
论文下载:关注回复【C729】获取领取 AAAI 2026 论文合集
自回归大语言模型(LLMs)在文本到图像生成(T2I)中因沉迷局部Next Token Prediction,普遍缺乏全局一致性,导致生成内容割裂、语义偏移,中科院沈阳自动化研究所与香港大学团队提出的AAAI2026 Oral成果ARRA框架,无需改变LLM架构和推理范式,通过训练阶段引入预训练视觉编码器的全局视觉表征对齐模型隐藏状态,以轻量策略弥合模态鸿沟,释放自回归大模型的图像生成潜力。

1. 【导读】

论文标题:Unleashing the Potential of Large Language Models for Text-to-Image Generation through Autoregressive Representation Alignment
作者:Xing Xie, Jiawei Liu, Ziyue Lin, Huijie Fan, Zhi Han, Yandong Tang, Liangqiong Qu
作者机构:1. Shenyang Institute of Automation, Chinese Academy of Sciences;2. University of Chinese Academy of Sciences;3. The University of Hong Kong
论文来源:AAAI2026(Oral)
论文链接:https://arxiv.org/abs/2503.07334v1
项目链接:https://github.com/xiexing0916/ARRA
2. 【论文速读】
该论文提出自回归表示对齐(ARRA) 这一新型训练框架,无需改变自回归大型语言模型(LLMs)的架构,即可实现具有全局连贯性的文本到图像生成。与需复杂架构重构的现有研究不同,ARRA通过全局视觉对齐损失与混合令牌 ,将LLM的隐藏状态与外部视觉基础模型的视觉表示进行对齐;其中令牌可实现局部下一个令牌预测与全局语义蒸馏的双重约束,使LLM在保留原有自回归范式的同时,隐性学习空间和上下文连贯性。该研究表明,重新设计训练目标(而非仅依赖架构创新)可解决跨模态全局连贯性难题,为推进自回归模型提供了互补范式,相关代码和模型将公开以推动自回归图像生成研究。
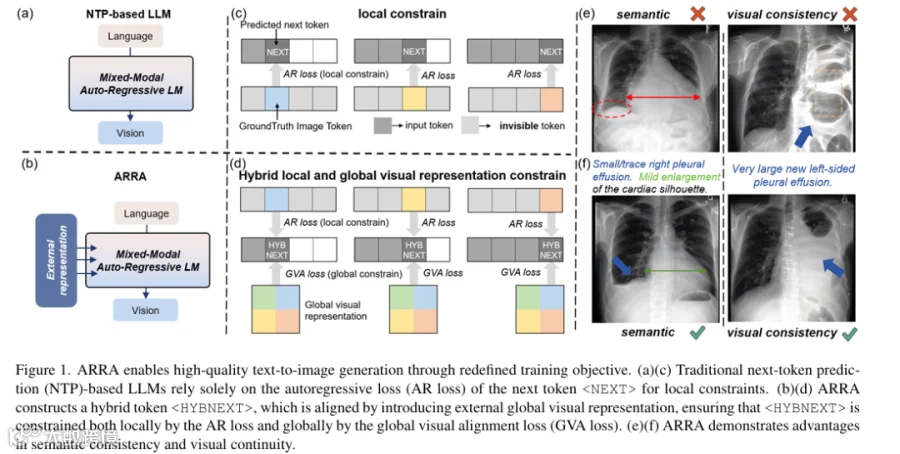


3. 【从LLM到跨模态生成:文本到图像任务的机遇与挑战】
3.1 技术基础:自回归范式的迁移
大型语言模型(LLMs)凭借自回归“下一个令牌预测” 范式,在生成式AI领域成效显著。研究人员将该范式迁移至文本到图像生成,如DALL·E、LlamaGen等,通过图像令牌化直接复用LLM框架。
3.2 核心挑战:跨模态与全局连贯性难题
文本领域的局部依赖适配性无法迁移至图像任务,仅优化局部令牌预测会忽略全局连贯性,导致图像片段化、语义不匹配,难以弥合语言与图像的跨模态差距。
3.3 现有方案局限:架构修改的兼容性困境
Transfusion等方案通过修改架构(双向注意力、扩散模块)建模全局结构,但偏离标准LLM框架,降低了与预训练模型的兼容性,需重新训练而丧失原有泛化优势。
3.4 相关技术对比:两类生成模型特性
-
• 扩散模型(SD3、Imagen3):生成质量优,但依赖独立文本编码器,无法统一建模文本与图像; -
• 自回归模型(VQ-VAE、Parti):支持图像令牌化生成,但受局部约束,需架构调整才能兼顾全局语义。
4. ARRA框架:LLM文本到图像生成的对齐设计方案
4.1 核心目标与整体框架
ARRA(自回归表示对齐)的核心目标:不改变LLM原有范式,通过外部视觉表示注入,解决其图像生成的全局特征缺失问题。
训练流程:文本
与图像
令牌化→外部编码器
提取图像全局视觉表示
→LLM学习令牌序列并对齐
;推理阶段移除对齐模块,LLM生成图像令牌后解码为像素图。
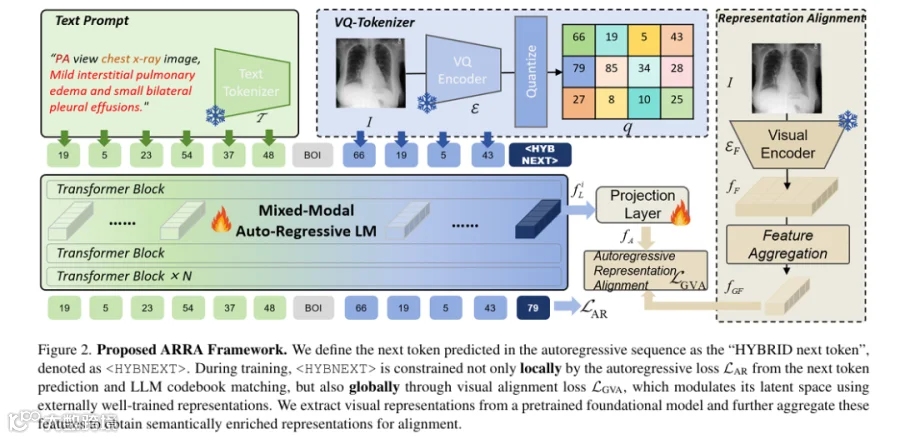
4.2 自回归建模:令牌化与下一个令牌预测
4.2.1 令牌化处理
-
• 图像: 经编码、量化得到离散令牌,再重塑为1D序列 ; -
• 文本: 经令牌器转化为序列 ,与 合并为统一序列 。
4.2.2 下一个令牌预测
-
• 概率建模: ; -
• 损失函数: 。
4.3 核心对齐设计:混合令牌与全局约束
4.3.1 全局视觉表示提取
图像 经预训练编码器 (BioMedCLIP/MedSAM等)得到特征 ,通过令牌(CLIP系列)或平均池化(SAM系列)聚合为全局表示 。
4.3.2 混合令牌
兼具局部与全局约束:局部匹配LLM码本保证序列连续,全局通过隐藏状态与 对齐注入语义。
4.3.3 对齐损失与联合优化
-
• 特征投影:隐藏状态经两层MLP转化为 (与 维度一致); -
• 对齐损失: (余弦相似度损失); -
• 联合损失: ( )。
5. ARRA实战检验:多维度实验结果与洞察
5.1 核心组件有效性分析
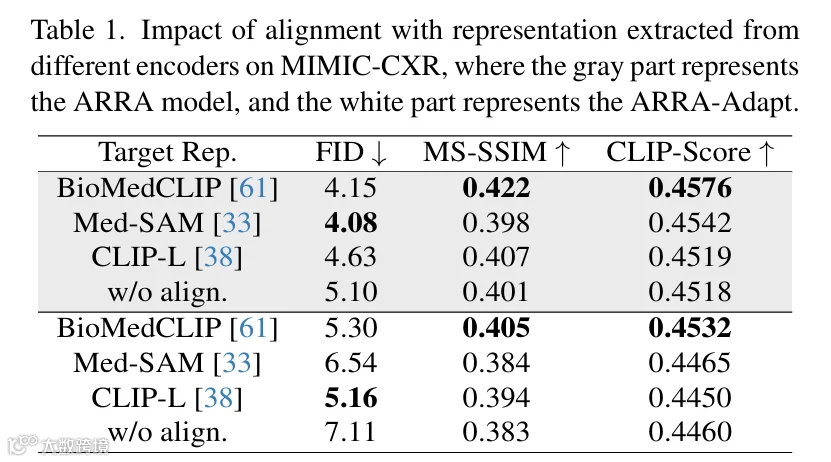
5.1.1 视觉编码器选择
-
• 无对齐时MIMIC-CXR的FID为5.10,引入编码器后均下降:BioMedCLIP(4.15)> Med-SAM(4.08)> CLIP-L(4.63); -
• 洞察:LLM无图像能力时,跨模态编码器(BioMedCLIP/CLIP)更利于语义衔接;有图像能力时,领域专用编码器(BioMedCLIP/Med-SAM)更优。
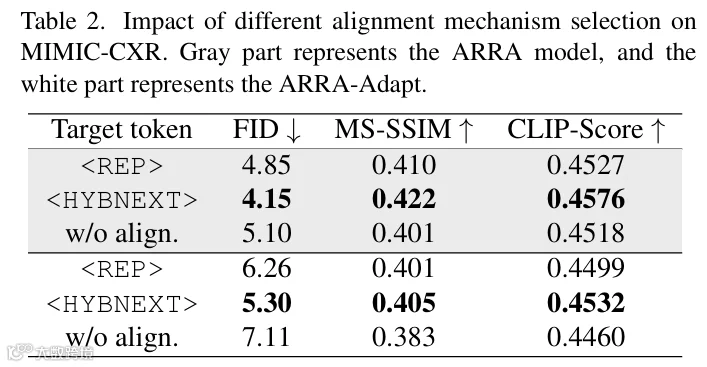
5.1.2 对齐机制对比
-
• 令牌(FID=4.15)显著优于固定令牌(FID=4.85); -
• 原因:遍历每步生成令牌,避免的“注意力衰减”问题,保证全局约束一致性。
5.1.3 对齐深度影响
-
• 早期层(如layer1,FID=4.15)对齐效果最优,深层(如layer31,FID=4.53)效果下降; -
• 逻辑:早期层提供全局语义引导,深层可专注捕捉高频细节,分工更合理。
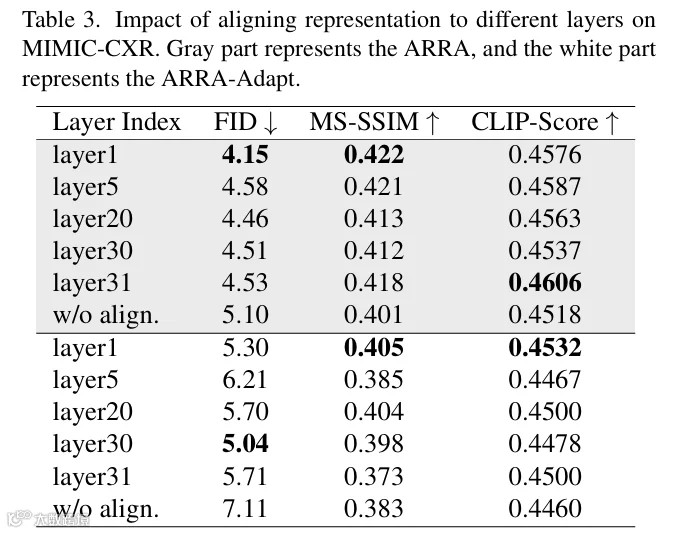
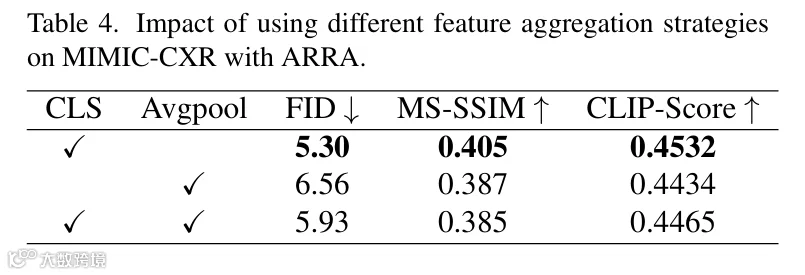
5.1.4 特征聚合策略
-
• 令牌聚合(FID=5.30)优于平均池化(FID=6.56)及两者结合(FID=5.93); -
• 优势:通过自注意力聚合全局信息,更适配跨模态对齐需求。
5.2 核心性能对比结果
5.2.1 医疗图像任务(MIMIC-CXR/DeepEyeNet)
-
• 对比基线Chameleon(FID=7.11),ARRA将FID降低25.5%(至5.30),ARRA-Adapt进一步降至4.15; -
• 对比其他方法:优于LLM-CXR(FID=5.88)、MINIM(FID=15.62)等,且生成图像无“肋骨错位”“病灶位置偏差”等问题。
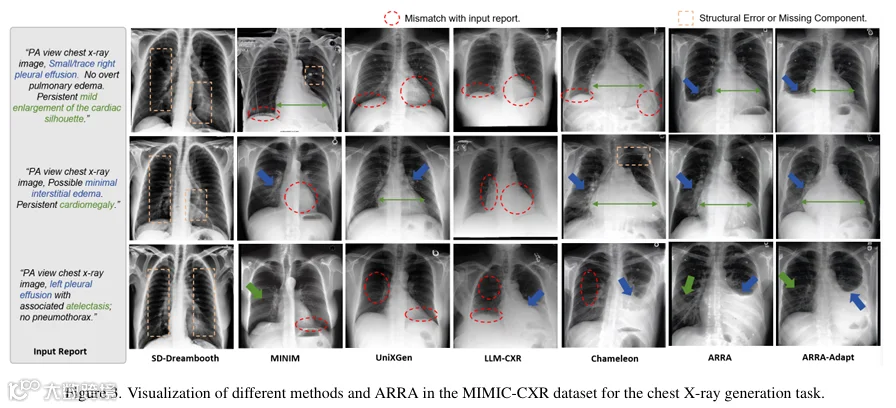
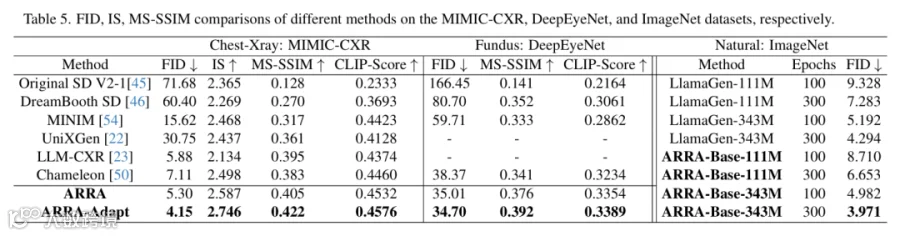
5.2.2 自然图像任务(ImageNet)
-
• 对比LlamaGen(111M参数,FID=7.283),ARRA-Base(FID=6.653)降低8.4%;343M参数下,ARRA-Base(FID=3.971)较LlamaGen(FID=4.294)降低7.5%; -
• 验证ARRA在通用图像生成场景的泛化性。
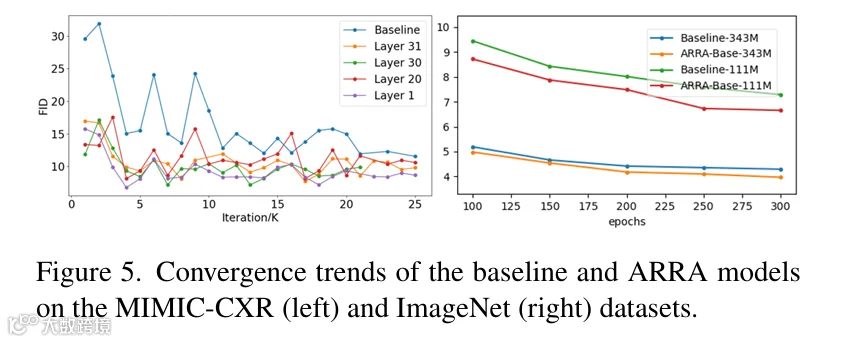
5.2.3 收敛速度
-
• 训练早期(前1000轮),ARRA模型FID下降速率是基线的1.5-2倍; -
• 原因:全局视觉约束引导模型沿正确轨迹学习,减少无效探索。
6. ARRA的价值沉淀与未来方向
6.1 总结
本文提出ARRA(自回归表示对齐)框架,通过引入全局视觉对齐损失与混合令牌,在不修改LLM架构的前提下,解决了其文本到图像生成时的全局连贯性不足问题。实验验证,ARRA在医疗(MIMIC-CXR)、自然图像(ImageNet)等领域均有效:降低先进LLM的FID值(如MIMIC-CXR上降25.5%),支持领域适配(医疗场景FID降18.6%),且加速训练收敛,证明“重设计训练目标”是突破跨模态生成瓶颈的有效路径。
6.2 展望
未来可进一步探索ARRA在更高分辨率图像生成、多模态(文本-图像-语音)统一建模中的应用;同时,可优化外部视觉表示的动态适配策略,提升框架在小众领域(如遥感、工业检测)的泛化能力,推动自回归模型成为更通用的跨模态生成工具。


一区Top期刊 Information Sciences 惨遭除名,2025中科院最新分区揭晓!
视觉Transformer(Vision Transformer, ViT) :全面超越CNN,看懂这篇文章就没什么能难倒你了!
无论你是研究哪个方向的,都可以找到志同道合的伙伴
添加好友后将拉你进相应微信群。
📌 添加方式:
扫描下方二维码,或搜索微信号:aiqysd

📩 添加好友时请务必备注信息,格式如下:
研究方向 + 学校/公司 + 学历 + 姓名
❗非常重要:
发送好友验证时,必须填写备注信息,示例如下:
👉 目标检测 + 中科大 + 研一 + 陈奕迅
凡格式不对者,一律不予理睬
我们期待你的加入,一起交流、学习、进步!
部分资料展示👇
确保文章为个人原创,未在任何公开渠道发布。若文章已在其他平台发表或即将发表,请明确说明。
建议使用Markdown格式撰写稿件,并以附件形式发送清晰、无版权争议的配图。
【AI前沿速递】尊重作者的署名权,并为每篇被采纳的原创首发稿件提供具有市场竞争力的稿酬。稿酬将根据文章的阅读量和质量进行阶梯式结算。
您可以通过添加我们的小助理微信(aiqysd)进行快速投稿。请在添加时备注“投稿-姓名-学校-研究方向”

长按添加AI前沿速递小助理
