysis.plot_returns() 得出的图。

深入研究举例
作为示例,这里我们以 BP 因子为例将策略分为 (0,10),(10,20),… ,(90,100) 十个分位区间进行回测并分析。
在回测之前我们需要制定一个自定义基准。在三篇因子研究分析中,我们发现很多因子不论是最大 5% 还是最小 5% 的分位都很轻松地跑赢了上证指数。经过一些分析,可以发现原因在于上证指数的指数构成偏大盘股,并且按照市值进行加权,所以该指数的小市值暴露度很低;然而我们回测的策略是把所有分位内的股票进行等权分配,小市值暴露度比上证指数要大,所以从这点来看可比性不高。为了剔除市值影响造成的策略和基准之间的差异,我们构建一个“等权全指”作为自定义基准,就是每月初将资金等权分配于所有而是一个交易日没停牌的股票之间,的到回测如下,下图基准是上证指数。

对应我们调用的指令如下,初始化 parameter_analysis 类并且启动【量化课堂】因子研究系列之一 -- 估值和资本结构因子中的 BP 因子回测,按 10 个百分点进行分位(共十个回测),并使用上述的等权全指作为基准:
# 初始化 parameter_analysis 类,设定回测策略 id
pa = parameter_analysis('bce2e5c55b3b631f91985c9bf113414f')[这个怎么表述?可以定义简化名称调用class?]
# 运行回测
pa.get_backtest_data(file_name = 'results.pkl',
running_max = 10,
benchmark_id = 'ae0684d86e9e7128b1ab9c7d77893029',
start_date = '2006-02-01',
end_date = '2016-11-01',
frequency = 'day',
initial_cash = '2000000',
param_names = ['factor', 'quantile'],
param_values = [['BP'], tuple(zip(range(0,100,10), range(10,101,10)))]
)
我们先进行回测,然后画出收益图。首先是收益曲线 parameter_analysis.plot_returns(),这里回测编号从 0 到 9 是 BP 值从小到大的回测。可以看出这个因子是具有单调性质的,也就是说 BP 值更大的股票表现一般比 BP 小的股票表现更好。但是,BP 指标的单调性并不是绝对的,比如 (10,20) 分位的股票的收益率是最高的 。

再用 parameter_analysis.get_eval4_bar() 画出策略的年化收益、最大回撤、夏普率和波动率,可以看出 BP 策略各分位表现出了收益不单调,对应的其他指标也并不单调。能够简单总结 BP 较小还是体现公司的股票回报率会好于 BP 较高的股票,伴随的是收益较高反而最大回撤较小。夏普率的变动与回报率较为一致,但是波动率变动在不同分位间差距不明显。

我们使用正的年化收益与负的最大回撤构建柱状图,parameter_analysis.get_eval():

加入新的基准后可以计算对于新基准回报率的超额收益率。进一步分析,我们使用 parameter_analysis.plot_excess_returns() 画出几个回测的超额收益曲线。这个图给我们一些有用的信息:BP 值最小的 10% 的股票的波动率极大,并且收益并没有超出基准太多,说明选这个区间的股票进行投资也许并不是很好。第二现象是,几个分位的回测在 06 年和 10 之间的超额收益有相互拉开,但在 10 年之后不同分位并没有明显的超额收益区别,说明这个因子在 10 年之后基本已经失效。

如【更新说明】新超额收益 和 对数轴的思路,我们也生成对数轴回报率,使用函数 parameter_analysis.plot_log_returns() 获取。如对数轴说明文章中介绍的,这样的图形在收益膨胀了现值后仍然可以明晰波动的相对大小。

结合超额收益与对数轴,可以通过 parameter_analysis.plot_log_excess_returns() 获得超额收益的对数轴图。如果是超额收益始终持续放大的过程,超额收益的对数轴图形将会是斜线上升的,然而下图中收益持平说明在相当长的一段时间中没有变动。

最后,可以通过 parameter_analysis.get_excess_eval() 获得超额回报和超额回报最大回撤的柱状图。可以看出,超额回报要明显小于策略原始回报,因为剔除了大盘整体的收益。同时,最大回撤也拉开了距离;按照策略净值算的最大回撤由于经历过同样的股灾,所以最大回撤都是百分之七十多,但在剔除大盘影响之后就能比较清晰地对比超额收益的回撤。整体来说,按 BP 选股的各个分为超额收益都不高,并且相对于基准的超额回撤都不小。

但这并不说明 BP 因子是一个无用的指标,只是说我们不能单单使用 BP 作为衡量标准并希望能得到超额收益,也许分行业分别计算 BP 或者结合其他的一些方法依然可以获得较好的收益。
小结
本文提供了一个使用研究模块调用回测结果进行调参并且研究分析的代码框架,其具有较好的兼容性和拓展性,细节之处还需要各位测试了解。在接下来的文章里,我们将使用次框架对因子系列文章 (【量化课堂】因子研究系列之一 -- 估值和资本结构因子、【量化课堂】因子研究系列之二 -- 成长因子和【量化课堂】因子研究系列之三 -- 技术因子)中的因子按分位排列进行回测并深入地分析这些因子的收益效果,敬请期待。
本文参考了多篇社区优秀帖子,这里一并感谢:
研究调用回测:【重磅更新】研究模块调用回测功能
回测排队运行:多个回测同时优化,改改列表和算法ID就行 by zhao
结果数据保存:JQ平台如何把DataFrame对象pickle或者json出来?
点击『阅读原文』,到JoinQuant社区参与讨论。

长按指纹,关注JoinQuant